
在现代 AI 应用开发中,函数调用是一项强大的功能,它允许 AI 模型直接与应用程序的功能进行交互。Microsoft Semantic Kernel 作为一个开源框架,提供了简单而强大的方式来集成这一能力。本文将详细介绍如何在 Semantic Kernel 中使用聊天完成(Chat Completion)进行函数调用,帮助开发者构建更智能、更实用的 AI 应用。
什么是函数调用?
函数调用(Function Calling)允许 AI 模型识别何时应该调用预定义的函数,并以结构化的方式提供必要的参数。这使得 AI 能够:
- 执行特定任务
- 获取外部信息
- 触发应用程序中的操作
在 Semantic Kernel 中,这一功能与大型语言模型(LLM)的能力无缝集成,使开发体验更加流畅。
Semantic Kernel 环境准备
首先,我们需要创建一个新的 C# 项目并安装必要的 NuGet 包:
YAML架构是语义内核提供的一种声明式语法,用于定义AI提示模板。通过使用YAML,开发者可以更加结构化地创建、管理和维护提示,使得提示的版本控制、测试和部署变得更加简单。 问题来了,YAML是我现阶段最不喜欢的配置文件格式。。。。
YAML架构的基本结构
语义内核提示的YAML文件由几个关键部分组成,下面我们将详细介绍每个部分:
YAML# 提示函数的基本信息
name: SummarizeText # 函数名称
description: 将文本概括为简明扼要的摘要 # 函数描述
template_format: semantic-kernel # 模板格式
template: | # 提示模板内容
请将以下文本概括为简洁的摘要:
{{$input}}
摘要:
# 输入变量定义
input_variables:
- name: input # 变量名称
description: 需要被概括的文本 # 变量描述
is_required: true # 是否必需
default: "" # 默认值
# 输出变量定义
output_variables:
- name: summary # 输出变量名
description: 生成的文本摘要 # 输出描述
# 执行设置
execution_settings:
default: # 默认设置
service: OpenAI # 服务提供商
model: gpt-4 # 使用的模型
temperature: 0.7 # 温度参数
max_tokens: 500 # 最大令牌数
在人工智能和大型语言模型(LLM)的世界中,提示词(Prompts)扮演着至关重要的角色。它们是我们与AI沟通的桥梁,决定了AI输出的质量和相关性。本文将深入探讨Microsoft Semantic Kernel中的提示词工程,帮助您理解如何有效地利用提示词来提升AI应用的效果。
提示词的基本概念
提示词是我们提供给模型的输入或查询,以期获取特定的响应。在Microsoft Semantic Kernel中,提示词工程(Prompt Engineering)已成为一个新兴的专业领域,它需要创造力和对细节的关注。
提示词的重要性
有效的提示词设计对于从LLM AI模型中获得预期结果至关重要。通过精心选择正确的词语、短语、符号和格式,可以引导模型生成高质量且相关的文本。
例如,考虑以下两个提示词:
text请给我讲述人类的历史。 请用3句话给我讲述人类的历史。
第一个提示词可能会产生一个冗长的报告,而第二个提示词则会产生一个简洁的回应。如果您正在构建空间有限的用户界面,第二个提示词会更适合您的需求。
今天突发灵感,撰写了这篇文章,希望能为大家带来一些启发。在当今软件开发快速迭代的时代,传统的静态编码模式已逐渐难以满足不断增长的灵活性需求。本文将深入探讨一种结合人工智能、动态编译和反射技术的创新解决方案,揭示编程范式的革命性变革。
核心技术架构
这个创新方案主要由三个关键技术组件构成:
- AI代码生成
- 动态代码编译
- 运行时插件加载
AI代码生成:智能编程助手
C#var chatCompletionService = kernel.GetRequiredService<IChatCompletionService>();
var chatResult = await chatCompletionService.GetChatMessageContentsAsync(
new ChatHistory
{
new ChatMessageContent(AuthorRole.System, "你是一个C#专家"),
new ChatMessageContent(AuthorRole.User, Prompt)
}
);
这段代码展示了如何利用Semantic Kernel调用AI模型(如DeepSeek)生成代码。关键特点包括:
- 动态生成符合特定接口的代码
- 通过精确的Prompt引导AI生成目标代码
- 温度(Temperature)和TopP参数控制生成的创造性和一致性
随着人工智能技术的普及,如何在资源有限的设备上高效运行大型模型成为关键挑战。本文深入解析不同精度量化技术,帮助你理解AI领域这一重要优化方向。
模型量化:AI轻量化的关键技术
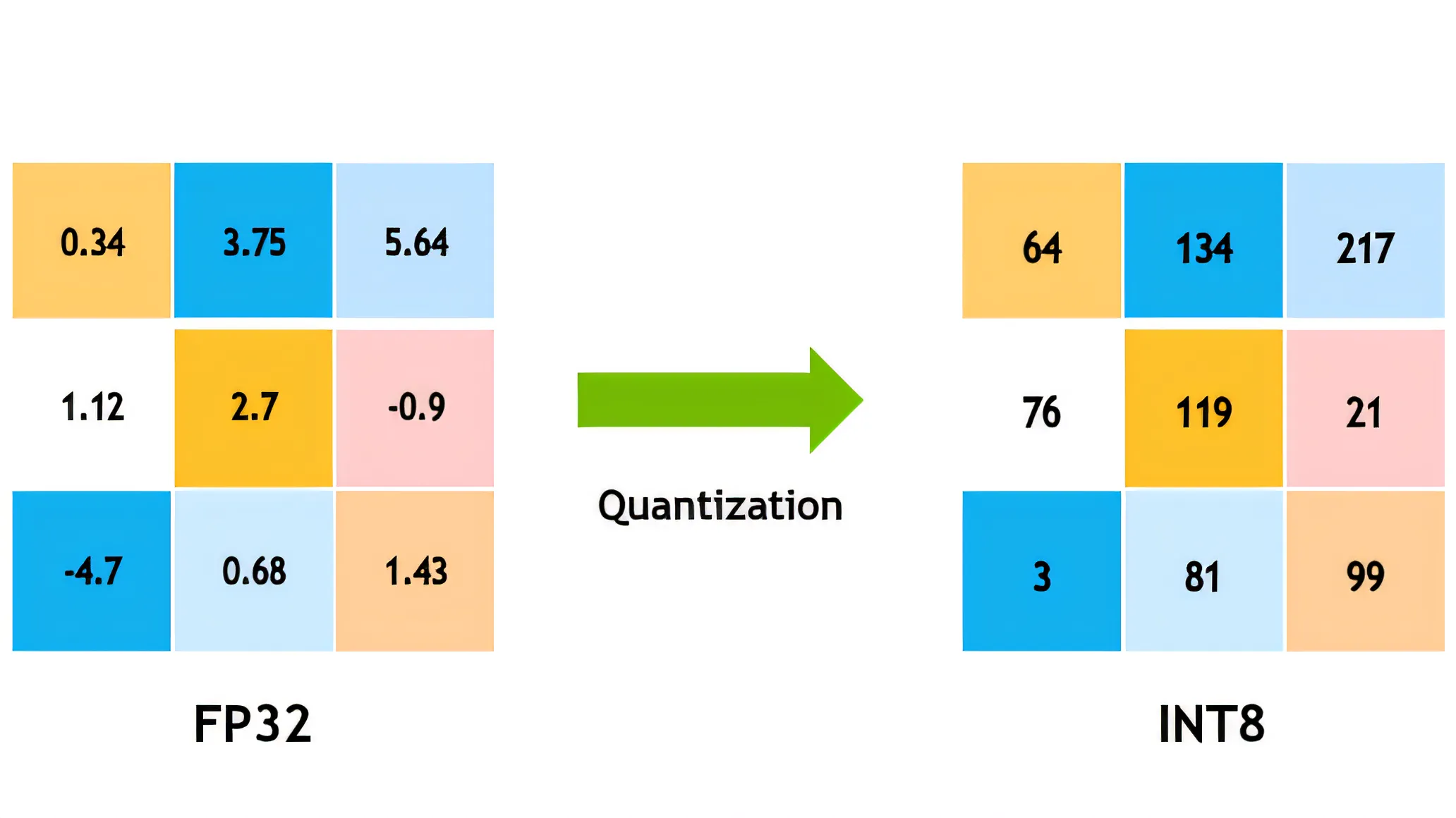
在深度学习领域,模型量化是指将模型参数从高精度表示(如32位浮点数)转换为低精度表示(如16位、8位甚至更低)的过程。这项技术正成为推动AI大模型普及的关键因素,使其能够在手机、IoT设备等计算资源有限的环境中运行。
模型量化的核心优势在于:
- 📱 显著减少模型体积
- ⚡ 加快推理速度
- 🔋 降低能耗
- 💻 减少内存占用
精度等级详解:从16比特到2比特
16比特全参数微调(FP16/BF16)
16比特全参数微调是当前大语言模型训练和微调中的主流选择,它使用半精度浮点数表示模型参数。
- 技术细节:每个参数占用16位内存,相比标准32位浮点数(FP32)减少50%存储空间
- 应用场景:大型语言模型(如GPT、LLaMA)的训练和微调
- 优势:
- 保持较高精度的同时大幅降低显存需求
- 加速训练和推理过程
- 几乎不影响模型性能
- 实际效果:在大多数任务中,16位模型与32位模型表现几乎相同
💡 小贴士:BF16(Brain Floating Point)是Google为机器学习优化的16位格式,与FP16相比具有更大的动态范围。
