
目录
一家离散制造车间,做汽车零部件的。项目初期,现场工程师交付了一个"采集程序",能连设备、能读数据、界面上也能看到数值跳动。
功能上线没几天,设备断网了两小时,数据全丢了。程序因为一个未处理的异常悄悄崩掉,没有任何报警,直到下班前有人发现界面卡住了才知道。MES 那边说收到的数据里有重复记录,导致报表统计出错。
核心问题不是"能不能采到数据",而是"这个程序能不能在生产环境里稳定运行 7×24 小时,并且数据可信"。
这两件事,差距很大。
经验分析
为什么"能跑起来"和"能上线"之间差这么远?
很多开发者对上位机的理解,停留在"连接设备 → 读寄存器 → 显示数值"这三步。这在 Demo 阶段完全够用,但生产环境是另一回事。
生产环境的本质是:长时间、无人值守、不允许静默失败。
我见过最常见的几类误解:
误解一:网络稳定,不需要断线重连。 车间网络环境复杂,设备侧经常因为电气干扰、交换机重启、IP 冲突等原因掉线。如果程序没有自动重连机制,一旦断线就只能靠人工重启,数据就此断掉,而且你甚至不知道断了多久。
误解二:数据丢了就丢了,上传失败重传一次就行。 MES 或数据库那边如果网络抖动,一次上传失败后直接丢弃,是最常见的处理方式。但这意味着生产数据有缺口,报表不可信,追溯不完整。正确做法是本地先落盘,上传成功再标记,失败了下次补传。
误解三:程序崩了会有人发现。 在有人值守的场景下,这勉强成立。但大多数上位机程序跑在角落里的工控机上,没有监控、没有报警,崩了可能好几个小时没人知道。
误解四:日志不重要,反正能看界面。 出问题的时候,你要的不是界面,你要的是"它是什么时候开始出问题的、出了什么问题、当时的数据是什么"。没有日志,排查就是靠猜。
三种常见方案的对比
在实际项目中,上位机采集程序的形态大概分三类:
| 方案 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| 纯内存方案 | 采集后直接上传,不落本地 | 开发简单,响应快 | 断网即丢数据,无法补传 |
| 本地文件缓存 | 采集写文件,后台线程上传 | 实现简单 | 并发写文件有风险,文件管理复杂 |
| 本地 SQLite 缓存 | 采集写本地库,后台线程上传并标记 | 可靠、可查、支持补传 | 需要多一点设计 |
根据我的经验,离散制造车间的上位机,首选第三种方案。SQLite 无需部署、文件级备份方便、支持事务、查询灵活,对于采集量不极端的场景(比如每秒几十条以内),完全够用。
技术方案
整体架构
设备层(PLC / 传感器 / 仪表) ↓ OPC-UA / Modbus / 串口 采集模块(定时轮询 / 订阅推送) ↓ 本地缓存层(SQLite) ↓ 后台上传线程 服务端接口(HTTP API / MES) ↓ 数据库(SQL Server / MySQL)
系统边界说明:
- 上位机程序只负责"采集 → 本地存储 → 上传",不做业务逻辑判断
- 服务端接口负责数据校验、入库、幂等控制
- 上位机和服务端之间用 HTTP JSON 接口,不直连数据库
本地缓存表结构设计
本地 SQLite 只需要一张核心表 device_data_cache:
| 字段名 | 类型 | 说明 |
|---|---|---|
id | INTEGER PRIMARY KEY AUTOINCREMENT | 本地自增主键 |
device_code | TEXT NOT NULL | 设备编码 |
tag_name | TEXT NOT NULL | 采集点位名称 |
tag_value | TEXT NOT NULL | 采集值(统一用文本存储) |
collected_at | TEXT NOT NULL | 采集时间(ISO8601格式) |
uploaded | INTEGER NOT NULL DEFAULT 0 | 上传状态:0=未上传,1=已上传 |
uploaded_at | TEXT | 上传成功时间 |
retry_count | INTEGER NOT NULL DEFAULT 0 | 重试次数 |
created_at | TEXT NOT NULL | 记录创建时间 |
sqlCREATE TABLE IF NOT EXISTS device_data_cache (
id INTEGER PRIMARY KEY AUTOINCREMENT,
device_code TEXT NOT NULL,
tag_name TEXT NOT NULL,
tag_value TEXT NOT NULL,
collected_at TEXT NOT NULL,
uploaded INTEGER NOT NULL DEFAULT 0,
uploaded_at TEXT,
retry_count INTEGER NOT NULL DEFAULT 0,
created_at TEXT NOT NULL
);
-- 查询未上传数据时的性能索引
CREATE INDEX IF NOT EXISTS idx_uploaded ON device_data_cache(uploaded, collected_at);
tag_value统一用 TEXT 存储是个实用技巧。不同设备、不同点位的值类型可能是整数、浮点、布尔、字符串,统一用文本存储可以避免建多张表或频繁改表结构,服务端再做类型转换。
关键模块设计
采集模块应该是独立的定时任务,每个设备一个采集周期配置,互不干扰。采集到数据后,立即写入本地 SQLite,写入成功才算一次完整采集。
上传模块是一个后台常驻线程,每隔固定时间(比如5秒)查询 uploaded = 0 的记录,批量打包上传,上传成功后更新 uploaded = 1 和 uploaded_at。
重连模块负责监控设备连接状态,断线后按指数退避策略重试,避免频繁重连打爆日志。
看门狗模块是一个独立的定时检查,确认采集线程和上传线程是否还在正常工作,如果超过一定时间没有新数据写入,触发报警(写日志 + 可选弹窗提示)。
代码与示例
注意:示例代码没有具体实现数据采集这块,这块比较容易,示例主要体现设计思路,采集这块做了一个简单的仿真。
本地缓存写入
csharpusing System;
using System.Collections.Generic;
using System.Linq;
using System.Net.Http;
using System.Text;
using System.Text.Json;
using System.Threading;
using AppDeviceCollector.Helpers;
using Timer = System.Threading.Timer;
namespace AppDeviceCollector.Services
{
/// <summary>
/// 后台上传模块:独立线程,每隔固定时间批量上传待传记录
/// </summary>
public class UploadService
{
private readonly LocalCacheService _cache;
private readonly string _apiUrl;
private readonly int _intervalMs;
private Timer _timer;
private bool _running;
private int _uploadSuccess;
private int _uploadFail;
private static readonly HttpClient _http = new HttpClient
{
Timeout = TimeSpan.FromSeconds(10)
};
public bool IsRunning => _running;
public int UploadSuccess => _uploadSuccess;
public int UploadFail => _uploadFail;
public DateTime LastUploadTime { get; private set; }
public event Action<int> OnUploaded; // 参数:本次成功条数
public UploadService(
LocalCacheService cache,
string apiUrl,
int intervalMs = 5000)
{
_cache = cache;
_apiUrl = apiUrl;
_intervalMs = intervalMs;
}
public void Start()
{
if (_running) return;
_running = true;
_timer = new Timer(DoUpload, null, 1000, _intervalMs);
AppLogger.Instance.Info($"[上传] 上传服务已启动,目标: {_apiUrl},间隔 {_intervalMs}ms");
}
public void Stop()
{
if (!_running) return;
_running = false;
_timer?.Dispose();
_timer = null;
AppLogger.Instance.Info("[上传] 上传服务已停止");
}
private void DoUpload(object state)
{
if (!_running) return;
try
{
var pending = _cache.GetPending(100);
if (pending.Count == 0) return;
// 序列化为 JSON
var payload = JsonSerializer.Serialize(pending.Select(r => new
{
device_code = r.DeviceCode,
tag_name = r.TagName,
tag_value = r.TagValue,
collected_at = r.CollectedAt.ToUniversalTime().ToString("o")
}));
var content = new StringContent(
payload, Encoding.UTF8, "application/json");
// 实际上传(模拟:如果 URL 为空则视为成功)
bool success;
if (string.IsNullOrWhiteSpace(_apiUrl) ||
_apiUrl == "http://localhost/api/data")
{
// 模拟成功
Thread.Sleep(50);
success = true;
}
else
{
var resp = _http.PostAsync(_apiUrl, content).GetAwaiter().GetResult();
success = resp.IsSuccessStatusCode;
}
var ids = pending.Select(r => r.Id).ToList();
if (success)
{
_cache.MarkUploaded(ids);
Interlocked.Add(ref _uploadSuccess, pending.Count);
LastUploadTime = DateTime.Now;
AppLogger.Instance.Info(
$"[上传] 成功上传 {pending.Count} 条,累计 {_uploadSuccess} 条");
OnUploaded?.Invoke(pending.Count);
}
else
{
_cache.IncrementRetry(ids);
Interlocked.Add(ref _uploadFail, pending.Count);
AppLogger.Instance.Warn(
$"[上传] 上传失败,{pending.Count} 条重试次数+1,累计失败 {_uploadFail} 条");
}
}
catch (Exception ex)
{
AppLogger.Instance.Error("[上传] 上传异常", ex);
}
}
}
}
retry_count < 5这个限制很重要。如果某条记录因为数据格式问题导致服务端一直拒绝,没有这个上限,上传线程会永远卡在这条记录上,影响后续正常数据的上传。超过重试上限的记录可以单独记录到错误日志,人工介入处理。
看门狗
c#using System;
using System.Threading;
using AppDeviceCollector.Helpers;
using Timer = System.Threading.Timer;
namespace AppDeviceCollector.Services
{
/// <summary>
/// 看门狗:定期检查采集/上传线程健康状态
/// 超过阈值无新数据时触发报警
/// </summary>
public class WatchdogService
{
private readonly CollectorService _collector;
private readonly UploadService _uploader;
private readonly int _checkIntervalMs;
private readonly int _maxSilenceMs; // 最长允许无采集时间
private Timer _timer;
private bool _running;
public event Action<string> OnAlarm; // 报警事件
public WatchdogService(
CollectorService collector,
UploadService uploader,
int checkIntervalMs = 10000,
int maxSilenceMs = 30000)
{
_collector = collector;
_uploader = uploader;
_checkIntervalMs = checkIntervalMs;
_maxSilenceMs = maxSilenceMs;
}
public void Start()
{
if (_running) return;
_running = true;
_timer = new Timer(DoCheck, null, _checkIntervalMs, _checkIntervalMs);
AppLogger.Instance.Info("[看门狗] 已启动");
}
public void Stop()
{
if (!_running) return;
_running = false;
_timer?.Dispose();
AppLogger.Instance.Info("[看门狗] 已停止");
}
private void DoCheck(object state)
{
if (!_running) return;
// 检查采集是否存活
if (_collector.IsRunning)
{
var silence = (DateTime.Now - _collector.LastCollectTime).TotalMilliseconds;
if (_collector.CollectCount > 0 && silence > _maxSilenceMs)
{
var msg = $"[看门狗] 警告:采集线程 {_collector.DeviceCode} " +
$"已 {silence / 1000:F0}s 无新数据!";
AppLogger.Instance.Warn(msg);
OnAlarm?.Invoke(msg);
}
}
// 检查上传服务
if (_uploader.IsRunning && _uploader.UploadSuccess > 0)
{
var silence = (DateTime.Now - _uploader.LastUploadTime).TotalMilliseconds;
if (silence > _maxSilenceMs * 2)
{
var msg = $"[看门狗] 警告:上传服务已 {silence / 1000:F0}s 无成功上传!";
AppLogger.Instance.Warn(msg);
OnAlarm?.Invoke(msg);
}
}
AppLogger.Instance.Info(
$"[看门狗] 心跳检查 OK — 采集次数:{_collector.CollectCount} " +
$"上传成功:{_uploader.UploadSuccess} 上传失败:{_uploader.UploadFail}");
}
}
}
运行效果
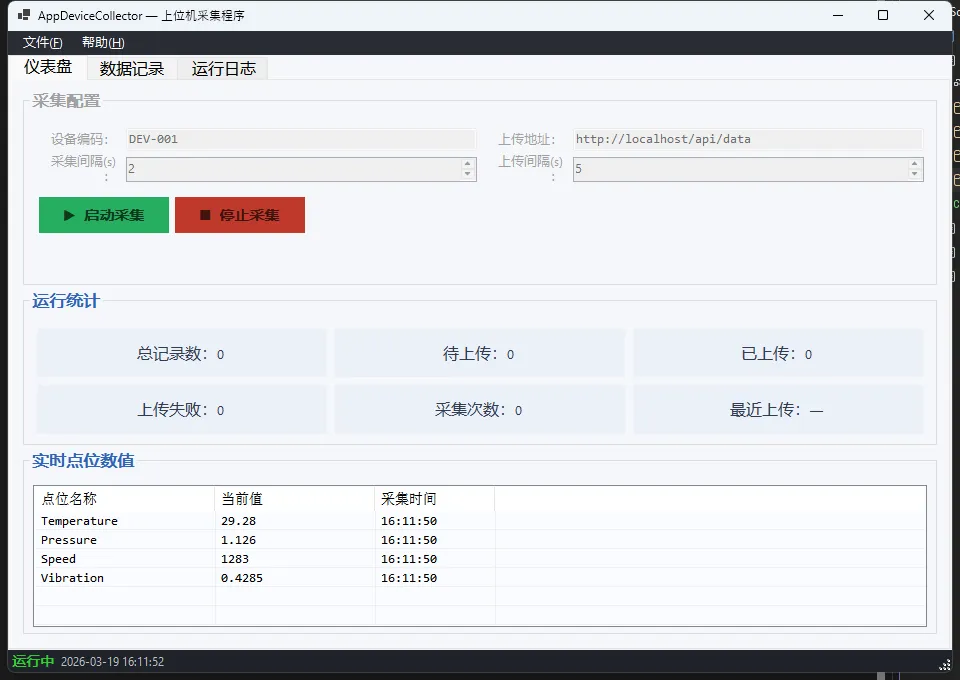
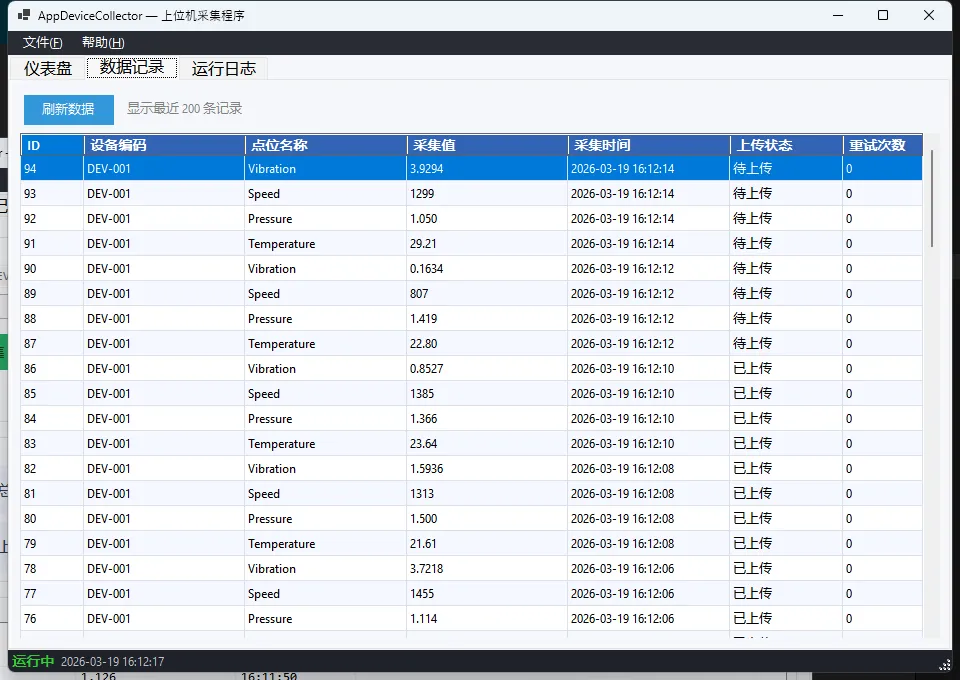
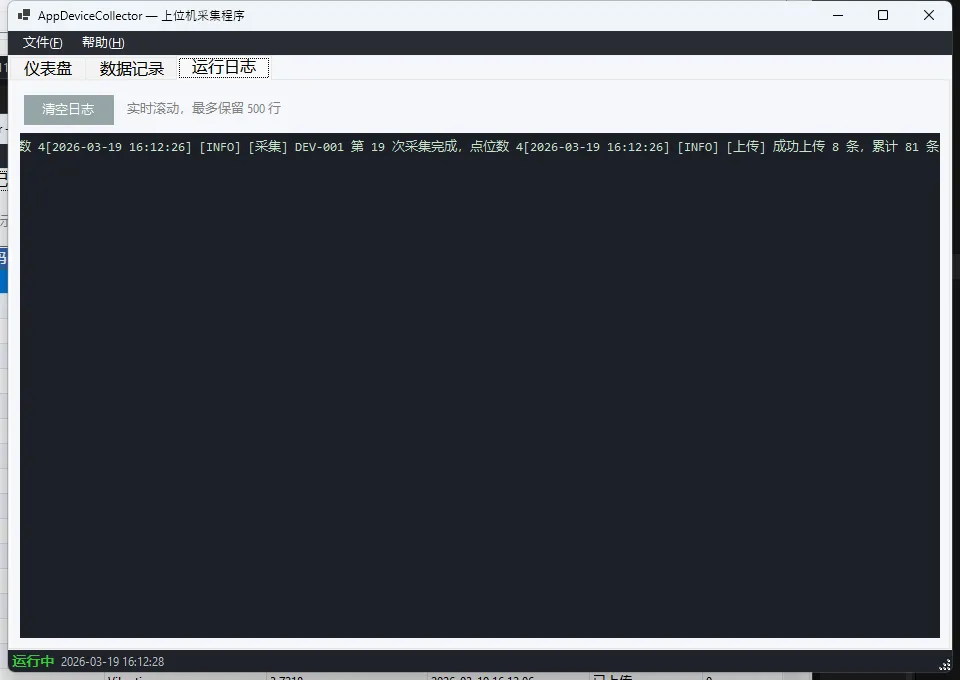
经验总结
可直接拿去用的要点
-
本地先落盘,上传后再标记。 不要直接上传,网络不可信,本地 SQLite 是你的第一道保险。
-
上传模块和采集模块要分离。 两个独立线程,互不阻塞。采集慢不影响上传,上传卡住不影响采集。
-
接口设计要幂等。 服务端接口用
device_code + tag_name + collected_at作为唯一键,重复上传不会产生重复记录。 -
日志要有时间戳和上下文。 每条日志至少包含:时间、设备编码、操作类型、结果。出问题时你会感谢自己。
-
看门狗不是可选项。 程序崩了你不一定知道,看门狗是你在无人值守环境下的眼睛。
常见坑与避免建议
-
坑1:直接用
DateTime.Now存时间。 建议统一用 UTC 时间(DateTime.UtcNow)存储,显示时再转本地时间,避免跨时区或夏令时问题在数据里留下隐患,这是一个巨大的坑。 -
坑2:采集周期和上传周期耦合。 有人把采集和上传写在同一个定时器里,采集一次就上传一次。网络一抖,采集也跟着停。务必分离。
-
坑3:SQLite 多线程写入不加锁。 SQLite 默认不支持多线程并发写,如果采集线程和上传线程都在写同一个库,要么加锁,要么用连接池配置
Pooling=True,否则会出现数据库锁定异常。 -
坑4:
tag_value存了原始寄存器值,没有单位和换算说明。 后续对接 MES 或做报表时,没有人知道这个值代表什么。建议在配置文件里记录点位的工程量换算关系。 -
坑5:程序以 Debug 模式部署。 上线时记得切换为 Release 编译,关闭调试日志级别,否则日志文件会以惊人的速度把磁盘写满。
下一步行动建议
如果你现在手上有一个上位机项目,可以对照这个清单快速自查:
- 采集数据是否有本地缓存,断网后能否补传?
- 程序崩溃后是否有自动重启机制(Windows 服务 / 任务计划)?
- 是否有结构化日志,能定位到具体设备和时间点?
- 上传接口是否设计了幂等,重复数据不会入库两次?
- 是否有看门狗或心跳监控,能感知程序异常停止?
这五条,是一个上位机程序能不能真正上线的底线。
完整示例代码我整理在一个示例项目中,方便大家对照学习和实践。
你在项目里遇到过类似问题吗?欢迎在评论区分享你的做法,或者补充你认为还缺少的关键模块。
相关信息
通过网盘分享的文件:AppDeviceCollector.zip 链接: https://pan.baidu.com/s/17_FTr0iPzNSUk9WqZqhT7Q?pwd=vp5p 提取码: vp5p --来自百度网盘超级会员v9的分享
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!