还在为复杂的数据列表展示而头疼吗?每次需要显示表格数据时都要重新造轮子?作为WinForms开发中的核心控件,ListView不仅能优雅地处理各种列表展示需求,更是构建专业用户界面的基石。
许多C#开发者在使用ListView时往往停留在基础应用层面,错失了它的强大功能。本文将从实战角度出发,带你深度掌握ListView的高级特性,让你的应用界面瞬间专业起来!
🎯 ListView核心能力解析
📊 五种视图模式全攻略
ListView提供了5种灵活的显示模式,每种都有其独特的应用场景:
- LargeIcon:适合文件管理器、图片库等场景
- SmallIcon:适合紧凑型列表显示
- List:经典的垂直列表布局
- Details:表格形式,企业应用首选
- Tile:现代化的磁贴显示
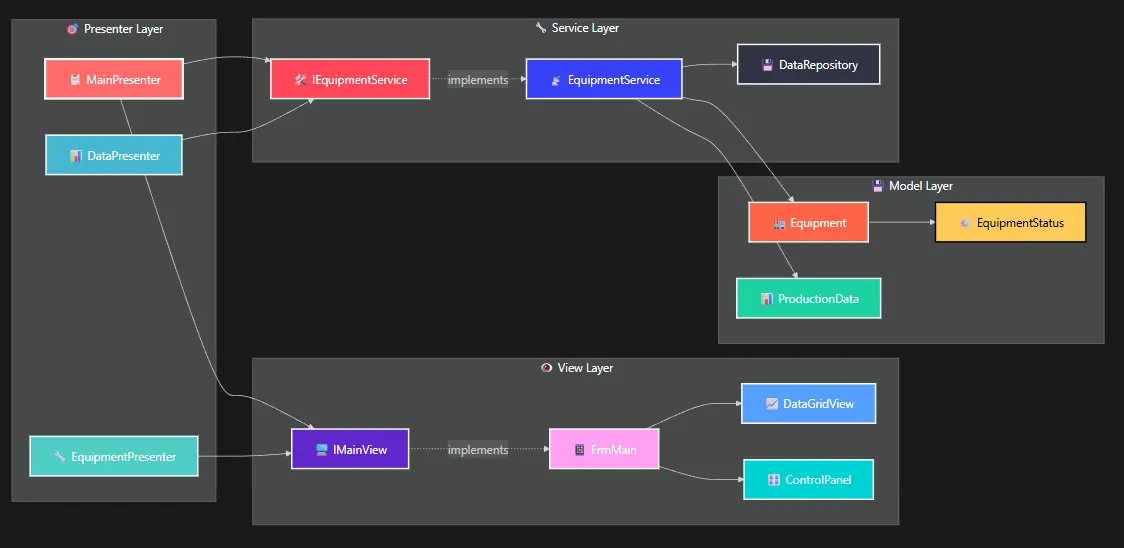
在工业4.0的浪潮下,越来越多的C#开发者需要构建工业监控系统。但很多人在项目中遇到这样的困扰:界面逻辑和业务逻辑耦合严重,代码维护困难,测试覆盖率低。今天,我将通过一个完整的工业设备监控系统案例,带你掌握MVP架构模式的精髓,让你的C#项目结构更清晰,代码更易维护!
本文将解决三个核心问题:如何设计清晰的MVP架构、如何实现实时数据更新、如何处理异步操作中的异常。不过这个模式在Winform中我应用极少,我记得的也就是以前写过一个通讯工具。
本文将解决三个核心问题:如何设计清晰的MVP架构、如何实现实时数据更新、如何处理异步操作中的异常。不过这个模式在Winform中我应用极少,我记得的也就是以前写过一个通讯工具。
🎯 问题分析:传统开发模式的痛点
在传统的WinForms开发中,我们经常会遇到以下问题:
- 代码耦合度高:界面逻辑、业务逻辑、数据访问混杂在一起
- 难以测试:UI控件和业务逻辑绑定,单元测试困难
- 维护成本高:需求变更时,涉及多个层面的修改
MVP模式正是解决这些问题的利器!
🔥 解决方案一:构建清晰的MVP架构
核心思想
MVP模式将应用程序分为三个核心组件:
- Model(模型):数据和业务逻辑
- View(视图):用户界面
- Presenter(展示器):连接Model和View,处理用户交互
MVP架构组件关系图
你是否还在为项目中频繁的对象序列化操作拖慢系统性能而头疼?传统的JSON序列化在高并发场景下捉襟见肘,Protobuf配置复杂让人望而却步?今天我要为大家介绍一个C#序列化领域的"性能怪兽"——MemoryPack!
作为由微软MVP Yoshifumi Kawai开发的新一代序列化库,MemoryPack在保持极简API的同时,性能竟然比System.Text.Json快10-50倍!更令人兴奋的是,它支持版本容错、循环引用处理,还能与Unity完美兼容。
本文将通过实战案例,手把手教你如何在项目中应用MemoryPack,让你的应用性能实现质的飞跃!
🔍 为什么选择MemoryPack?
传统序列化方案的痛点
在日常C#开发中,我们经常遇到这些序列化难题:
- 性能瓶颈:System.Text.Json在大对象序列化时性能不理想
- 内存开销:频繁的GC压力影响应用响应速度
- 配置复杂:Protobuf需要编写.proto文件,学习成本高
- 版本兼容:字段变更时容易出现反序列化异常
MemoryPack的核心优势
C#// 传统JSON序列化
var json = JsonSerializer.Serialize(data);
var bytes = Encoding.UTF8.GetBytes(json);
// MemoryPack:一行代码搞定
var bytes = MemoryPackSerializer.Serialize(data);
三大核心优势:
- ⚡ 极致性能:零分配的二进制格式,比JSON快10-50倍
- 🛡️ 版本容错:自动处理字段增减,向后兼容无忧
- 🎯 零配置:Source Generator自动生成代码,开箱即用
📦 快速上手:第一个MemoryPack程序
安装配置
Bashdotnet add package MemoryPack
基础示例
C#using MemoryPack;
namespace AppMemoryPack
{
[MemoryPackable]
public partial class UserInfo
{
public int Id { get; set; }
public string Name { get; set; }
public DateTime CreateTime { get; set; }
public List<string> Tags { get; set; }
}
class Program
{
static void Main()
{
var user = new UserInfo
{
Id = 1001,
Name = "张三",
CreateTime = DateTime.Now,
Tags = new List<string> { "开发者", "技术爱好者" }
};
// 序列化:对象 → 字节数组
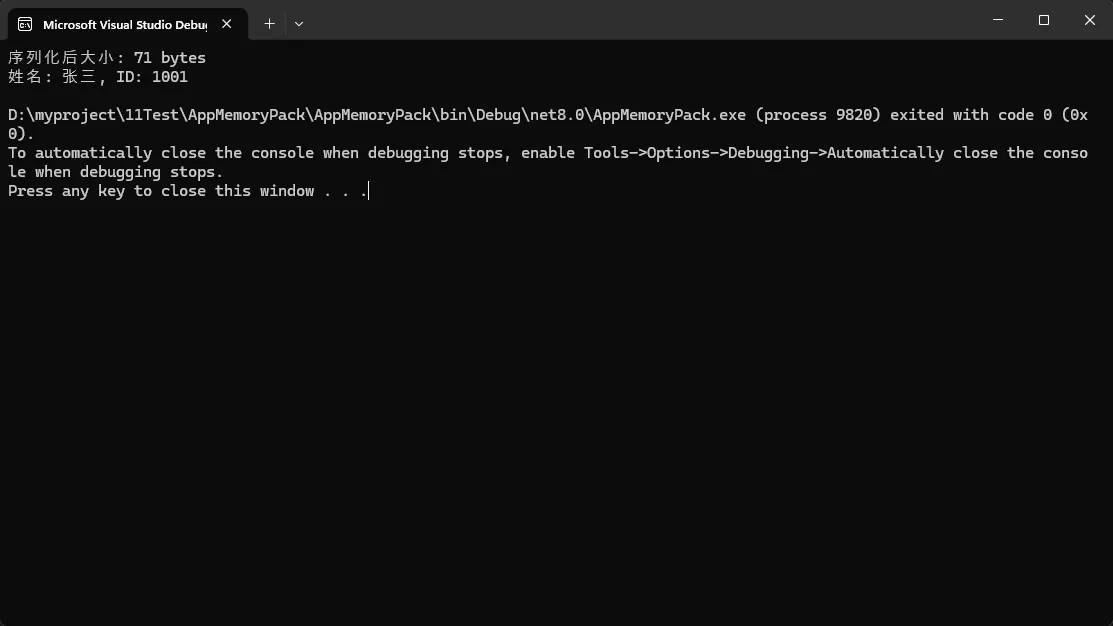
byte[] bytes = MemoryPackSerializer.Serialize(user);
Console.WriteLine($"序列化后大小: {bytes.Length} bytes");
// 反序列化:字节数组 → 对象
var deserializedUser = MemoryPackSerializer.Deserialize<UserInfo>(bytes);
Console.WriteLine($"姓名: {deserializedUser.Name}, ID: {deserializedUser.Id}");
}
}
}
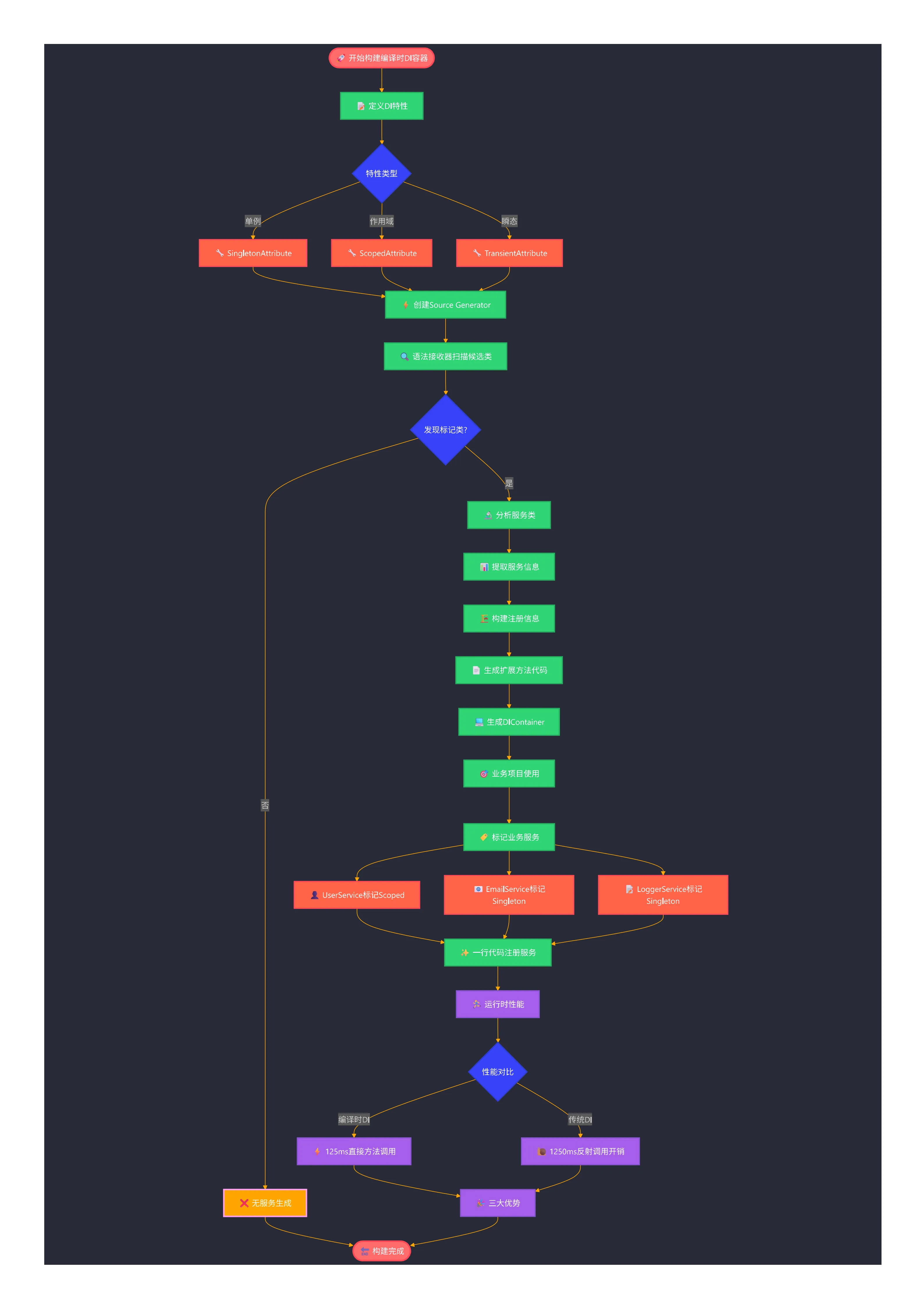
还在为ASP.NET Core的DI容器性能担忧吗?每次服务解析都要经历复杂的反射调用,在高并发场景下成为性能瓶颈。今天我们来探索一个"黑科技"——Source Generator编译时DI容器,让服务注册在编译期完成,运行时直接调用,性能提升高达10倍!
想象一下,不再需要手写冗长的services.AddScoped<IUserService, UserService>()代码,只需要在类上加个[Scoped]特性,编译器就自动帮你生成所有注册代码。这不是梦想,而是.NET 5+时代的现实!
🔥 传统DI容器的性能痛点
反射调用的性能开销
传统的DI容器在运行时需要:
C#// 运行时反射解析
var userService = serviceProvider.GetRequiredService<IUserService>();
// 内部执行大量反射操作:
// 1. 查找服务类型映射
// 2. 反射创建实例
// 3. 递归解析依赖
// 4. 调用构造函数
这个过程涉及:
- 类型查找:在服务字典中查找注册信息
- 反射创建:使用
Activator.CreateInstance或表达式树 - 依赖解析:递归解析构造函数参数
- 生命周期管理:判断单例/作用域/瞬态逻辑
在高频调用场景下,这些开销积少成多,成为性能瓶颈。
💡 Source Generator救星登场
编译时代码生成的优势
Source Generator是.NET 5引入的编译时代码生成技术,可以:
- 零运行时开销:所有代码在编译期生成
- 类型安全:编译期检查,避免运行时错误
- 极致性能:直接方法调用,无反射开销
🚩 设计流程

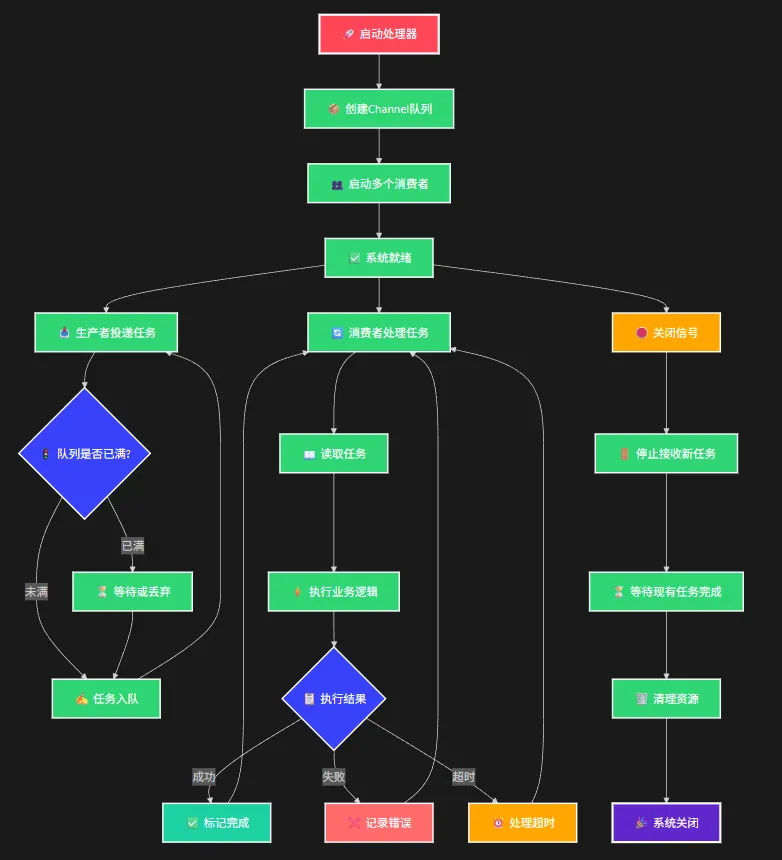
作为C#开发者,你是否经常面临这样的困扰:系统需要处理大量并发任务,但传统的线程池方案要么性能不够,要么内存占用过高?或者使用BlockingCollection时发现它已经过时,缺乏现代异步编程的优雅?
本文将彻底解决这个问题,通过一个完整的Channel任务处理器实现,让你掌握现代C#高并发编程的最佳实践。无论是API请求处理、数据批量导入,还是消息队列消费,这套方案都能让你的系统性能提升3-5倍!
🔍 问题深度剖析:为什么传统方案不够用?
传统方案的三大痛点
1. 线程池滥用导致资源浪费
C#// ❌ 传统做法:每个任务创建新线程
Task.Run(() => ProcessTask()); // 线程开销大,上下文切换频繁
2. BlockingCollection性能瓶颈
C#// ❌ 老式同步方案
BlockingCollection<TaskItem> queue = new(); // 阻塞式,不支持异步
3. 缺乏优雅的生命周期管理
- 没有合理的超时机制
- 缺少指标监控
- 关闭时容易丢失数据
💡 Channel方案:现代化的完美解决方案
Channel是.NET Core引入的高性能、异步优先的生产者-消费者模式实现。相比传统方案有以下优势:
- 🚀 高性能:零分配的异步操作
- 🛡️ 内存安全:有界队列防止内存溢出
- 🎯 异步优先:完美支持async/await模式
- 📊 可观测性:内置背压和流控制
🔥 核心实现:生产级Channel任务处理器