作为C#开发者,你是否写过async void方法却不知道隐患?是否忽略了CancellationToken参数导致无法取消长时间运行的操作?在构建高性能应用时,这些看似细微的异步编程细节,往往决定了系统的稳定性和可维护性。
今天分享3个异步编程的专业级技巧,这些都是我在生产环境中踩坑总结的宝贵经验。掌握这些技巧,不仅能避免常见的异步陷阱,还能让你的代码在性能和可靠性方面更上一层楼。
让我们深入探索如何写出真正专业的异步代码!
🚫 避免async void:异步编程的第一原则
❌ async void的致命问题
核心问题: 无法捕获异常,无法等待完成,调用者失去控制权
c#// ❌ 危险写法:异常会导致程序崩溃
public async void ProcessDataDangerous()
{
await Task.Delay(1000);
throw new InvalidOperationException("出错了!"); // 无法被捕获!
}
// ❌ 调用者无法等待完成
public void BadCaller()
{
ProcessDataDangerous(); // 无法知道何时完成
// 可能在操作完成前就继续执行
}
✅ 正确的异步方法设计
c#using System;
using System.Threading.Tasks;
namespace AppAsync3
{
// 自定义异常
public class UserNotFoundException : Exception
{
public UserNotFoundException(string message) : base(message) { }
}
// DTO
public class UserProfile
{
public string Name { get; }
public string Email { get; }
public UserProfile(string name, string email)
{
Name = name;
Email = email;
}
}
// 用户实体
public class User
{
public Guid Id { get; set; }
public string Name { get; set; } = string.Empty;
public string Email { get; set; } = string.Empty;
}
// 仓储接口
public interface IUserRepository
{
Task<User?> FindByIdAsync(Guid userId);
}
// 实现中的一个简单仓储
public class InMemoryUserRepository : IUserRepository
{
// 简单示例数据
private readonly System.Collections.Concurrent.ConcurrentDictionary<Guid, User> _store =
new System.Collections.Concurrent.ConcurrentDictionary<Guid, User>();
public InMemoryUserRepository()
{
// 初始化一个示例用户
var id = Guid.NewGuid();
_store[id] = new User { Id = id, Name = "张三", Email = "zhangsan@example.com" };
// 将一个已知的 ID 暴露出来,便于测试 GetUserProfileAsync
KnownId = id;
}
// 暴露一个已知的存在的 ID,用于测试
public Guid KnownId { get; }
public Task<User?> FindByIdAsync(Guid userId)
{
_store.TryGetValue(userId, out var user);
return Task.FromResult<User?>(user);
}
}
// 日志接口
public interface ILogger
{
void LogError(Exception ex, string message);
}
// 简单控制台日志实现
public class ConsoleLogger : ILogger
{
public void LogError(Exception ex, string message)
{
Console.WriteLine($"ERROR: {message} - {ex}");
}
}
public class DataProcessor
{
private readonly IUserRepository _userRepository;
private readonly ILogger _logger;
public DataProcessor(IUserRepository userRepository, ILogger logger)
{
_userRepository = userRepository;
_logger = logger;
}
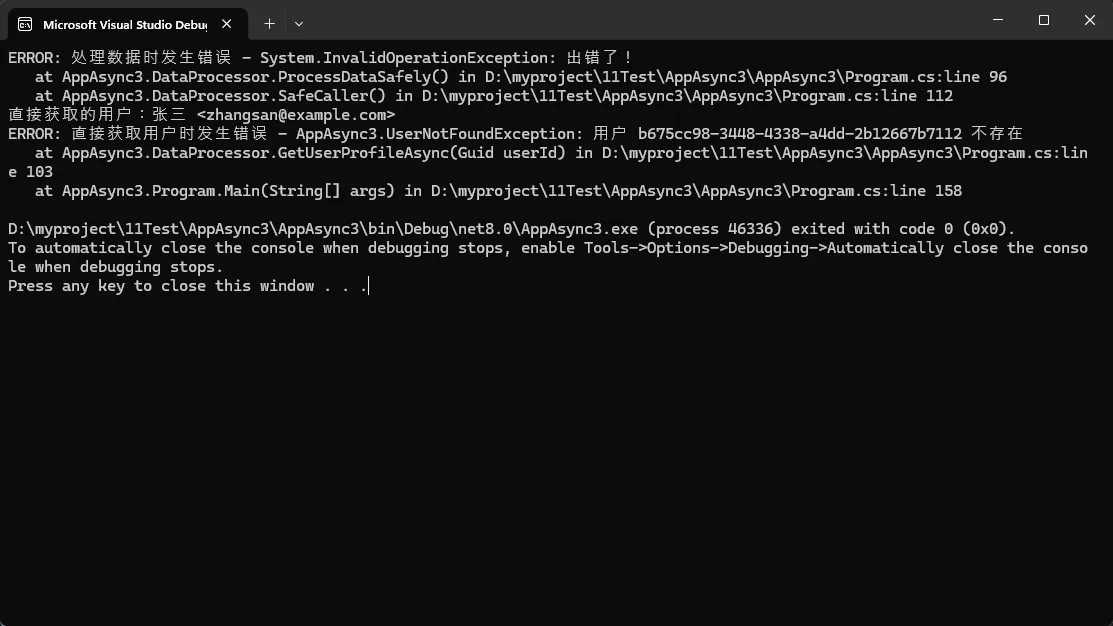
public async Task ProcessDataSafely()
{
// 模拟异步工作
await Task.Delay(1000);
// 异常可以被正确传播和处理
throw new InvalidOperationException("出错了!");
}
public async Task<UserProfile> GetUserProfileAsync(Guid userId)
{
var user = await _userRepository.FindByIdAsync(userId);
if (user == null)
throw new UserNotFoundException($"用户 {userId} 不存在");
return new UserProfile(user.Name, user.Email);
}
public async Task SafeCaller()
{
try
{
await ProcessDataSafely();
if (_userRepository is InMemoryUserRepository inMem && inMem.KnownId != Guid.Empty)
{
var profile = await GetUserProfileAsync(inMem.KnownId);
Console.WriteLine($"User Profile: {profile.Name}, {profile.Email}");
}
else
{
var randomId = Guid.NewGuid();
var profile = await GetUserProfileAsync(randomId);
Console.WriteLine($"User Profile: {profile.Name}, {profile.Email}");
}
}
catch (Exception ex)
{
_logger.LogError(ex, "处理数据时发生错误");
}
}
}
class Program
{
public static async Task Main(string[] args)
{
// 构建依赖
IUserRepository userRepository = new InMemoryUserRepository();
ILogger logger = new ConsoleLogger();
var processor = new DataProcessor(userRepository, logger);
await processor.SafeCaller();
try
{
// 使用已知存在的用户 ID 测试成功路径
if (userRepository is InMemoryUserRepository inMem)
{
var profile = await processor.GetUserProfileAsync(inMem.KnownId);
Console.WriteLine($"直接获取的用户:{profile.Name} <{profile.Email}>");
}
// 使用一个不存在的 ID 测试异常
var nonExistId = Guid.NewGuid();
await processor.GetUserProfileAsync(nonExistId);
}
catch (Exception ex)
{
logger.LogError(ex, "直接获取用户时发生错误");
}
}
}
}
Python Tkinter拖放功能实战:让你的GUI更"丝滑"
在Windows桌面应用开发中,拖放(Drag and Drop)功能已经成为现代GUI的标配——想象一下,如果你不能拖拽文件到应用窗口,是不是感觉回到了上世纪90年代?但很多Python开发者在使用Tkinter时,却发现官方文档对拖放功能语焉不详,甚至找不到直接支持的API。本文将手把手教你在Tkinter中实现完整的拖放功能,涵盖从窗口内部组件拖拽到接收外部文件的所有场景,让你的Python上位机应用体验瞬间升级!
🤔 问题分析:Tkinter原生为什么不支持拖放?
Tkinter的局限性
很多初学者会惊讶地发现:Tkinter本身并不直接支持现代意义上的拖放操作。这是因为:
- 历史包袱:Tkinter基于Tcl/Tk,而Tk最初设计于1990年代,那时拖放功能还不是GUI的标准特性
- 跨平台差异:Windows、macOS、Linux的拖放机制完全不同,Tkinter为了保持跨平台一致性选择了"最小化"策略
- 权限限制:接收外部文件拖放涉及系统级API调用,纯Python实现存在技术障碍
两种典型场景
实际开发中,我们需要处理两类拖放需求:
- 场景一:窗口内拖拽(如拖动列表项调整顺序)
- 场景二:接收外部文件(如拖入图片、文档进行处理)
这两种场景的实现方式完全不同,下面我们逐一攻破。
🛠️ 解决方案一:窗口内部组件拖拽
核心思路
通过监听鼠标事件(ButtonPress、Motion、ButtonRelease),手动实现拖拽逻辑:
鼠标按下 → 记录起始坐标 → 鼠标移动 → 更新组件位置 → 鼠标释放 → 完成拖拽
代码实战:可拖动标签
pythonimport tkinter as tk
class DraggableLabel:
"""可拖动标签类"""
def __init__(self, parent, text, x, y):
self.label = tk.Label(parent, text=text, bg='lightblue',
font=('微软雅黑', 12), padx=10, pady=5,
relief=tk. RAISED, cursor='hand2')
self.label. place(x=x, y=y)
# 记录拖拽起始位置
self._drag_start_x = 0
self._drag_start_y = 0
# 绑定鼠标事件
self.label.bind('<ButtonPress-1>', self. on_drag_start)
self.label.bind('<B1-Motion>', self.on_drag_motion)
self.label.bind('<ButtonRelease-1>', self. on_drag_release)
def on_drag_start(self, event):
"""鼠标按下时记录起始坐标"""
self._drag_start_x = event.x
self._drag_start_y = event.y
self. label.config(relief=tk.SUNKEN) # 视觉反馈
def on_drag_motion(self, event):
"""拖动时实时更新位置"""
# 计算新坐标(相对于父容器)
x = self. label.winfo_x() + event.x - self._drag_start_x
y = self.label.winfo_y() + event.y - self._drag_start_y
self.label.place(x=x, y=y)
def on_drag_release(self, event):
"""释放鼠标时恢复样式"""
self.label. config(relief=tk.RAISED)
# 应用示例
root = tk.Tk()
root.title('组件拖拽演示')
root.geometry('600x400')
root.config(bg='white')
# 创建说明文字
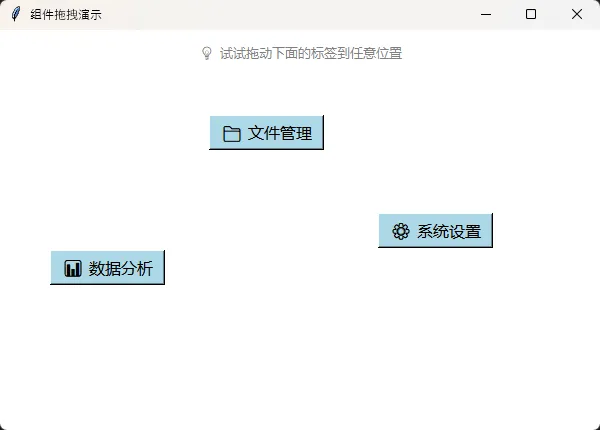
tip = tk.Label(root, text='💡 试试拖动下面的标签到任意位置',
font=('微软雅黑', 10), bg='white', fg='gray')
tip.pack(pady=10)
# 创建多个可拖动标签
DraggableLabel(root, '📁 文件管理', 50, 80)
DraggableLabel(root, '⚙️ 系统设置', 50, 150)
DraggableLabel(root, '📊 数据分析', 50, 220)
root.mainloop()
在高并发系统中,你是否遇到过这样的问题:业务高峰期消息堆积如山,系统濒临崩溃;低峰期资源大量闲置,成本居高不下?作为一名C#开发者,如何优雅地解决这个痛点?
今天我们聊聊削峰填谷——一个能让你的系统在流量洪峰中稳如泰山的神器。通过RabbitMQ + C#的完美组合,我们将构建一个工业级的消息处理系统,让你的应用在面对突发流量时依然从容不迫。
🔍 问题分析:为什么需要削峰填谷?
💥 传统系统的痛点
想象一个电商系统在双11零点的场景:
- 瞬时并发激增:10万用户同时下单,消息队列瞬间爆满
- 资源配置矛盾:按峰值配置浪费成本,按平均值配置扛不住高峰
- 系统雪崩风险:下游处理能力跟不上,整个链路阻塞
c#// ❌ 传统同步处理的问题
public async Task ProcessOrderAsync(Order order)
{
// 直接处理,高峰期会被压垮
await _paymentService.ProcessPaymentAsync(order);
await _inventoryService.UpdateStockAsync(order);
await _notificationService.SendConfirmationAsync(order);
}
🎯 削峰填谷的核心思想
削峰填谷就是在系统中加入一个智能缓冲区:
- 削峰:高峰期将消息暂存,避免系统过载
- 填谷:低峰期加速处理,提高资源利用率
- 平滑:让不规则的流量变得平稳可控
💡 解决方案:RabbitMQ + C#削峰填谷架构
🏗️ 整体架构设计
markdown[消息生产者] → [RabbitMQ交换机] → [削峰填谷服务] → [业务处理]
↓
[智能缓冲区]
↓
[批量处理器]
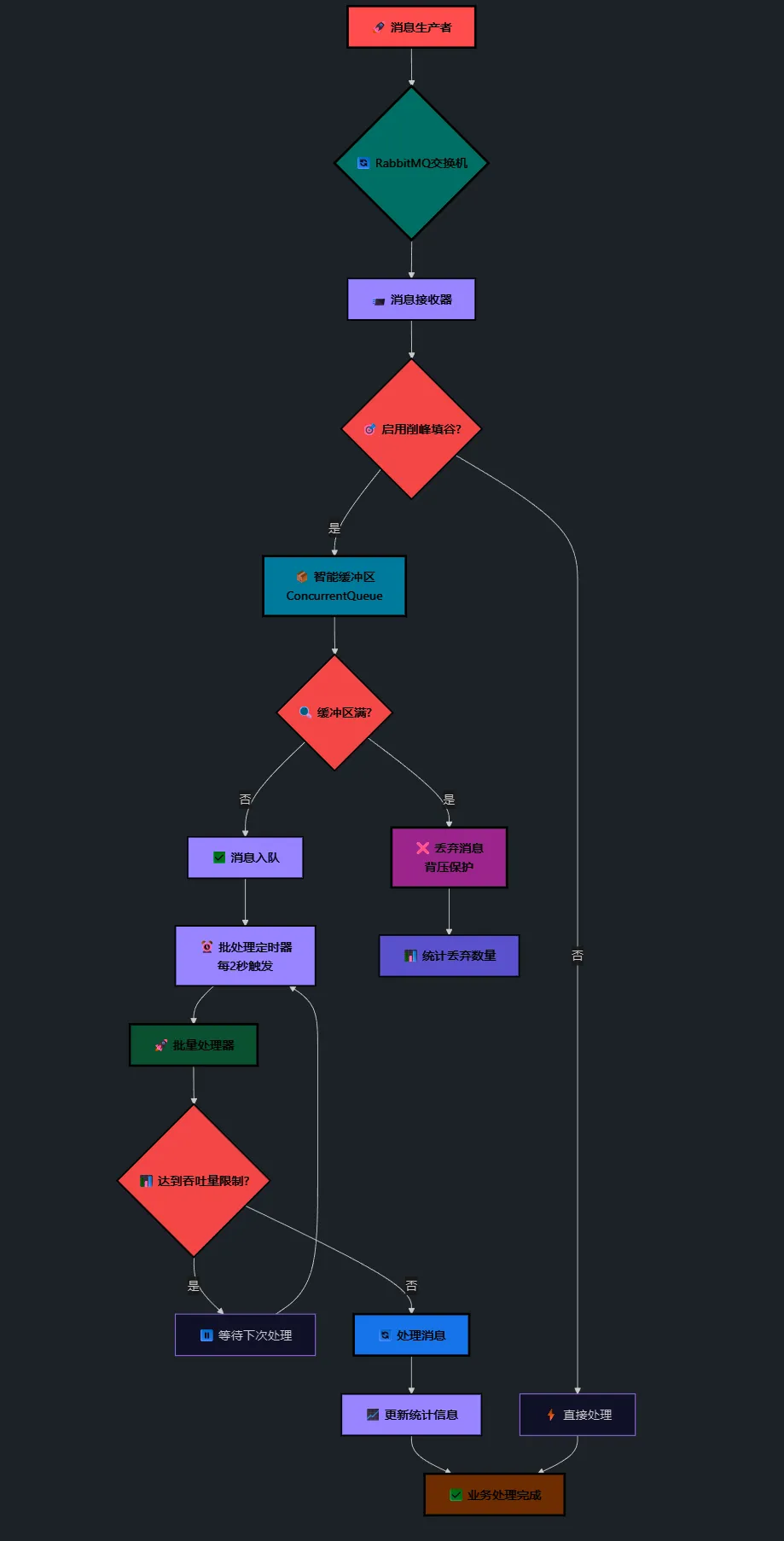
🔧 核心组件解析
1. 智能缓冲区:使用ConcurrentQueue存储待处理消息
2. 批量处理器:定时批量消费,控制处理速率
3. 动态配置:实时调整缓冲区大小和处理频率
4. 监控统计:实时监控系统健康状态
🌱 开头:大模型火了,但很多人其实没搞懂
这两年,只要谈技术,绕不开两个词:AI 和大模型。
开会会上,领导说“要用大模型赋能业务”;方案评审时,PPT上写着“打造企业级大模型平台”;朋友圈里则是一串“xxCopilot”“智能体”“RAG”“长上下文”。
但冷静下来问一句:什么叫“大模型”?
它到底大在哪?为什么大家都说它要“重构软件开发范式”“颠覆内容生产方式”?
更现实一点——和你手上的业务、KPI、性能指标,到底有什么直接关系?
不少同学心里其实是这样的:
- 觉得大模型“很神奇”,但一落地就变成“问答机器人”,用几天就没人理。
- 以为接了某个云厂商 API,就算“完成大模型改造”,结果效果平平,还被质疑“花架子”。
- 做技术的一肚子焦虑:不会大模型,好像就要被时代甩下;真做项目,又不知道从哪儿下手。
这篇文章,我们不讲玄学,也不过度追热点。
就围绕一个问题展开——从工程视角,什么是大模型,它给业务带来的“真实价值”究竟是什么?
同时,结合一个具体代表——通义千问——来拆解参数、版本号、上下文、Turbo、Preview、视觉能力这些标签到底在说啥。
🤯 一、问题深度剖析:大模型的三大“认知错位”
1️⃣ 错位一:把“大模型”当成“高级聊天机器人”
很多团队第一次接触大模型,是通过 ChatGPT、通义千问、文心一言、Claude 这一类产品。久而久之,会形成一个潜意识:大模型 = 会聊天的搜索增强版。
这会带来三个直接误区:
- 只做“问答Bot”,不做“业务能力”
- 典型表现:只在官网或App里放一个“智能客服”,问问就结束了。
- 没有把大模型真正接入订单、库存、风控、工单等业务系统。
- 只看“能不能答”,不看“答得有没有用”
- 满足于“模型能说话”,而不是“模型能帮你做成事”。
- 比如,它会写一段 SQL,但字段名、库名全是瞎编的——看起来很聪明,用起来很危险。
- 只堆提示词,不做工程化治理
- 业务方说:“再给它加几句提示试试。”
- 最后成了提示词泥石流,却没有日志、评测、迭代闭环。
结果:项目上线了,体验花哨,业务指标却没有明显起色。
在高并发的C#应用中,日志记录往往是性能瓶颈的"隐形杀手"。传统的字符串拼接和反射调用在每秒处理数万次日志时,会严重拖累系统响应速度。
你是否遇到过这些痛点?
- 手写EventSource代码繁琐易错?
- ILogger使用不当导致性能下降?
- 日志代码重复冗余,维护成本高?
- 敏感数据意外泄露到日志中?
今天带来一个Source Generator解决方案,让你通过简单的接口定义,自动生成高性能的EventSource和ILogger包装器,性能提升10倍以上!
🎯 问题分析:传统日志记录的性能陷阱
性能杀手1:字符串拼接
C#// ❌ 传统写法 - 每次都要拼接字符串
logger.LogInformation($"用户{userId}从{ipAddress}登录成功,耗时{duration}ms");
性能杀手2:装箱开销
C#// ❌ 值类型装箱,产生GC压力
logger.LogInformation("处理订单{orderId},金额{amount}", orderId, amount);
性能杀手3:反射调用
C#// ❌ 运行时类型检查和方法查找
logger.LogError(exception, "系统异常");
测试数据显示:传统方式在高频日志场景下,CPU占用率可达30-40%,而优化后的EventSource仅需3-5%!
💡 解决方案:Source Generator自动生成
🔧 核心思路
通过编译时代码生成替代运行时反射,用结构化参数替代字符串拼接,实现零开销日志记录。
📦 项目架构
MarkdownLoggingGenerator/ ├── Attributes/ # 特性定义 ├── Generator/ # Source Generator实现 └── Demo/ # 演示项目
🔥 代码实战:3步搞定高性能日志
第1步:定义日志接口
C#using LoggingGenerator.Attributes;
using Microsoft.Extensions.Logging;
namespace LoggingGenerator.Demo
{
[LoggingEventSource(Name = "OrderService", Guid = "12345678-1234-1234-1234-123456789ABC")]
[LoggingWrapper(CategoryName = "OrderService")]
public interface IOrderService
{
[LogEvent(1001, Level = LogLevel.Information, Message = "订单 {orderId} 创建成功,金额:{amount}")]
void OrderCreated(string orderId, decimal amount);
[LogEvent(1002, Level = LogLevel.Warning, Message = "订单 {orderId} 支付失败:{reason}")]
void PaymentFailed(string orderId, string reason, [LogParameter(Sensitive = true)] string cardNumber);
[LogEvent(1003, Level = LogLevel.Error, Message = "订单处理出现异常")]
void OrderError(string orderId, Exception exception, [LogParameter(Skip = true)] object debugInfo);
[LogEvent(1004, Level = LogLevel.Debug)]
void OrderStatusChanged(string orderId, string fromStatus, string toStatus);
}
}
