
你是否在多线程开发中遇到过这样的问题:明明做了100万次计数,结果却少了几千个? 或者为了保证线程安全而使用了太多lock,导致程序性能大幅下降?
在高并发场景下,传统的锁机制往往成为性能瓶颈,而竞态条件又让程序行为变得不可预测。今天我们来深入探讨.NET中的Interlocked类——一个被低估但极其强大的无锁线程安全解决方案。
掌握Interlocked,让你的多线程程序既安全又高效!
🔥 问题分析:多线程编程的痛点
竞态条件的陷阱
在多线程环境中,当多个线程同时访问共享变量时,就会出现竞态条件:
C#// 危险的计数器实现
public class UnsafeCounter
{
private static int _counter = 0;
public static void Increment()
{
// 这里存在竞态条件!
_counter++; // 读取->增加->写回
}
}
问题所在:_counter++看似简单,实际包含读取、增加、写回三个步骤,多线程同时执行时会相互覆盖。
传统锁的性能代价
使用lock虽然能解决线程安全问题,但也带来了额外开销:
C#// 性能较差的同步方案
public class LockedCounter
{
private static int _counter = 0;
private static readonly object _lock = new object();
public static void Increment()
{
lock (_lock) // 每次都要获取锁,性能开销大
{
_counter++;
}
}
}
你是否曾经因为找不到占用大量资源的进程而苦恼?或者想要实时监控某个重要服务的运行状态?作为C#开发者,我们完全可以自己动手打造一个功能强大的系统监控工具。今天就带你一步步构建一个基于WPF和WMI的专业级系统监控应用,让你的程序拥有"透视"整个系统的能力!
这不仅仅是一个简单的Demo,而是一个可以直接投入生产使用的完整解决方案。从界面设计到核心功能,从性能优化到异常处理,我们都会详细讲解。
🎯 为什么需要自建监控工具?
现有工具的痛点
- 任务管理器:功能单一,无法自定义监控逻辑
- 第三方工具:收费昂贵,或者功能过于复杂
- 系统自带工具:界面老旧,不够直观
自建工具的优势
- 完全可控:根据业务需求定制功能
- 深度集成:与现有系统完美结合
- 学习价值:深入理解系统底层机制
🏗️ 整体架构设计
我们的监控工具采用MVVM模式,主要包含以下核心模块:
Markdown📦 AppWmiSystemMonitor ├── 🎨 UI层 (WPF界面) ├── 🧠 业务逻辑层 (进程监控、数据处理) ├── 🔌 数据访问层 (WMI接口) └── 📊 数据模型层 (实体类定义)
在实际的C#企业级开发中,这个也是在最初版本中加上了事件的特性处理,你是否遇到过这些让人头疼的配置管理问题:配置文件散落各处难以统一管理、配置变更需要重启应用、缺乏有效的配置验证机制?今天我将和大家分享一个基于注解(Attribute)的配置管理解决方案,它不仅能够优雅地解决上述痛点,还能让你的代码变得更加专业和可维护。
🤔 传统配置管理的痛点分析
配置分散难管理
传统的配置管理往往将配置信息散布在多个地方:appsettings.json、环境变量、数据库等,开发者需要记住各种配置项的位置和格式,维护成本极高。
缺乏类型安全
直接使用字符串键值对读取配置,容易出现拼写错误,且IDE无法提供智能提示,调试困难。
验证机制不完善
配置项的有效性验证往往散落在业务代码中,缺乏统一的验证机制,容易遗漏关键验证逻辑。
💡 基于注解的解决方案
🎯 设计思路
我们的解决方案采用了约定优于配置的设计理念,通过自定义注解来声明配置类的行为,实现了:
- 声明式配置:通过注解明确配置类的意图
- 自动映射:配置文件到对象的自动映射
- 生命周期管理:完整的初始化、验证、变更监听流程
- 热重载支持:配置文件变更时自动重载
🐒 基本流程
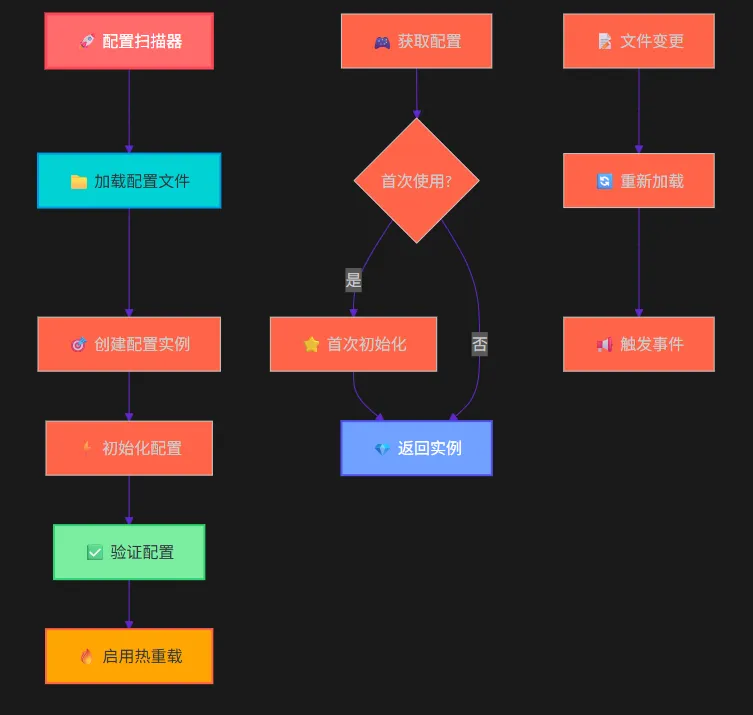
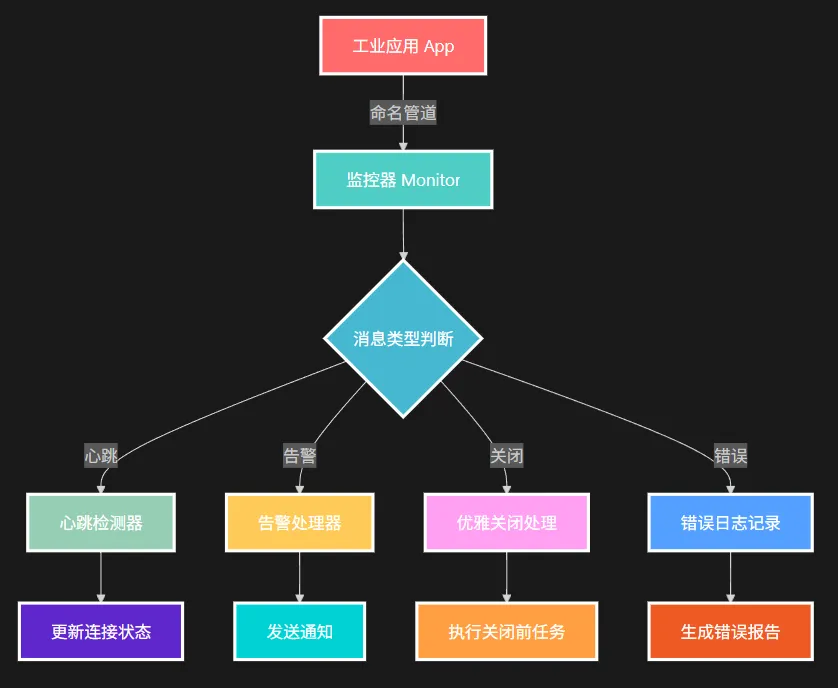
在工业软件开发中,你是否遇到过这样的痛点:应用程序突然崩溃却无法及时发现?关键进程异常但缺乏有效的监控手段?传统的文件日志方式延迟高、效率低?
今天我们就来解决这个问题!通过C#的命名管道技术,构建一套实时、高效、可靠的工业级应用监控系统。这套方案不仅能实现毫秒级的状态上报,还能在应用崩溃前执行优雅关闭流程。
🔍 问题分析:工业应用监控的三大挑战
1. 实时性要求高
工业环境下,设备状态变化需要毫秒级响应。传统的HTTP轮询或文件监控方式延迟过高,无法满足实时监控需求。
2. 可靠性要求严格
生产环境不容许监控系统本身成为故障点。需要具备自动重连、异常恢复、优雅关闭等机制。
3. 性能开销要可控
监控系统不能影响主业务性能,需要轻量级、低资源消耗的解决方案。
💡 解决方案:基于命名管道的双向通信架构
命名管道是Windows系统提供的高性能进程间通信机制,具有以下优势:
- 高性能:内核级别通信,延迟极低
- 双向通信:支持请求-响应模式
- 跨进程安全:内置访问控制机制
- 自动清理:进程结束后自动释放资源
🛠️ 代码实战:构建完整监控系统
作为C#开发者,你是否遇到过这样的困扰:项目功能越来越复杂,每次新增功能都要修改核心代码,部署时牵一发动全身?或者想要让用户自定义功能,却不知道如何优雅地实现?
今天就来聊聊MEF(Managed Extensibility Framework)插件化架构,这个微软官方提供的"神器"能让你的应用秒变可插拔系统,实现真正的模块化开发。无需重启程序就能动态加载新功能,让你的代码架构更加灵活优雅!
🤔 为什么需要插件化架构?
传统开发的痛点
在传统的单体应用中,我们经常面临这些问题:
1. 功能耦合严重
- 新增功能需要修改核心代码
- 一个模块出问题影响整个系统
- 代码维护成本越来越高
2. 部署困难
- 小功能更新需要重新部署整个应用
- 无法按需加载功能模块
- 用户无法自定义扩展功能
3. 团队协作效率低
- 多人开发容易产生代码冲突
- 功能模块无法独立测试和发布
插件化架构的优势
- ✅ 模块独立:各功能模块互不影响,可独立开发测试
- ✅ 动态加载:无需重启即可加载新插件
- ✅ 易于扩展:第三方可轻松开发插件
- ✅ 降低耦合:核心框架与业务逻辑分离
💡 MEF框架解决方案
MEF是微软提供的轻量级插件框架,通过Export和Import特性实现组件的自动发现和组合。
核心概念
- Export:标记可导出的组件
- Import:标记需要导入的依赖
- CompositionContainer:组合容器,负责组件装配
🛠 实战演示:构建简单插件系统
让我们从零开始构建一个插件化应用,看看MEF是如何工作的。
📦 第一步:定义插件接口
C#// PluginInterface.csproj
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<TargetFramework>net8.0</TargetFramework>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="System.ComponentModel.Composition" Version="8.0.0" />
</ItemGroup>
</Project>
// IPlugin.cs
namespace PluginInterface
{
public interface IPlugin
{
string Name { get; }
void Execute();
}
}
