摘要
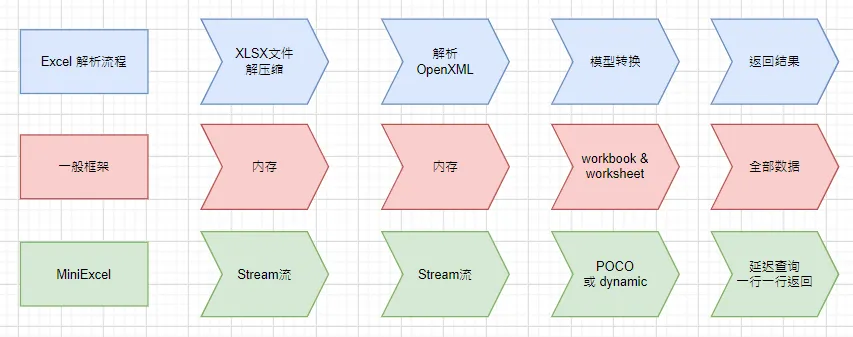
MiniExcel简单、高效避免OOM的.NET处理Excel查、写、填充数据工具。
- 低内存耗用,避免OOM、频繁 Full GC 情况
- 支持
即时操作每行数据 - 兼具搭配 LINQ 延迟查询特性,能办到低消耗、快速分页等复杂查询
- 轻量,不需要安装 Microsoft Office、COM+,DLL小于150KB
- 简便操作的 API 风格
正文
首先,您需要将 MiniExcel 库添加到您的 C# WinForms 项目中。您可以使用 NuGet 包管理器来安装 MiniExcel。
摘要
EPPlus 是一个流行的用于操作 Excel 文件的开源库,适用于 C# 和 .NET 环境。它提供了丰富的功能,能够轻松地读取、写入和格式化 Excel 文件,使得在 C# 中进行 Excel 文件处理变得更加简单和高效。EPPlus 不需要安装 Microsoft Office 或 Excel,因为它完全是用 C# 编写的,并且直接操作 Excel 文件的数据。
支持 Excel 文件格式:EPPlus 支持读取和写入 Office Open XML (XLSX) 格式的 Excel 文件,这是 Microsoft Excel 2007 及以后版本的默认文件格式。它不支持旧的二进制格式(XLS)
正文
EPPlus 是在 MIT 许可下发布的开源项目,因此你可以免费使用和修改它,也可以将其用于商业项目。它的源代码也是公开可用的,你可以自由查看和学习其中的实现细节。
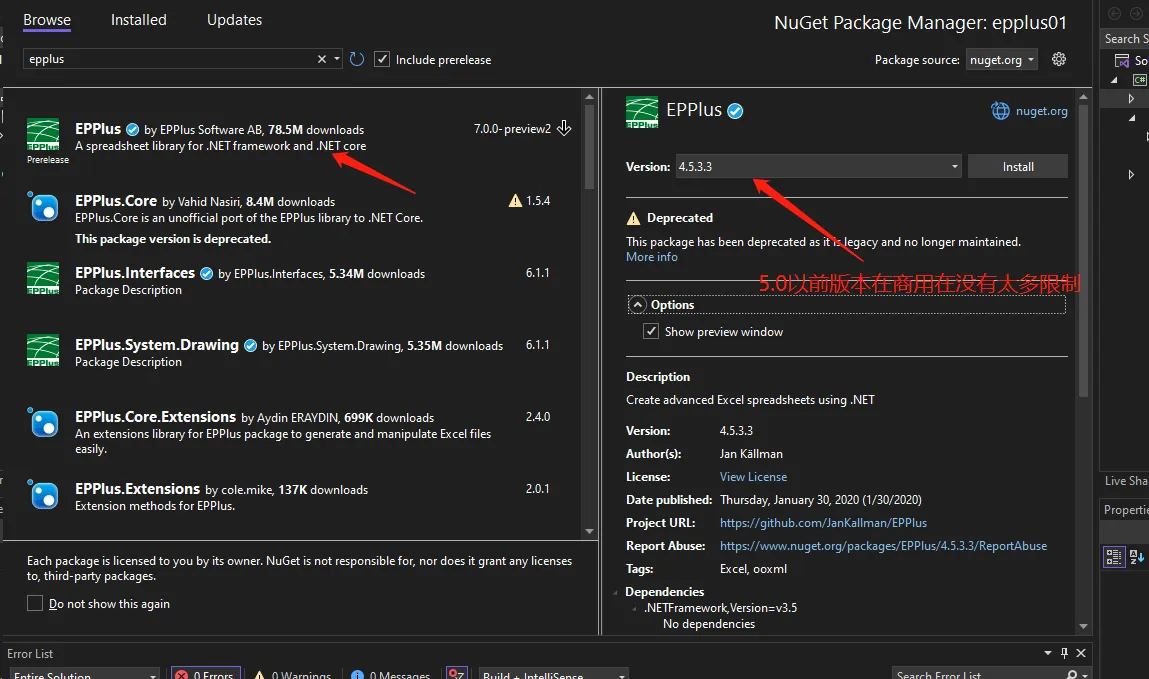
Nuget 安装epplus,这里版本选上我基本就是5.0以前的够用了。
摘要
Worker Service是微软提供的一个项目模板,它基于BackgroundService并且可以在Windows和.NET Core平台上使用。通过使用Worker Service,开发者可以创建跨平台的服务,并且可以使用BackgroundService中的功能,如延迟任务执行和后台任务处理。使用Worker Service的优势在于,它可以轻松地与.NET Core应用程序集成,同时还可以提供可重用的后台任务功能,以帮助开发者更好地管理服务器上的任务。
正文
创建长时间运行的服务的原因有很多,例如:
- 处理 CPU 密集型数据。
- 在后台排队工作项。
- 按计划执行基于时间的操作。
通常,后台服务不需要直接处理用户界面(UI),但可以围绕它们构建UI。在早期的 .NET Framework中,开发人员可以通过创建Windows服务来实现这一点。现在,有了 .NET,您可以使用 BackgroundService,它是 IHostedService 的实现,也可以实现自己的实现。
摘要
串口通信
在.NET平台下创建C#串口通信程序,.NET 2.0提供了串口通信的功能,其命名空间是System.IO.Ports。这个新的框架不但可以访问计算机上的串口,还可以和串口设备进行通信。
创建C#串口通信程序之命名空间 System.IO.Ports命名空间中最重用的是SerialPort 类。 创建C#串口通信程序之创建SerialPort 对象 通过创建SerialPort 对象,我们可以在程序中控制串口通信的全过程。
