Python定时任务神器:schedule库入门实战指南
在日常的Python开发中,我们经常需要让程序在特定时间执行某些任务:每天早上8点发送邮件提醒、每隔30分钟检查服务器状态、每周清理一次临时文件等等。虽然Windows有任务计划程序,Linux有cron,但作为Python开发者,我们更希望用纯Python的方式来解决这个问题。
schedule库就是为此而生的轻量级定时任务解决方案。它语法简洁、易于理解,特别适合Python初学者和中小型项目使用。本文将带你从零开始掌握schedule库,让你的Python程序拥有"时间感知"的能力。
📋 问题分析
🤔 为什么需要定时任务?
在实际的Python开发中,我们经常遇到这样的场景:
- 数据采集:定期爬取网站数据、API调用
- 系统监控:定时检查服务状态、资源使用情况
- 文件处理:定期清理日志、备份数据
- 消息推送:定时发送邮件、微信通知
- 上位机开发:定期读取设备数据、状态检查
💭 传统解决方案的痛点
Windows任务计划程序:
- 配置复杂,需要通过GUI操作
- 难以与Python程序集成
- 调试困难,错误信息不直观
time.sleep()循环:
pythonimport time
while True:
# 执行任务
do_something()
time.sleep(3600) # 休眠1小时
- 不够灵活,难以实现复杂的时间规则
- 程序阻塞,无法处理其他逻辑
- 时间精度问题,容易产生累积误差
💡 解决方案:schedule库
🚀 安装与基本使用
安装命令:
bashpip install schedule
基本语法结构:
pythonimport schedule
def job():
print("任务执行中...")
# 设置定时任务
schedule.every(10).seconds.do(job)
schedule.every().hour.do(job)
schedule.every().day.at("09:00").do(job)
# 保持程序运行
while True:
schedule.run_pending()
time.sleep(1)
大模型硬件选型指南:从CPU到TPU的实战策略
大模型硬件选型远不止是"买最贵的"这么简单,它更像一场精心策划的烹饪艺术——不同食材需要不同的处理方式,而硬件就像厨房里的各种工具,必须根据任务需求精准匹配。从DeepSeek-R1的1.5B轻量版到671B的"巨无霸",硬件需求天差地别,选择不当可能导致模型加载缓慢、推理延迟高企,甚至根本无法运行。
🔥 硬件选型的三大陷阱与真实痛点
陷阱一:显存越大越好? 这是最常见的误区,许多用户为7B模型购买80GB显存的A100,结果发现性能提升有限,成本却高出10倍。显存确实是关键瓶颈,但盲目追求大显存就像买了一座豪华厨房却只用来煮泡面,资源严重浪费。
陷阱二:忽略CPU与内存协同。GPU虽是主力,但CPU负责数据预处理、任务调度这些"幕后工作"。实测显示,CPU推理耗时2.3秒,而GPU仅需28毫秒,若CPU性能不足,整体效率可能下降50%以上。更令人担忧的是,内存容量不足会导致模型加载缓慢,甚至崩溃。
陷阱三:TPU生态锁。TPU虽在谷歌生态内性能优异,但需依赖TensorFlow框架和谷歌云平台,跨平台兼容性差。非谷歌用户使用TPU需转换框架,可能导致开发周期延长或代码重构成本增加。
这些误区造成的实际后果不容忽视:某用户为DeepSeek-R1的7B版本购买了RTX 4090(24GB显存),结果发现性能提升有限,成本却高出10倍;另一用户仅关注GPU而忽视CPU和内存,导致系统整体性能下降50%以上;还有用户尝试在本地部署TPU,最终因生态不兼容而失败。
💡 大模型硬件架构的三大核心处理器
🎯 CPU:大模型的"指挥官"
CPU就像厨房里的"指挥官",负责统筹整个烹饪过程。虽然它处理单个任务的速度快,但并行能力有限。在大模型训练中,CPU主要负责数据预处理、任务调度和少量推理工作。选择CPU时,需关注核心数、内存带宽和是否支持AVX2/AVX-512指令集——这些直接影响模型加载速度和预处理效率。
以DeepSeek-R1的1.5B版本为例,它可以在现代CPU(如Intel i5或AMD Ryzen 7)上流畅运行,无需独立显卡。这是因为CPU的通用性足以处理小规模模型的推理需求,但若进行训练,则效率会大幅下降。
🔥 GPU:大模型训练的"蜂群"
GPU则像厨房里的"蜂群",数千个简化核心协同工作,专注于高吞吐量计算。NVIDIA的GPU在大模型训练领域占据主导地位,因其支持CUDA生态和丰富的AI加速功能。2025年最新的B200 GPU采用Blackwell架构,FP8算力达10 PFlops,支持液冷散热,可将ChatGPT训练能耗从15兆瓦降至4兆瓦。
GPU特别适合处理矩阵运算,这是大模型训练的核心任务。DeepSeek-R1的7B版本需要至少8GB显存的GPU(如RTX 3060),而32B版本则需要多张A100(80GB显存/卡)。GPU的灵活性使其成为科研机构和中小企业的首选,但高功耗和成本也是不容忽视的挑战。
🚀 TPU:谷歌的"定制化工厂"
TPU是谷歌的"秘密武器",专为AI设计的ASIC芯片,就像高度自动化的"定制化工厂"。TPU在矩阵运算上比GPU快180%,但软硬件生态封闭,仅限谷歌云平台使用。TPU v5p的BF16算力达459 TFlops,Int8下918 TOPS,集成HBM3内存,训练GPT-3-175B速度提升180%。
TPU的优势在于极致的能效比和规模扩展能力,但它的缺点也很明显:仅支持TensorFlow框架,无法在本地部署,且需额外支付谷歌云服务费用。除非你是谷歌生态深度用户,否则TPU的使用门槛较高。
就在上个月,这个火的不行,问题好像前几天NVIDIA 反手收购了TPU之父。

Python集合(set):数据去重与高效集合运算的必备利器
在Python开发中,你是否遇到过这些场景:需要快速去除列表中的重复数据?想要找出两个数据集的交集或差集?需要判断某个元素是否存在于大量数据中?这些问题的最优解答案都指向同一个数据结构——集合(set)。
本文将深入剖析Python集合的核心特性,包括自动去重机制、四大集合运算(并集、交集、差集、对称差集)以及无序特性的本质。通过丰富的代码实战案例,帮助你掌握这个在数据处理、算法优化中不可或缺的数据结构,让你的Python开发效率提升一个档次。
🔍 集合的本质:无序且唯一的数据容器
什么是集合?
集合(set)是Python内置的一种无序、不重复的数据类型,底层基于哈希表实现。这意味着:
- 元素唯一性:自动过滤重复元素
- 无序性:不保证元素的存储顺序
- 高效查询:成员检测速度极快(O(1)时间复杂度)
python# 创建集合的三种方式
# 创建集合的三种方式
set1 = {1, 2, 3, 4, 5} # 使用花括号
set2 = set([1, 2, 2, 3, 4, 4, 5]) # 从列表创建(自动去重)
set3 = set("hello") # 从字符串创建
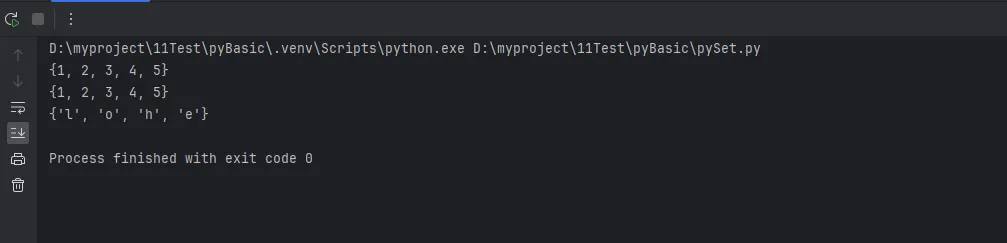
print(set1)
print(set2)
print(set3)
⚠️ 重要特性说明
python# 1. 集合元素必须是可哈希的(不可变类型)
valid_set = {1, 'python', (1, 2), 3.14} # ✅ 正确
# invalid_set = {[1, 2], {3, 4}} # ❌ 错误:列表和集合不可哈希
# 2. 空集合必须用set()创建
empty_set = set() # ✅ 正确
empty_dict = {} # ❌ 这是空字典,不是空集合
# 3. 无序性演示
numbers = {5, 1, 9, 3, 7}
print(numbers)
作为Python开发者,数据可视化是我们日常工作中不可或缺的技能。无论是分析业务数据、展示项目成果,还是进行科学计算,Matplotlib都是我们的得力助手。但你是否曾经为plot()函数的各种参数而困惑?为什么同样的数据,别人画出的图表就是比你的更专业、更美观?
今天这篇文章将彻底解决这些问题。我们将从plot()函数的核心参数开始,深入讲解线条样式、颜色设置、标记符号的使用技巧,掌握多条曲线的绘制方法,最后通过实战案例绘制数学函数图像。让你的数据可视化技能从此脱胎换骨!
🔍 plot()函数核心参数解析
基础语法结构
Pythonimport matplotlib.pyplot as plt
import numpy as np
# 基础语法
plt.plot(x, y, format_string, **kwargs)
plot()函数的核心在于理解其参数结构:
- x, y:数据点的坐标
- format_string:格式化字符串,控制线条样式
- kwargs:关键字参数,提供更精细的控制
🎨 线条样式与颜色大全
线条样式参数详解
Pythonimport matplotlib.pyplot as plt
import numpy as np
# 设置中文字体支持
# Windows下的字体和显示优化
plt.rcParams['font.sans-serif'] = ['SimHei','Microsoft YaHei'] # 支持中文显示
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
plt.rcParams['figure.autolayout'] = True # 自动调整布局
plt.rcParams['savefig.dpi'] = 300 # 默认保存分辨率
# 使用标准后端而不是PyCharm的后端
import matplotlib
matplotlib.use('TkAgg')
# 生成示例数据
x = np.linspace(0, 10, 100)
y1 = np.sin(x)
y2 = np.cos(x)
y3 = np.sin(x + np.pi/4)
# 创建子图展示不同线条样式
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
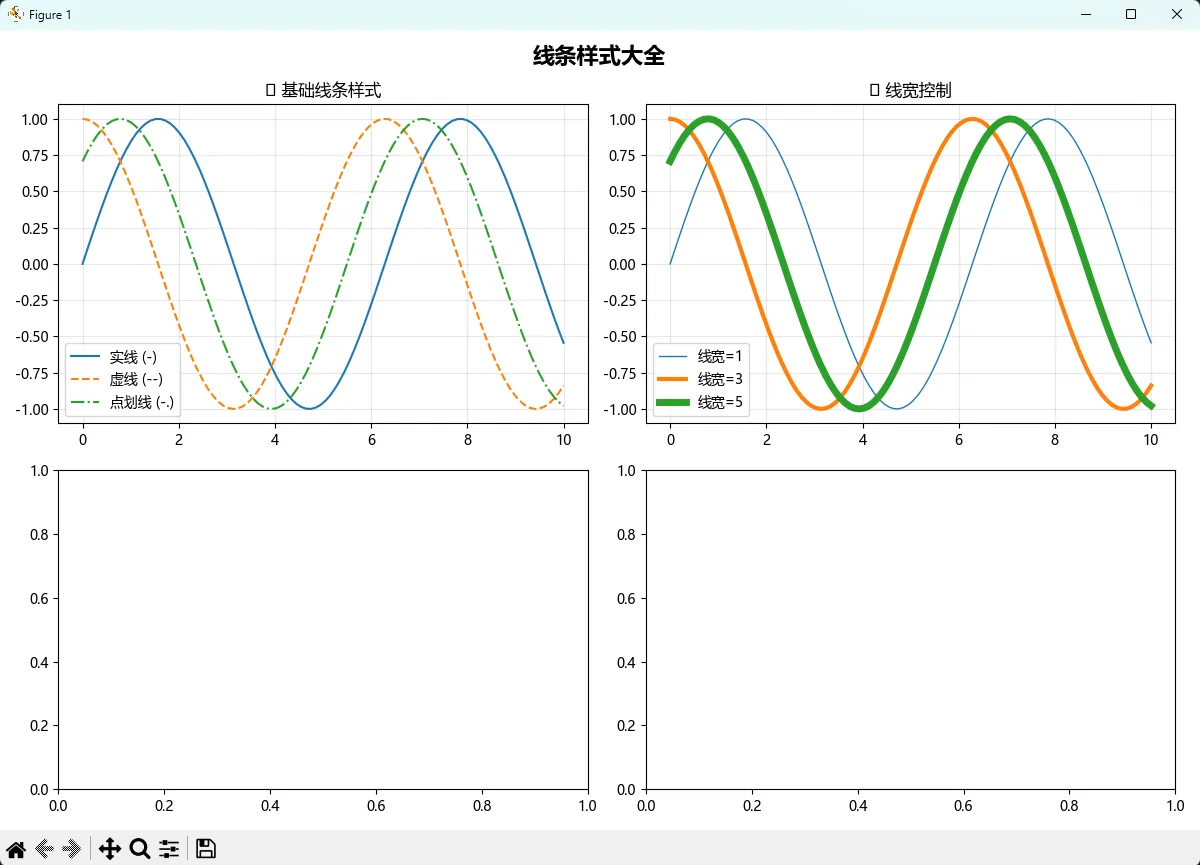
fig.suptitle('线条样式大全', fontsize=16, fontweight='bold')
# 实线样式
axes[0,0].plot(x, y1, '-', label='实线 (-)')
axes[0,0].plot(x, y2, '--', label='虚线 (--)')
axes[0,0].plot(x, y3, '-.', label='点划线 (-.)')
axes[0,0].set_title('🔥 基础线条样式')
axes[0,0].legend()
axes[0,0].grid(True, alpha=0.3)
# 线宽控制
axes[0,1].plot(x, y1, linewidth=1, label='线宽=1')
axes[0,1].plot(x, y2, linewidth=3, label='线宽=3')
axes[0,1].plot(x, y3, linewidth=5, label='线宽=5')
axes[0,1].set_title('📏 线宽控制')
axes[0,1].legend()
axes[0,1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
在Windows系统下的Python开发中,串口通信是连接物理设备与软件系统的重要桥梁。无论你是在开发工业自动化系统、物联网项目,还是需要与单片机、传感器进行数据交换,掌握Python串口通信技术都是必不可少的技能。
本文将通过一个完整的串口通信工具案例,带你深入理解从基础连接到高级数据处理的全套解决方案。我们不仅要实现基本的数据收发功能,还要处理异步通信、协议解析、日志记录等实战中的关键问题,让你的Python上位机开发能力更上一层楼。
🔍 串口通信的核心挑战分析
问题一:阻塞式通信影响用户体验
传统的串口读取是阻塞式的,会导致界面卡顿,用户体验极差。特别是在需要持续接收数据的场景下,如何保证界面响应性是首要问题。
问题二:数据包边界处理复杂
实际应用中,串口数据往往不是完整的数据包,需要处理数据粘包、分包等情况,如何正确解析协议数据是技术难点。
问题三:错误处理和资源管理
设备断开、端口占用、读写异常等错误情况频发,需要完善的异常处理机制和资源清理策略。
🚀 现代化解决方案架构
🏗️ 分层架构设计
我们采用分层架构来解决上述问题:
Python# 配置层:统一管理连接参数
class SerialConfig:
def __init__(self, port, baudrate):
self.port = port
self.baudrate = baudrate
设计亮点:将配置独立成类,便于扩展更多参数(如数据位、停止位等),也方便配置的序列化保存。
⚡ 异步处理核心引擎
Pythonclass AsyncSerialHandler:
def __init__(self, config: SerialConfig):
self.config = config
self.serial = None
self.is_connected = False
# 关键:使用回调机制解耦UI和通信逻辑
self.on_data_received = None
self.on_error = None
self.on_connection_changed = None
self.tx_bytes = 0
self.rx_bytes = 0
self.read_task = None
核心技巧:
- 回调函数设计:通过
on_data_received等回调函数,实现通信层与UI层的完全解耦 - 统计功能内置:直接在处理器中维护收发字节统计,避免外部重复计算
- 任务管理:使用
read_task管理异步读取任务的生命周期
