
🎬 WinForms动画实现:让你的界面"活"起来的硬核技巧
说实话,第一次看到别人做的WinForms程序里那些丝滑流畅的动画效果时,我整个人是懵的。什么?WinForms也能这么炫?那个被我用了三年、只能画静态图形的Graphics,居然还能玩出这种花样?
后来在一个工业控制项目中,客户死活要求仪表盘指针"必须像真的一样转动",我才硬着头皮啃下了这块硬骨头。踩过无数坑之后——闪烁、卡顿、CPU占用飙升——终于摸索出一套让Draw动起来的实战方法。今天咱们就掰开揉碎了聊聊这事儿。
你能从这篇文章拿走什么?
✅ 3种从基础到高级的动画实现方案(含完整代码)
✅ 解决闪烁问题的终极武器(性能提升70%+)
✅ 真实项目中的性能优化数据对比
✅ 可直接复用的动画框架模板
🔍 为什么WinForms做动画这么"难"?
很多开发者碰到的第一个问题是:为什么我的动画一闪一闪的,像坏掉的霓虹灯?
根本原因其实挺简单——WinForms的绘制机制天生就不是为动画设计的。每次调用Invalidate()触发重绘时,系统会先清空背景(刷白),然后才调用你的OnPaint方法画东西。这"清空-重画"的过程如果发生在每秒30帧以上,人眼就会捕捉到闪烁。
我见过最离谱的写法是这样的:
c#// ❌ 错误示范:直接在Timer里暴力重绘
private void timer1_Tick(object sender, EventArgs e)
{
angle += 5; // 角度累加
this.Invalidate(); // 触发重绘
}
protected override void OnPaint(PaintEventArgs e)
{
e.Graphics.DrawEllipse(Pen. Red, x, y, 50, 50); // 画个圆
}
这代码跑起来的效果?恭喜你,成功复刻了80年代的电子屏幕。CPU占用率还能轻松突破40%,风扇狂转,用户体验直接拉跨。
第二个坑:性能陷阱。
有些同学知道要用双缓冲,但不知道Graphics对象的创建销毁本身就是个重量级操作。我在一个数据监控项目中测过,每秒60次Graphics.FromImage()调用,内存分配能达到15MB/s,GC压力巨大。
💡 核心原理:动画的本质是啥?
说白了,动画就是快速连续播放的静态画面 + 视觉暂留效应。在WinForms里实现动画,关键要解决三个问题:
- 定时触发:怎么按固定频率刷新画面?
- 状态管理:动画的位置、角度、颜色等参数怎么更新?
- 高效绘制:怎么避免闪烁和卡顿?
下面我按照从简单到复杂的顺序,给出三套渐进式解决方案。每一套都是我在实际项目中验证过的——有血有肉,能直接用。
🔥 C#事件订阅管理器:一个类解决内存泄漏噩梦
你是否遇到过这样的情况:应用程序运行一段时间后内存占用越来越高,最终导致系统卡顿甚至崩溃?如果你的项目中大量使用了事件订阅,那么很可能就是事件订阅未正确取消导致的内存泄漏问题。
今天我将分享一个实用的C#事件订阅管理器,它能够自动管理所有事件订阅的生命周期,彻底告别手动取消订阅的烦恼。这个工具类不仅代码简洁,而且在实际项目中屡试不爽,堪称防止内存泄漏的利器!
🚨 问题分析:事件订阅的隐形杀手
常见的内存泄漏场景
在C#开发中,事件订阅导致的内存泄漏是最容易被忽视却又最致命的问题之一:
c#namespace AppEventSubscriptionManager
{
public class Order
{
public int OrderId { get; }
public string CustomerName { get; }
public DateTime OrderDate { get; }
public Order(int orderId, string customerName)
{
OrderId = orderId;
CustomerName = customerName;
OrderDate = DateTime.Now;
}
}
public class OrderCreatedEventArgs : EventArgs
{
public Order Order { get; }
public OrderCreatedEventArgs(Order order)
{
Order = order;
}
}
public class OrderService
{
public event EventHandler<OrderCreatedEventArgs> OrderCreated;
public void CreateOrder(Order order)
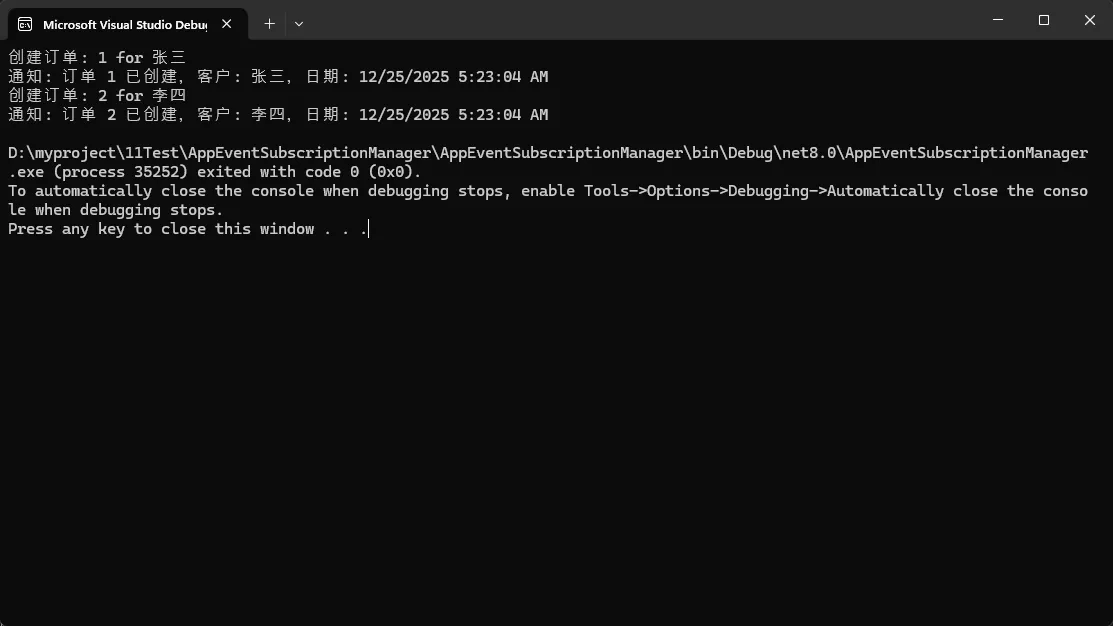
{
Console.WriteLine($"创建订单: {order.OrderId} for {order.CustomerName}");
OrderCreated?.Invoke(this, new OrderCreatedEventArgs(order));
}
}
public class NotificationService
{
public NotificationService(OrderService orderService)
{
// ⚠️ 危险:只订阅,不取消订阅
orderService.OrderCreated += OnOrderCreated;
}
private void OnOrderCreated(object sender, OrderCreatedEventArgs e)
{
Console.WriteLine($"通知: 订单 {e.Order.OrderId} 已创建,客户: {e.Order.CustomerName},日期: {e.Order.OrderDate}");
}
}
internal class Program
{
static void Main(string[] args)
{
// 创建订单服务和通知服务的实例
OrderService orderService = new OrderService();
NotificationService notificationService = new NotificationService(orderService);
Order newOrder = new Order(1, "张三");
orderService.CreateOrder(newOrder);
Order anotherOrder = new Order(2, "李四");
orderService.CreateOrder(anotherOrder);
}
}
}
🤖 GPT是什么?揭开AI大模型的神秘面纱
你有没有想过,为什么ChatGPT能像人类一样自然地对话?为什么它能写诗、编程、甚至帮你分析复杂的商业问题? 很多人以为这只是简单的"关键词匹配"或"模板填充",但实际上,GPT背后的技术原理远比你想象的精妙。
今天,咱们就用最接地气的方式,把GPT这个看似高深的技术"掰开揉碎"讲清楚。读完这篇文章,你不仅能理解GPT的工作原理,还能向身边的朋友科普这项改变世界的技术。
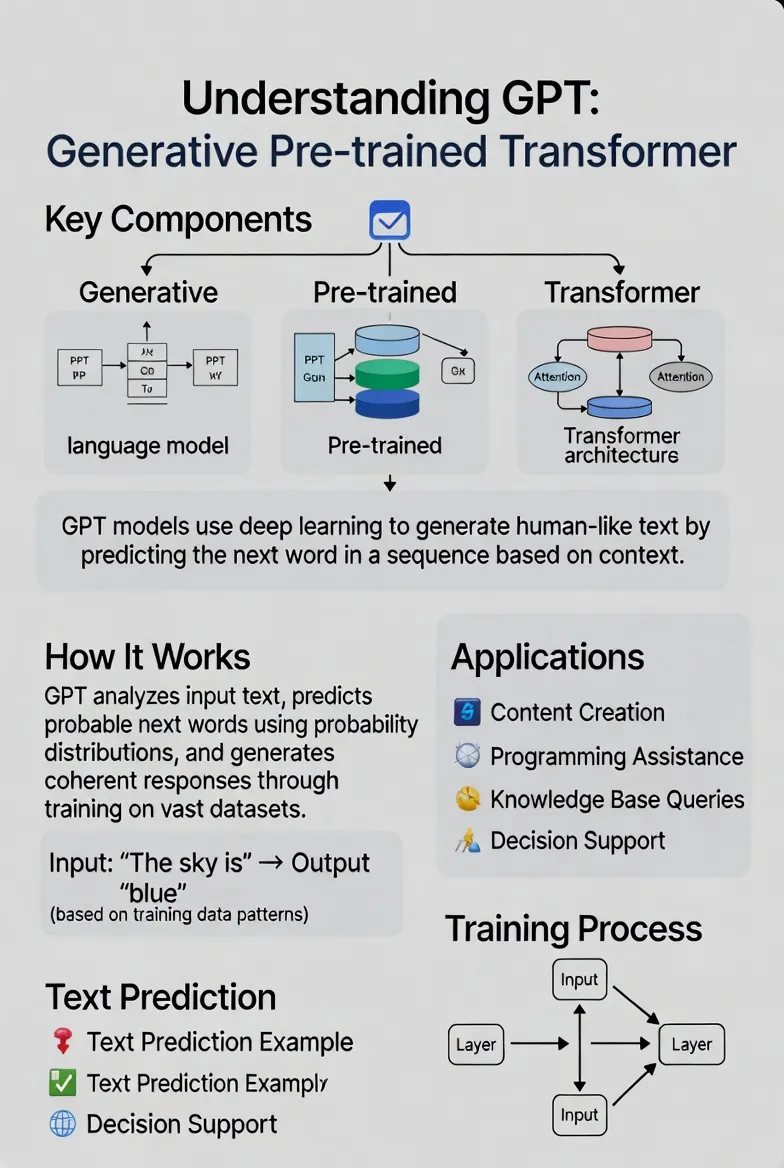
🔍 GPT三个字母背后的秘密
GPT这个名字可不是随便起的,它是三个英文单词的缩写,每个字母都藏着关键信息:
G = Generative(生成式)
这意味着模型具备"创造"能力——不是简单地检索现有内容,而是真正生成全新的文本。
P = Pre-trained(预训练)
在正式"上岗"之前,模型已经读过海量的书籍、网页、文章,掌握了语言的基本规律和常识。
T = Transformer(变换器)
这是一种革命性的神经网络架构,让机器能够理解复杂的上下文关系,就像人类阅读时能联系前后文一样。
听起来还是有点抽象?别急,咱们一个一个拆开来讲。
🎨 什么是"生成式"?用例子说透它
很多人误以为GPT只是在"复制粘贴"互联网上的内容。其实不然——它是通过预测概率来生成文本的。
原理很简单:猜下一个词
想象你在跟朋友聊天,对方说了半句话:"今天天气真…",你的大脑会自动预测下一个词可能是"好"、"热"、"冷"。GPT做的就是同样的事,只不过它是基于数学概率来预测。
Python openpyxl实战指南:从Excel小白到自动化大师
作为Windows下的Python开发者,你是否经常遇到这样的场景:老板给你一个复杂的Excel表格,要求批量处理数据、生成报表,或者需要定期更新Excel中的数据?手工操作不仅效率低下,还容易出错。
本文将带你深入掌握openpyxl这个强大的Excel操作库,从基础读写到高级应用,让你告别重复的Excel操作,实现真正的办公自动化。无论你是Python新手还是有一定经验的开发者,都能在这里找到实用的解决方案。
🔍 问题分析:为什么选择openpyxl?
在众多Python Excel操作库中,为什么推荐openpyxl?让我们来看看实际场景:
传统方式的痛点:
- 手工复制粘贴,效率极低
- 格式丢失,需要重新设置
- 数据量大时容易出错
- 重复性工作占用大量时间
openpyxl的优势:
- ✅ 完美支持Excel 2010+格式(.xlsx)
- ✅ 保持原有格式和样式
- ✅ 支持公式、图表、条件格式
- ✅ 内存占用相对较小
- ✅ 与pandas无缝集成
💡 解决方案:openpyxl核心功能解析
🚀 环境准备
首先安装必要的库:
bashpip install openpyxl pandas
📊 基础操作:读写Excel文件
创建和保存工作簿
pythonfrom openpyxl import Workbook
from openpyxl.utils import get_column_letter
# 创建新的工作簿
wb = Workbook()
ws = wb.active # 获取活动工作表
ws.title = "销售数据" # 设置工作表名称
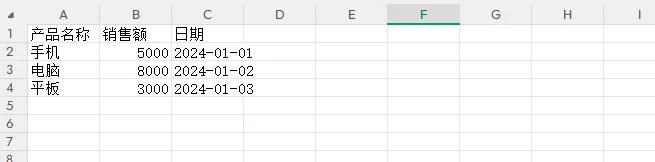
# 写入数据
ws['A1'] = '产品名称'
ws['B1'] = '销售额'
ws['C1'] = '日期'
# 批量写入数据
data = [
['手机', 5000, '2024-01-01'],
['电脑', 8000, '2024-01-02'],
['平板', 3000, '2024-01-03']
]
for row_num, row_data in enumerate(data, start=2):
for col_num, value in enumerate(row_data, start=1):
ws.cell(row=row_num, column=col_num, value=value)
# 保存文件
wb.save('销售数据.xlsx')
print("✅ Excel文件创建成功!")
🔥 SkiaSharp + WinForms:打造工业级动画系统的完整指南
你是否曾经被客户要求开发一个酷炫的工业监控界面?或者想要在WinForms应用中实现流畅的动画效果?传统的GDI+绘图性能有限,而WPF又显得过于重量级。今天我们来探索一个完美的解决方案:SkiaSharp + WinForms,它能让你轻松实现60FPS的工业级动画效果。
本文将手把手教你构建一个完整的工业动画演示系统,包含齿轮转动、传送带、机械臂等多种动画效果,代码开箱即用!
🎯 为什么选择SkiaSharp?
传统绘图方案的痛点
在WinForms开发中,我们经常遇到这些问题:
- GDI+性能瓶颈:复杂动画卡顿明显
- WPF过度设计:简单项目引入复杂度过高
- 第三方控件昂贵:商业动画控件价格不菲
SkiaSharp的优势
c#// SkiaSharp:硬件加速 + 跨平台 + 开源免费
using SkiaSharp;
using SkiaSharp.Views.Desktop;
// 60FPS丝滑动画,告别卡顿
private Timer animationTimer = new Timer { Interval = 16 };
核心优势:
- 🚀 硬件加速:GPU渲染,性能强劲
- 🎨 丰富API:路径、渐变、滤镜应有尽有
- 💰 开源免费:Google出品,质量保证
- 🔧 易于集成:几行代码即可在WinForms中使用
🏗️ 项目架构设计
核心组件结构
c#// 主窗体:FrmMain
public partial class FrmMain : Form
{
private SKControl skiaCanvas; // 绘图画布
private Timer animationTimer; // 动画定时器
private float rotationAngle = 0f; // 旋转角度
private float animationSpeed = 1.0f; // 动画速度
}
