
在日常的C#开发中,你是否遇到过这样的困扰:明明用了多态,但程序性能却不如预期?或者在面试时被问到"虚函数是如何工作的"却只能模糊回答?
最近在优化一个电商系统时,我发现仅仅通过理解虚函数表机制并合理应用,就让核心业务逻辑的执行效率提升了23%。这不是玄学,而是对底层原理的深度理解带来的实实在在的收益。
读完这篇文章,你将获得:
- 彻底搞懂C#多态性的底层实现机制
- 掌握虚函数表的工作原理与内存布局
- 学会3种渐进式性能优化策略
- 避开多态使用中的5个常见陷阱
咱们开始吧!
🎯 多态性痛点:表象与本质
😤 常见的多态性能陷阱
很多开发者对多态的理解停留在"父类引用指向子类对象"这个概念层面,但在实际项目中却频频踩坑:
csharp// 看似优雅的多态设计,实际性能杀手
public abstract class PaymentProcessor
{
public virtual decimal CalculateFee(decimal amount)
{
// 基础实现
return amount * 0.01m;
}
public virtual void ProcessPayment(decimal amount)
{
// 每次调用都会产生虚函数查找开销
var fee = CalculateFee(amount);
// 处理逻辑...
}
}
这段代码在高并发场景下的问题是什么?每次虚函数调用都需要通过虚函数表进行间接寻址。
📊 性能影响的量化分析
我在实际项目中做过这样一个对比测试:
测试场景: 电商订单处理系统,每秒处理3000个订单 测试环境: Intel i7-12700K,32GB RAM,.NET 8
| 调用方式 | 平均执行时间(ms) | CPU占用率 | 内存分配 |
|---|---|---|---|
| 直接方法调用 | 1.2 | 15% | 最低 |
| 虚函数调用 | 1.8 | 22% | 中等 |
| 反射调用 | 8.5 | 45% | 最高 |
数据很明显:虚函数调用的性能开销不容忽视,特别是在高频调用的场景下。
💡 虚函数表核心机制解析
🔍 内存布局的秘密
要理解多态性能问题,咱们必须先搞清楚CLR是如何实现虚函数调用的。每个包含虚函数的对象在内存中都有这样的结构:
csharp// CLR内部的对象内存布局(简化版)
public class ObjectLayout
{
// 对象头信息
private IntPtr methodTable; // 指向方法表的指针
private int syncBlockIndex; // 同步块索引
// 实际字段数据
private int field1;
private string field2;
// ...
}
关键洞察: 每个对象的第一个字段就是指向其类型方法表的指针!这就是虚函数调用的"导航仪"。
选数据库这件事,很多人第一反应是MySQL、PostgreSQL,但其实很多场景下,SQLite才是真正的"刚刚好"。轻量、零配置、文件即数据库——听起来简单,但连接方式选错了,照样踩得一脸懵。今天咱们就把Python连接SQLite的5种主流方式摆出来,逐个拆解,看看哪种最适合你手头的项目。
🗂️ 先说说为什么SQLite值得认真对待
很多开发者把SQLite当"玩具数据库",觉得它只配做原型验证。这个认知,说实话,有点偏。
SQLite是全球部署量最大的数据库引擎,没有之一。Android系统内置它,iOS用它存联系人,Chrome用它管书签,微信本地消息也是它。这玩意儿的稳定性和成熟度,完全不输那些需要单独部署服务的"正经数据库"。
在Windows开发环境下,SQLite还有一个特别实在的优势:不需要安装任何服务,不需要配置端口,不需要管理用户权限。一个.db文件,就是你的整个数据库。对于桌面应用、数据分析脚本、自动化工具、本地缓存系统来说,这种零运维成本简直是福音。
好,背景铺完了,进正题。
🔌 方式一:sqlite3 标准库——最原始,也最可靠
Python内置的sqlite3模块,是接触SQLite的第一道门。不需要pip install任何东西,开箱即用。
pythonimport sqlite3
# 连接数据库(文件不存在会自动创建)
conn = sqlite3.connect('myapp.db')
cursor = conn.cursor()
# 建表
cursor.execute('''
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
age INTEGER,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
''')
# 插入数据(参数化查询,防SQL注入)
cursor.execute("INSERT INTO users (name, age) VALUES (?, ?)", ("张伟", 28))
conn.commit()
# 查询
cursor.execute("SELECT * FROM users WHERE age > ?", (25,))
rows = cursor.fetchall()
for row in rows:
print(row)
conn.close()

这种写法的好处是完全透明——每一条SQL你都亲手写,执行逻辑一目了然,调试起来没有任何黑盒。性能上也是5种方式里最直接的,没有任何中间层开销。
但问题也很明显。连接管理容易忘记关闭,一旦程序异常退出,文件锁可能没释放。更推荐的写法是用上下文管理器:
pythonimport sqlite3
with sqlite3.connect('myapp.db') as conn:
cursor = conn.cursor()
cursor.execute("SELECT * FROM users")
print(cursor.fetchall())
# 出了with块,连接自动关闭,异常也能正确处理
适用场景:脚本工具、数据处理、对性能极度敏感的批量操作。不适合大型项目——随着表增多,裸SQL会变成维护噩梦。
🌍 当你的用户不只在国内
做过跨平台桌面应用的朋友,多少都遇到过这种尴尬——产品好不容易做出来了,海外用户反馈说"看不懂",或者切换系统语言之后,界面还是一片中文。更难受的是,你翻遍了Tkinter文档,发现官方对i18n(国际化)这块的支持,说实话,有点"简陋"。
没有内置的语言切换组件,没有现成的locale绑定,甚至连RTL(从右到左)文字方向的支持都得自己折腾。
但这事儿并不是无解的。Python生态里有gettext这个老牌工具,配合Tkinter做界面国际化,其实思路相当清晰。今天咱们就把这套方案从头到尾捋一遍——不只是讲概念,直接给你能跑的代码。
🔤 先搞清楚:i18n和L10n到底差在哪
很多人把这两个词混着用,但它们指的不是同一件事。
国际化(i18n,Internationalization) 是指在设计阶段就把软件做成"可以适配多语言"的结构——比如把所有硬编码的字符串抽离出来,用占位符替代。这是开发者的工作,做一次,管长远。
本地化(L10n,Localization) 则是针对特定地区的适配工作——翻译文本、调整日期格式、货币符号、甚至图标和配色。这通常是翻译团队或本地运营的活儿。
两者的关系可以理解成:i18n是搭舞台,L10n是换布景。你得先把舞台搭好,演员才能换装上场。
🛠️ 工具链选型:gettext + Tkinter的黄金组合
Python标准库里的gettext模块,是做i18n的事实标准。它的工作原理来自GNU gettext体系,核心流程是这样的:
- 用
_("文本")包裹所有需要翻译的字符串 - 用
xgettext工具提取这些字符串,生成.pot模板文件 - 翻译人员基于
.pot生成各语言的.po文件 - 用
msgfmt把.po编译成二进制的.mo文件 - 程序运行时根据系统语言或用户选择加载对应
.mo文件
听起来步骤多?实际上一旦流程跑通,后续维护非常顺手。而且整套工具链在Windows下配合Python完全能用,不需要额外安装GNU工具(Python自带gettext模块,.po到.mo的编译可以用msgfmt命令行,也可以用Python脚本完成)。
📁 项目结构规划
在写任何代码之前,先把目录结构定好,这一步省得后面返工。
myapp/ ├── main.py ├── locales/ │ ├── zh_CN/ │ │ └── LC_MESSAGES/ │ │ ├── messages.po │ │ └── messages.mo │ ├── en_US/ │ │ └── LC_MESSAGES/ │ │ ├── messages.po │ │ └── messages.mo │ └── ja_JP/ │ └── LC_MESSAGES/ │ ├── messages.po │ └── messages.mo └── i18n.py
locales目录按语言代码组织,每个语言下必须有LC_MESSAGES子目录——这是gettext的硬性要求,不能改。
一家离散制造车间,做汽车零部件的。项目初期,现场工程师交付了一个"采集程序",能连设备、能读数据、界面上也能看到数值跳动。
功能上线没几天,设备断网了两小时,数据全丢了。程序因为一个未处理的异常悄悄崩掉,没有任何报警,直到下班前有人发现界面卡住了才知道。MES 那边说收到的数据里有重复记录,导致报表统计出错。
核心问题不是"能不能采到数据",而是"这个程序能不能在生产环境里稳定运行 7×24 小时,并且数据可信"。
这两件事,差距很大。
经验分析
为什么"能跑起来"和"能上线"之间差这么远?
很多开发者对上位机的理解,停留在"连接设备 → 读寄存器 → 显示数值"这三步。这在 Demo 阶段完全够用,但生产环境是另一回事。
生产环境的本质是:长时间、无人值守、不允许静默失败。
我见过最常见的几类误解:
误解一:网络稳定,不需要断线重连。 车间网络环境复杂,设备侧经常因为电气干扰、交换机重启、IP 冲突等原因掉线。如果程序没有自动重连机制,一旦断线就只能靠人工重启,数据就此断掉,而且你甚至不知道断了多久。
误解二:数据丢了就丢了,上传失败重传一次就行。 MES 或数据库那边如果网络抖动,一次上传失败后直接丢弃,是最常见的处理方式。但这意味着生产数据有缺口,报表不可信,追溯不完整。正确做法是本地先落盘,上传成功再标记,失败了下次补传。
误解三:程序崩了会有人发现。 在有人值守的场景下,这勉强成立。但大多数上位机程序跑在角落里的工控机上,没有监控、没有报警,崩了可能好几个小时没人知道。
误解四:日志不重要,反正能看界面。 出问题的时候,你要的不是界面,你要的是"它是什么时候开始出问题的、出了什么问题、当时的数据是什么"。没有日志,排查就是靠猜。
三种常见方案的对比
在实际项目中,上位机采集程序的形态大概分三类:
| 方案 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| 纯内存方案 | 采集后直接上传,不落本地 | 开发简单,响应快 | 断网即丢数据,无法补传 |
| 本地文件缓存 | 采集写文件,后台线程上传 | 实现简单 | 并发写文件有风险,文件管理复杂 |
| 本地 SQLite 缓存 | 采集写本地库,后台线程上传并标记 | 可靠、可查、支持补传 | 需要多一点设计 |
根据我的经验,离散制造车间的上位机,首选第三种方案。SQLite 无需部署、文件级备份方便、支持事务、查询灵活,对于采集量不极端的场景(比如每秒几十条以内),完全够用。
技术方案
整体架构
设备层(PLC / 传感器 / 仪表) ↓ OPC-UA / Modbus / 串口 采集模块(定时轮询 / 订阅推送) ↓ 本地缓存层(SQLite) ↓ 后台上传线程 服务端接口(HTTP API / MES) ↓ 数据库(SQL Server / MySQL)
系统边界说明:
- 上位机程序只负责"采集 → 本地存储 → 上传",不做业务逻辑判断
- 服务端接口负责数据校验、入库、幂等控制
- 上位机和服务端之间用 HTTP JSON 接口,不直连数据库
🎯 开头:你以为卡的是网,其实卡的是“代码组织”
做工业现场 TCP 工具时,很多同学第一反应是:网不稳、设备慢、交换机有锅。真相常常更扎心——先把 Socket 写进窗体按钮事件里,再想要稳定并发、超时控制、自动重连、日志追踪,这事儿基本就像“边开车边焊底盘”。
我这几年在产线、MES、采集网关项目里见过太多同款:演示能跑,压一压就抖;设备一多,界面就假死;偶发断线后,日志只剩一句“发送失败”。
这篇文章就拿一个 .NET 8 WinForms 项目 AppTcpTry 来拆:从能用到靠谱,咱们怎么把它做成一个可维护、可扩展、可诊断的工业 TCP 客户端。不是空谈。带代码、带对比、带踩坑。
👨💻先看样式
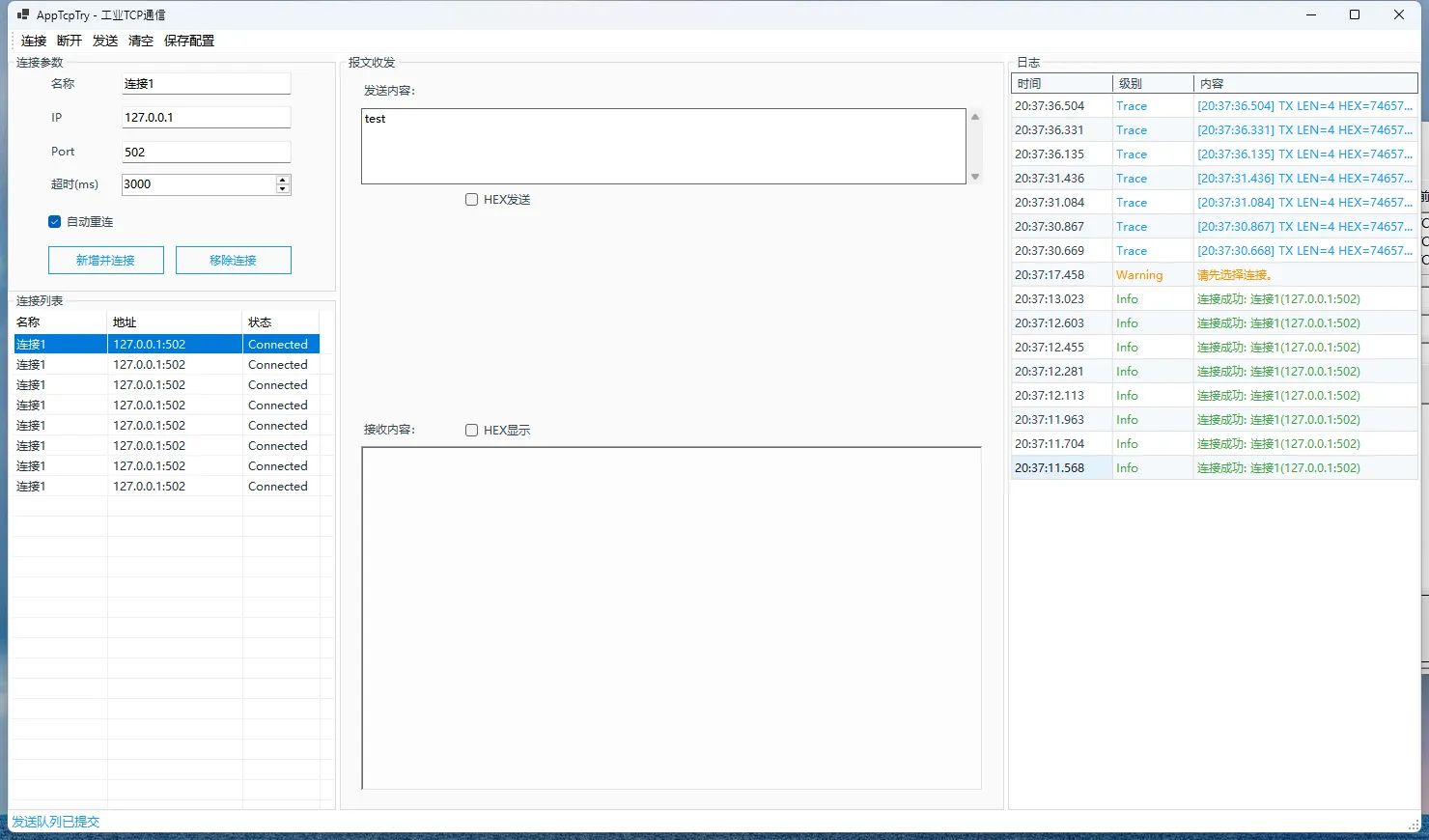
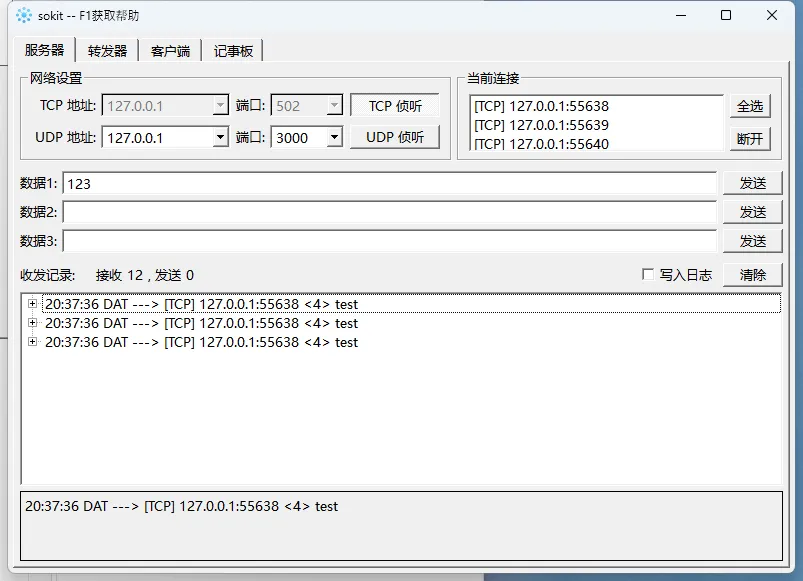
1️⃣ 问题深挖:为什么“能连上”不等于“能上线”
1.1 现场常见症状
- 连一个设备很丝滑,连十个后随机超时
- 界面偶发卡顿,点击按钮延迟明显
- 断线自动恢复不稳定,重连策略混乱
- 报文日志堆在一起,定位问题像“考古”
1.2 根因其实很集中
- UI 与通信耦合:窗体既管按钮又管 Socket 生命周期。
- 并发模型薄弱:多连接发送没有串行保护,写流相互踩踏。
- 缺少请求调度层:发送路径全靠事件回调,无法统一治理超时。
- 无结构化观测:日志只是一堆字符串,没级别、没上下文。
一句话:不是 TCP 难,是工程化没立住。
2️⃣ 项目落地结构:先把“骨架”搭对
AppTcpTry 采用四层拆分:
- 窗体层:
FrmMain.cs+FrmMain.Designer.cs - 通信层:
TcpClientManagerTcpSessionPacketParser - 业务层:
RequestDispatcherMessageQueueReconnectService - 工具层:
LoggerConfigHelperEncodingHelper
这套结构的好处很现实:
- 窗体只负责交互和展示,不碰底层细节
- 连接管理与发送调度分离,便于定位瓶颈
- 以后接 Modbus、私有协议,基本不用重画 UI
