
🧭 开篇:AI 2.0 真的“无所不能”吗?
这两年,只要团队里提到“上 AI”“搞大模型”,会议室的气氛就会突然亢奋起来:有人想用 AI 写代码,有人想做智能客服,有人盯着生成 PPT 和方案产出,还有人默默打开了招聘网站——“我是不是要被替代了?”
但冷静下来,多数团队会发现一个尴尬现实:
- 花了不少预算接入大模型,真正上线的功能却寥寥无几;
- Demo 看起来惊艳,放到真实业务里一用,不是“答非所问”,就是“敢编敢造”;
- 管理层天天问 ROI,技术团队天天在修 Prompt、调参数、整理数据,越做越怀疑人生。
问题不在“AI 不够强”,而在我们还在用 AI 1.0 的旧思路,硬套在 AI 2.0 的新范式上。
这篇文章,就是想把这件事讲明白:AI 1.0 和 AI 2.0 的本质差异在哪里?大模型真正适合干什么?以及——一个务实团队该怎么“稳稳地”用好它。

🧨 从AI 1.0到AI 2.0:到底变了什么?
🤖 AI 1.0:精确规则与窄场景王国
传统意义上的 AI,更像是“高级版 Excel + 一堆规则引擎”:
- **需求模式:**先把业务逻辑拆成特征、规则、模型,再写成一堆 if-else 和算法;
- 能力边界:识别图片中的猫、预测一个数值、给用户打标签,这类窄任务很擅长;
- **工程特点:**大量特征工程、离线训练、模型上线后边界稳定,不轻易改动。
一句话:AI 1.0 是“会算的系统”,核心价值是“帮你算得更快、更准”。
🧬 AI 2.0:语言模型带来的“生成范式”
到了大模型这代,画风完全不同:
- 输入可以是文本、图片、代码、日志,甚至多模态;
- 输出不局限于“一个数”或“一个标签”,而是完整的文本、SQL、接口调用序列,甚至完整工作流;
- 模型可以在缺少明确规则、信息不完备的情况下,做出“看上去合理”的决策和创作。
AI 2.0更像是“会理解、会表达、会协作的数字同事”。
但也因此,大模型有一个致命“副作用”:幻觉。
它会一本正经地胡说八道,还说得很有说服力——这对工程系统来说,是完全不同级别的风险。
🧩 最大的坑:用确定性思维,管理一个概率性系统
很多团队真正踩坑的地方在这里:
- 按照传统软件工程的逻辑,期望:
- “只要输入一样,输出就一样”,
- “规则只要写死,就不会乱跑”。
- 结果面对一个天生带随机性、带偏见、会遗忘上下文的大模型,想靠一次性 Prompt + 固定超参把它钉死在墙上。
本质错位:你在用“机械表”的维护方式,管理一片“天气系统”。
🔍 业务痛点:为什么“上大模型”总是烂尾?
🧱 常见误区:以为“调用一个 API 就叫 AI 转型”
这几类“迷之自信”,在各行各业都能见到:
- 把 Demo 当产品
- PoC 时:选一个最简单的问题,堆人堆资源,效果还不错;
- 一旦扩到全量场景,问题暴露:长尾问答、冷门业务、脏数据,统统扑上来。
- 把 Prompt 当银弹
- 开始:一群人挤在文档里改系统 Prompt,“试错—回滚—再试”;
- 过一阵:Prompt 文件越写越长,没人敢动,最后变成了一段“集体神秘咒语”。
- 只谈模型,不谈系统
- 可以说清楚用的是 GPT 还是开源模型;
- 却说不清楚:数据从哪来、落到哪去、怎么闭环、谁对结果负责。
结果:大模型系统上线之后,业务不敢真用,只能停留在“演示项目”和“宣传 PPT”。
📉 对业务的真实影响:看得见成本,看不见收益
如果粗略量化一下,这些问题带来的后果大概是:
- **人力浪费:**一个“AI 项目组”里,80% 的时间花在“缝缝补补”——改 Prompt、调温度、加规则、改配置;
- **决策风险:**一旦把“有幻觉”的模型接入真实生产链路,比如风控、财务、医疗,轻则引发投诉,重则直接触碰合规红线;
- **机会成本:**三个月做一个“泛泛的 AI 助手”,却错过了某几个可以确实提效 30% 的垂直场景。
最糟糕的结果是——管理层对 AI 完全失去耐心:
“花了一年,怎么连个像样的 ROI 报表都给不出来?”
你是否还在为Selenium WebDriver的各种兼容性问题而头疼?是否曾因为元素定位不稳定而通宵达旦调试测试脚本?作为一名.NET开发者,我深知这些痛点。今天要介绍的Playwright for .NET,就是为了解决这些传统Web自动化测试中的老大难问题而生的现代化解决方案。
微软开发的这款工具不仅性能更强、更稳定,还天生支持现代Web应用的各种特性。本文将通过实际案例,带你快速上手这个被誉为"Selenium终结者"的自动化测试框架,并创建你的第一个自动化脚本。
🌟 Playwright简介与核心优势
什么是Playwright?
Playwright是由微软开发的现代Web自动化测试框架,专为现代Web应用而设计。它支持Chromium、Firefox和Safari三大浏览器引擎,提供了统一的API来进行Web自动化操作。
🚀 核心优势解析
1. 天生的异步支持
C#// Playwright天生支持async/await模式
await page.GotoAsync("https://www.baidu.com");
await page.FillAsync("#kw", "Playwright");
await page.ClickAsync("#su");
2. 自动等待机制
- 智能等待:自动等待元素可见、可点击
- 网络空闲:等待页面完全加载完成
- 无需手动Thread.Sleep
3. 多浏览器原生支持
C#// 一套代码,多浏览器运行
var browsers = new[] { "chromium", "firefox", "webkit" };
foreach (var browserType in browsers)
{
await using var browser = await playwright[browserType].LaunchAsync();
// 相同的测试逻辑
}
⚖️ Playwright vs Selenium:谁更胜一筹?
🔥 性能对比
| 特性 | Selenium | Playwright |
|---|---|---|
| 启动速度 | 3-5秒 | 1-2秒 |
| 元素定位 | 需手动等待 | 自动等待 |
| 浏览器支持 | 需额外驱动 | 内置浏览器 |
| 并发能力 | 中等 | 优秀 |
💡 实际使用场景对比
Selenium传统写法:
C#// Selenium需要显式等待
WebDriverWait wait = new WebDriverWait(driver, TimeSpan.FromSeconds(10));
var element = wait.Until(SeleniumExtras.WaitHelpers.ExpectedConditions
.ElementToBeClickable(By.Id("submit")));
element.Click();
Playwright现代写法:
C#// Playwright自动处理等待
await page.ClickAsync("#submit"); // 就这么简单!
📊 选择建议
- 选择Selenium:已有大量历史代码、团队熟悉度高
- 选择Playwright:新项目、追求性能、需要现代化特性
🛠️ 环境搭建:三步完成配置
第一步:安装包
Bash# 添加Playwright包
dotnet add package Microsoft.Playwright
dotnet add package Microsoft.Playwright.NUnit
第二步:安装浏览器
Bash# 下载并安装浏览器二进制文件,在对应的debug目录下,我这是.net 8
.\playwright.ps1 install
上周和一位刚上班的C#小孩聊天,他苦恼地说:"每次面试都会被问到值类型和引用类型的区别,我总是答得模糊不清。更要命的是,线上系统偶尔出现内存泄漏,但我根本不知道从哪里排查。"
今天这篇文章,我将用最通俗的语言和实战代码,帮你彻底搞懂C#变量类型与内存分配的核心机制,让你在技术面试和实际开发中都能游刃有余。
🔍 问题分析:为什么内存机制如此重要?
在深入解决方案之前,我们先来分析一下,为什么理解变量类型和内存分配如此关键:
- 性能影响:不同的变量类型在内存中的存储和访问方式差异巨大
- 内存泄漏:错误的变量使用方式可能导致内存无法释放
- 面试必考:几乎所有C#技术面试都会涉及这个话题
- 代码质量:深入理解有助于写出更高效、更稳定的代码
💡 解决方案一:深入理解值类型与引用类型
🎯 核心概念解析
C#namespace AppVariableMemory
{
internal class Program
{
static void Main(string[] args)
{
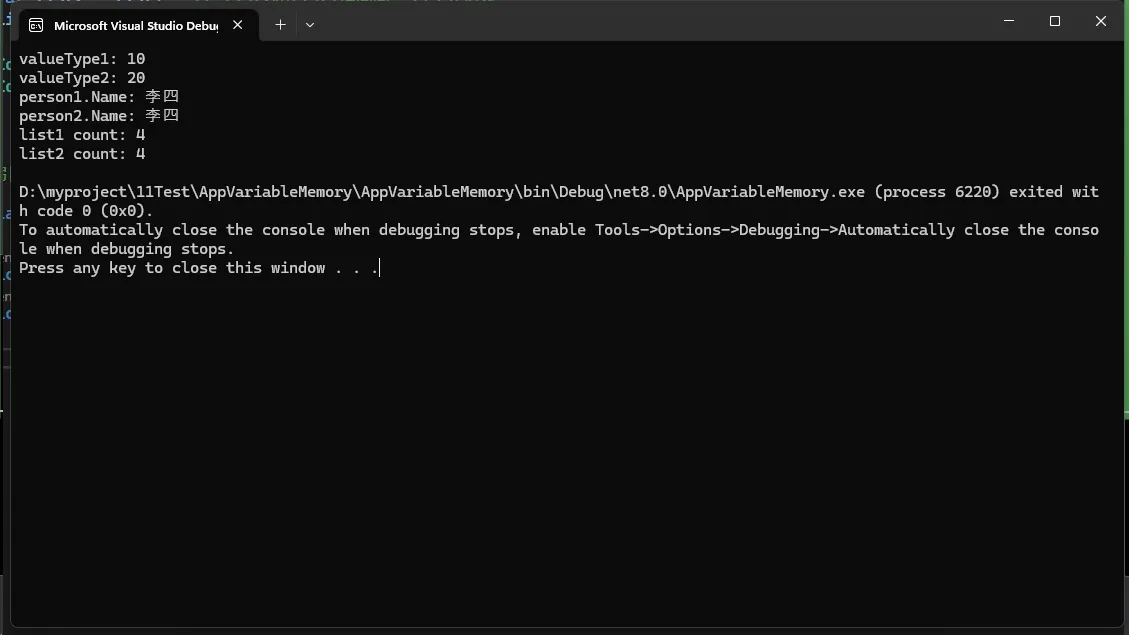
// 值类型示例 - 存储在栈上
int valueType1 = 10; // 直接存储值
int valueType2 = valueType1; // 复制值
valueType2 = 20; // 修改副本,不影响原值
Console.WriteLine($"valueType1: {valueType1}");
Console.WriteLine($"valueType2: {valueType2}");
// 引用类型示例 - 对象存储在堆上,引用存储在栈上
Person person1 = new Person { Name = "张三", Age = 25 };
Person person2 = person1; // 复制引用,指向同一个对象
person2.Name = "李四"; // 修改对象属性
Console.WriteLine($"person1.Name: {person1.Name}");
Console.WriteLine($"person2.Name: {person2.Name}");
// 关键差异演示
DemonstrateMemoryAllocation();
}
static void DemonstrateMemoryAllocation()
{
// 值类型:每次赋值都创建新的内存空间
int a = 5;
int b = a; // 在栈上创建新的内存位置
b = 10; // 只修改b的值,a不受影响
// 引用类型:多个变量可以指向同一个对象
var list1 = new List<int> { 1, 2, 3 };
var list2 = list1; // list2和list1指向同一个List对象
list2.Add(4); // 通过list2修改,list1也能看到变化
Console.WriteLine($"list1 count: {list1.Count}");
Console.WriteLine($"list2 count: {list2.Count}");
}
}
// 自定义引用类型
public class Person
{
public string Name { get; set; }
public int Age { get; set; }
}
}
最近在Reddit上看到一个引起千万程序员共鸣的帖子:一位仅有2年经验的C#开发者独自维护着一家公司的核心系统,面对百万级数据查询时束手无策。他的困惑让我想起了自己的成长经历——谁没有在LINQ的性能陷阱里跌过跟头呢?
据统计,70%的C#开发者在处理大数据量时都遇到过性能问题,而其中60%的问题源于LINQ使用不当。今天,我将结合实际案例,分享5个立竿见影的LINQ性能优化技巧,让你从此告别查询超时!
🔥 问题分析:为什么你的LINQ查询这么慢?
常见痛点梳理
许多开发者面临的核心问题包括:
- 物化陷阱:不理解
.ToList()的后果 - 过度获取:拉取不需要的数据
- 延迟加载:造成N+1查询问题
- 盲目使用Include:加载无关数据
让我们看看这个真实案例:
C#// ❌ 危险操作 - 会导致内存溢出
var allCustomers = db.Customers.ToList();
var filteredCustomers = allCustomers.Where(c => c.Country == "China");
问题分析:这段代码会将整个Customers表加载到内存中,如果表中有百万条记录,直接导致内存溢出。
💡 解决方案:5个实战优化技巧
🎯 技巧1:善用Select投影,只取所需
核心原则:永远不要获取超过需求的数据
C#namespace AppLinq5
{
// Customer 实体类
public class Customer
{
public int Id { get; set; }
public string Name { get; set; }
public string Email { get; set; }
public string Phone { get; set; }
public string Address { get; set; }
public bool IsActive { get; set; }
public string Description { get; set; } // 大文本字段
}
// DTO 类 - 只包含需要的字段
public class CustomerDto
{
public int Id { get; set; }
public string Name { get; set; }
public string Email { get; set; }
}
public class CustomerRepository
{
private readonly List<Customer> _customers;
public CustomerRepository()
{
// 模拟数据
_customers = new List<Customer>
{
new Customer { Id = 1, Name = "张三", Email = "zhang@email.com", Phone = "123456", Address = "北京市", IsActive = true, Description = "很长的描述文本..." },
new Customer { Id = 2, Name = "李四", Email = "li@email.com", Phone = "789012", Address = "上海市", IsActive = true, Description = "另一个很长的描述..." },
new Customer { Id = 3, Name = "王五", Email = "wang@email.com", Phone = "345678", Address = "广州市", IsActive = false, Description = "第三个长描述..." }
};
}
public IQueryable<Customer> GetCustomers()
{
return _customers.AsQueryable();
}
}
public class CustomerService
{
private readonly CustomerRepository _repository;
public CustomerService(CustomerRepository repository)
{
_repository = repository;
}
// ❌ 错误做法 - 查询所有字段
public List<Customer> GetAllCustomersBad()
{
return _repository.GetCustomers()
.Where(c => c.IsActive)
.ToList(); // 返回所有字段,包括不需要的大文本字段
}
// ✅ 正确做法 - 只选择需要的字段
public List<CustomerDto> GetCustomerSummary()
{
return _repository.GetCustomers()
.Where(c => c.IsActive)
.Select(c => new CustomerDto
{
Id = c.Id,
Name = c.Name,
Email = c.Email // 只选择需要的字段
})
.ToList();
}
}
internal class Program
{
static void Main(string[] args)
{
var repository = new CustomerRepository();
var customerService = new CustomerService(repository);
// ✅ 获取客户摘要信息 - 只包含需要的字段
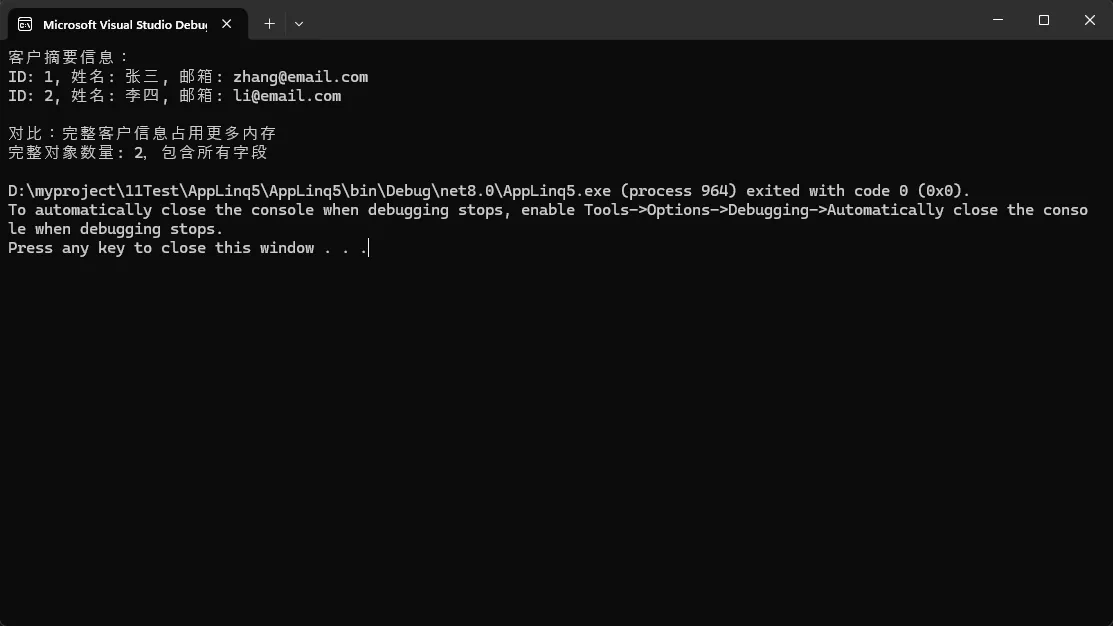
var customerSummaries = customerService.GetCustomerSummary();
Console.WriteLine("客户摘要信息:");
foreach (var customer in customerSummaries)
{
Console.WriteLine($"ID: {customer.Id}, 姓名: {customer.Name}, 邮箱: {customer.Email}");
}
Console.WriteLine("\n对比:完整客户信息占用更多内存");
var fullCustomers = customerService.GetAllCustomersBad();
Console.WriteLine($"完整对象数量: {fullCustomers.Count},包含所有字段");
}
}
}
你是否遇到过这样的场景:需要定时更新界面数据、实现倒计时功能,或者创建自动保存机制?作为C#开发者,这些需求在WinForms开发中几乎每天都会碰到。今天我们就来深入探讨System.Windows.Forms.Timer这个"小而美"的控件,让你彻底掌握定时任务的开发技巧。
本文将通过实战案例,教你如何用Timer控件解决常见的定时任务问题,避开开发中的常见陷阱,让你的应用更加专业和稳定。
🎯 Timer控件核心原理解析
在深入实战之前,我们先理解Timer的核心机制。WinForms中的Timer并不是"真正"的多线程定时器,而是基于Windows消息循环的组件。
🔧 三大核心属性
- Enabled:控制定时器启停状态(true/false)
- Interval:时间间隔,单位毫秒,最小值通常为15-55ms
- Tag:存储自定义数据的万能属性
⚡ 核心事件与方法
- Tick事件:定时触发的核心事件处理器
- Start()/Stop():编程式启停控制
💡 实战应用1:打造专业数字时钟
这是Timer最经典的应用场景。让我们创建一个高颜值的实时时钟:
C#using Timer = System.Windows.Forms.Timer;
namespace AppWinformTimer
{
public partial class FrmClock : Form
{
private Label timeLabel;
private Timer clockTimer;
public FrmClock()
{
InitializeComponent();
InitializeUI();
SetupTimer();
}
private void InitializeUI()
{
this.Text = "专业数字时钟";
this.Size = new Size(400, 200);
this.StartPosition = FormStartPosition.CenterScreen;
timeLabel = new Label
{
Dock = DockStyle.Fill,
TextAlign = ContentAlignment.MiddleCenter,
Font = new Font("Microsoft YaHei", 28F, FontStyle.Bold),
ForeColor = Color.DodgerBlue,
BackColor = Color.Black
};
this.Controls.Add(timeLabel);
}
private void SetupTimer()
{
clockTimer = new Timer
{
Interval = 1000 // 1秒更新一次
};
clockTimer.Tick += ClockTimer_Tick;
clockTimer.Start();
// 立即显示当前时间
UpdateTimeDisplay();
}
private void ClockTimer_Tick(object sender, EventArgs e)
{
UpdateTimeDisplay();
}
private void UpdateTimeDisplay()
{
timeLabel.Text = DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss");
}
protected override void OnFormClosed(FormClosedEventArgs e)
{
// 🚨 重要:记得释放资源
clockTimer?.Dispose();
base.OnFormClosed(e);
}
}
}

