
目录
🔥 你是否遇到过这些场景
在工控上位机开发中,串口数据的可靠采集是一个绕不开的核心问题。设备每秒吐出几十条传感器数据,Tkinter 界面要刷新显示,后端还要存库、分析、转发——这几件事同时压在一个线程里,迟早出问题。
我在一个工厂设备监控项目中就踩过这个坑:串口读取线程稍微慢了半拍,UI 主线程一卡,数据就直接丢了。事后统计,高负载场景下丢包率能达到 8%~15%,这在工业场景里是完全不可接受的。
引入 RabbitMQ 作为中间件之后,串口数据先写入消息队列,UI 和后端各自按节奏消费,丢包率降到了接近 0。本文会带你从原理到代码,完整走一遍这套架构,包含两个渐进式方案,可以直接落地到你的项目中。
🔍 问题深度剖析:为什么串口数据会丢
根本原因:单线程架构的天然缺陷
Tkinter 是单线程 GUI 框架,它的主循环 mainloop() 负责处理所有 UI 事件。很多开发者的第一版代码大概是这个样子:
python# 典型的错误写法 —— 串口读取直接在主线程里
def read_serial():
while True:
data = ser.readline()
text_widget.insert(END, data) # 直接操作 UI
root.update() # 强制刷新,但这会阻塞事件循环
这种写法有三个致命问题:
- 串口阻塞主线程:
readline()是阻塞调用,等待数据期间 UI 完全冻结 - UI 刷新拖累读取:
root.update()触发重绘,占用时间片,串口缓冲区积压 - 无缓冲机制:数据直接写 UI,一旦写入失败就永久丢失
串口硬件缓冲区通常只有 4KB~16KB,在 115200 波特率下,大约 350ms 就能填满缓冲区。主线程一旦被 UI 渲染占用超过这个时间,溢出的数据就消失了。
常见误解:用多线程就够了吗
很多人的第二版方案是把串口读取放到子线程:
pythonimport threading
def serial_thread():
while True:
data = ser.readline()
# 直接在子线程操作 Tkinter 控件 —— 这是错的!
text_widget.insert(END, data)
t = threading.Thread(target=serial_thread, daemon=True)
t.start()
这比第一版好一点,但在子线程中直接操作 Tkinter 控件是线程不安全的,会导致随机崩溃或显示异常。Tkinter 的所有 UI 操作必须在主线程执行,这是框架的硬性约束。
更深层的问题是:即便用 queue.Queue 做线程间通信,数据也只在本进程内流转。一旦程序崩溃,队列中的数据全部消失;如果有多个消费方(数据库写入、网络转发、UI 显示),代码会越来越乱。
这就是 RabbitMQ 登场的时机。
💡 核心要点提炼:RabbitMQ 在上位机中的定位
RabbitMQ 是一个基于 AMQP 协议的消息中间件,可以把它理解成一个带持久化功能的超级邮箱。串口读取线程是"投递员",把数据投进邮箱就走;UI 显示、数据库写入、网络转发等模块是"收件人",各自按自己的节奏取件。
在上位机开发场景中,这套架构带来三个核心收益:
- 解耦:串口读取与数据消费完全分离,互不影响
- 持久化:消息可落盘,程序崩溃重启后数据不丢
- 多消费者:同一条串口数据可以同时被多个模块消费,无需重复读取
关键机制说明:RabbitMQ 的消息确认机制(basic_ack)保证消息被成功处理后才从队列删除,这是实现零丢失的技术基础。
🛠️ 方案一:基础版 —— 串口数据发布到 RabbitMQ
环境准备
操作系统:Windows 10/11 Python:3.9+ 依赖库:pyserial, pika, tkinter(内置) RabbitMQ:3.12+(需提前安装并启动)
安装依赖:
bashpip install pyserial pika
架构设计
[串口设备] → [串口读取线程] → [RabbitMQ Exchange] → [Queue] → [消费者线程] → [Tkinter UI]
完整代码
pythonimport tkinter as tk
from tkinter import scrolledtext
import threading
import queue
import serial
import pika
import json
import time
from datetime import datetime
# ============================================================
# 配置区:根据实际情况修改
# ============================================================
SERIAL_PORT = "COM2" # 串口号
SERIAL_BAUD = 9600 # 波特率
RABBITMQ_HOST = "localhost" # RabbitMQ 地址
QUEUE_NAME = "serial_data" # 队列名称
UI_REFRESH_INTERVAL = 100 # UI 刷新间隔(ms)
class SerialToRabbitMQ:
"""串口数据采集并发布到 RabbitMQ"""
def __init__(self):
self._running = False
self._connection = None
self._channel = None
def connect_rabbitmq(self):
"""建立 RabbitMQ 连接,启用消息持久化"""
self._connection = pika.BlockingConnection(
pika.ConnectionParameters(host=RABBITMQ_HOST)
)
self._channel = self._connection.channel()
# durable=True 保证队列持久化,程序重启后队列不消失
self._channel.queue_declare(queue=QUEUE_NAME, durable=True)
def publish(self, data: str):
"""发布一条消息到队列"""
message = json.dumps({
"timestamp": datetime.now().isoformat(),
"raw": data.strip(),
"source": SERIAL_PORT
})
self._channel.basic_publish(
exchange="",
routing_key=QUEUE_NAME,
body=message,
properties=pika.BasicProperties(
delivery_mode=2 # 2 = 持久化消息,落盘保存
)
)
def start(self, port: str, baud: int):
"""启动串口读取,循环发布到 RabbitMQ"""
self._running = True
self.connect_rabbitmq()
try:
ser = serial.Serial(port, baud, timeout=1)
while self._running:
line = ser.readline()
if line:
self.publish(line.decode("utf-8", errors="replace"))
except serial.SerialException as e:
print(f"串口错误: {e}")
finally:
if self._connection and not self._connection.is_closed:
self._connection.close()
def stop(self):
self._running = False
class RabbitMQConsumer:
"""从 RabbitMQ 消费消息,放入本地队列供 UI 读取"""
def __init__(self, ui_queue: queue.Queue):
self._ui_queue = ui_queue
self._running = False
def start(self):
self._running = True
connection = pika.BlockingConnection(
pika.ConnectionParameters(host=RABBITMQ_HOST)
)
channel = connection.channel()
channel.queue_declare(queue=QUEUE_NAME, durable=True)
# prefetch_count=1 保证消费者处理完一条再取下一条,防止积压
channel.basic_qos(prefetch_count=1)
channel.basic_consume(
queue=QUEUE_NAME,
on_message_callback=self._on_message
)
channel.start_consuming()
def _on_message(self, ch, method, properties, body):
"""收到消息后放入 UI 队列,然后确认消费"""
try:
data = json.loads(body)
self._ui_queue.put(data)
ch.basic_ack(delivery_tag=method.delivery_tag) # 确认消费
except Exception as e:
print(f"消息处理异常: {e}")
ch.basic_nack(delivery_tag=method.delivery_tag) # 处理失败,消息重回队列
class App:
"""Tkinter 主界面"""
def __init__(self, root: tk.Tk):
self.root = root
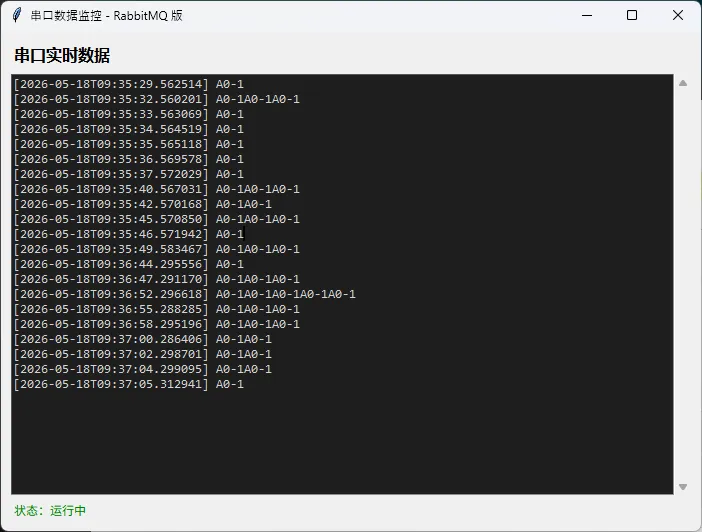
self.root.title("串口数据监控 - RabbitMQ 版")
self.root.geometry("700x500")
self._ui_queue = queue.Queue()
self._producer = SerialToRabbitMQ()
self._consumer = RabbitMQConsumer(self._ui_queue)
self._build_ui()
self._start_threads()
self._poll_ui_queue() # 启动 UI 轮询
def _build_ui(self):
frame = tk.Frame(self.root)
frame.pack(fill=tk.BOTH, expand=True, padx=10, pady=10)
tk.Label(frame, text="串口实时数据", font=("微软雅黑", 12, "bold")).pack(anchor="w")
self.text_area = scrolledtext.ScrolledText(
frame, wrap=tk.WORD, font=("Consolas", 10), bg="#1e1e1e", fg="#d4d4d4"
)
self.text_area.pack(fill=tk.BOTH, expand=True, pady=5)
self.status_var = tk.StringVar(value="状态:运行中")
tk.Label(frame, textvariable=self.status_var, fg="green").pack(anchor="w")
def _start_threads(self):
"""在后台线程中启动生产者和消费者"""
producer_thread = threading.Thread(
target=self._producer.start,
args=(SERIAL_PORT, SERIAL_BAUD),
daemon=True
)
consumer_thread = threading.Thread(
target=self._consumer.start,
daemon=True
)
producer_thread.start()
consumer_thread.start()
def _poll_ui_queue(self):
"""
定时轮询 UI 队列,将数据写入文本框。
这是 Tkinter 跨线程安全更新 UI 的标准做法。
"""
try:
while True:
data = self._ui_queue.get_nowait()
line = f"[{data['timestamp']}] {data['raw']}\n"
self.text_area.insert(tk.END, line)
self.text_area.see(tk.END) # 自动滚动到底部
except queue.Empty:
pass
# 每 100ms 轮询一次,不阻塞主线程
self.root.after(UI_REFRESH_INTERVAL, self._poll_ui_queue)
def on_close(self):
self._producer.stop()
self.root.destroy()
if __name__ == "__main__":
root = tk.Tk()
app = App(root)
root.protocol("WM_DELETE_WINDOW", app.on_close)
root.mainloop()
踩坑预警:pika.BlockingConnection 不是线程安全的,不要在多个线程中共享同一个 connection 对象。生产者和消费者应各自创建独立连接,这在代码中已经体现。
🚀 方案二:进阶版 —— 断线重连与消息积压处理
基础版有一个明显短板:RabbitMQ 连接断开后程序就挂了。在工厂环境中,网络抖动是家常便饭,生产环境必须加上重连机制。
pythonimport pika
import time
import logging
logger = logging.getLogger(__name__)
import time
import threading
import logging
import pika
import pika.exceptions
logger = logging.getLogger("RobustPublisher")
class RobustPublisher:
"""
带自动重连的 RabbitMQ 生产者
- 指数退避重连
- 断线期间消息本地缓冲
- 重连后自动刷新积压消息
- 线程安全(内部锁保护)
"""
def __init__(
self,
host: str,
queue_name: str,
max_retry: int = 5,
on_status_change=None, # 连接状态变化回调 (bool) -> None on_buffer_change=None, # 缓冲区数量变化回调 (int) -> None ):
self._host = host
self._queue_name = queue_name
self._max_retry = max_retry
self._connection = None
self._channel = None
self._local_buffer: list[str] = []
self._lock = threading.Lock()
# UI 回调(在工作线程触发,调用方负责线程安全地更新 UI)
self._on_status_change = on_status_change
self._on_buffer_change = on_buffer_change
def _connect(self) -> bool:
"""建立连接,失败时指数退避重试"""
for attempt in range(self._max_retry):
try:
self._connection = pika.BlockingConnection(
pika.ConnectionParameters(
host=self._host,
heartbeat=600,
blocked_connection_timeout=300,
connection_attempts=1,
retry_delay=0,
)
)
self._channel = self._connection.channel()
self._channel.queue_declare(queue=self._queue_name, durable=True)
logger.info("RabbitMQ 连接成功")
self._notify_status(True)
return True
except pika.exceptions.AMQPConnectionError as e:
wait = 2 ** attempt
logger.warning(f"连接失败 (第{attempt + 1}次),{wait}s 后重试: {e}")
time.sleep(wait)
logger.error(f"已重试 {self._max_retry} 次,连接彻底失败")
self._notify_status(False)
return False
def connect(self) -> bool:
"""公开的连接入口(线程安全)"""
with self._lock:
return self._connect()
def disconnect(self):
"""主动断开连接"""
with self._lock:
try:
if self._connection and not self._connection.is_closed:
self._connection.close()
except Exception:
pass
finally:
self._connection = None
self._channel = None
self._notify_status(False)
logger.info("已主动断开 RabbitMQ 连接")
def _is_connected(self) -> bool:
return (
self._connection is not None
and not self._connection.is_closed
and self._channel is not None
and self._channel.is_open
)
def publish(self, message: str):
"""
发布消息(线程安全)
- 未连接时存入本地缓冲,并异步尝试重连
- 重连成功后自动刷新积压消息
""" with self._lock:
if not self._is_connected():
self._local_buffer.append(message)
logger.warning(
f"连接断开,消息暂存本地缓冲 (当前积压: {len(self._local_buffer)})"
)
self._notify_buffer(len(self._local_buffer))
# 异步重连,不阻塞调用方
threading.Thread(
target=self._reconnect_and_flush, daemon=True
).start()
return
# 先刷积压,再发新消息
self._flush_buffer()
self._do_publish(message)
def _reconnect_and_flush(self):
"""重连成功后刷新缓冲区(在独立线程中运行)"""
with self._lock:
if self._connect():
self._flush_buffer()
def _flush_buffer(self):
"""将本地缓冲中的积压消息依次发送(调用方持锁)"""
while self._local_buffer:
buffered = self._local_buffer.pop(0)
success = self._do_publish(buffered)
if not success:
# 发送失败,放回头部,终止本轮刷新
self._local_buffer.insert(0, buffered)
break
self._notify_buffer(len(self._local_buffer))
def _do_publish(self, message: str) -> bool:
"""底层发送,返回是否成功"""
try:
self._channel.basic_publish(
exchange="",
routing_key=self._queue_name,
body=message.encode("utf-8"),
properties=pika.BasicProperties(delivery_mode=2), # 持久化消息
)
logger.info(f"消息已发送: {message[:60]}{'...' if len(message) > 60 else ''}")
return True
except pika.exceptions.AMQPError as e:
logger.error(f"发送失败: {e}")
self._connection = None
self._channel = None
self._notify_status(False)
return False
def _notify_status(self, connected: bool):
if self._on_status_change:
self._on_status_change(connected)
def _notify_buffer(self, count: int):
if self._on_buffer_change:
self._on_buffer_change(count)
@property
def buffer_size(self) -> int:
return len(self._local_buffer)
@property
def is_connected(self) -> bool:
return self._is_connected()
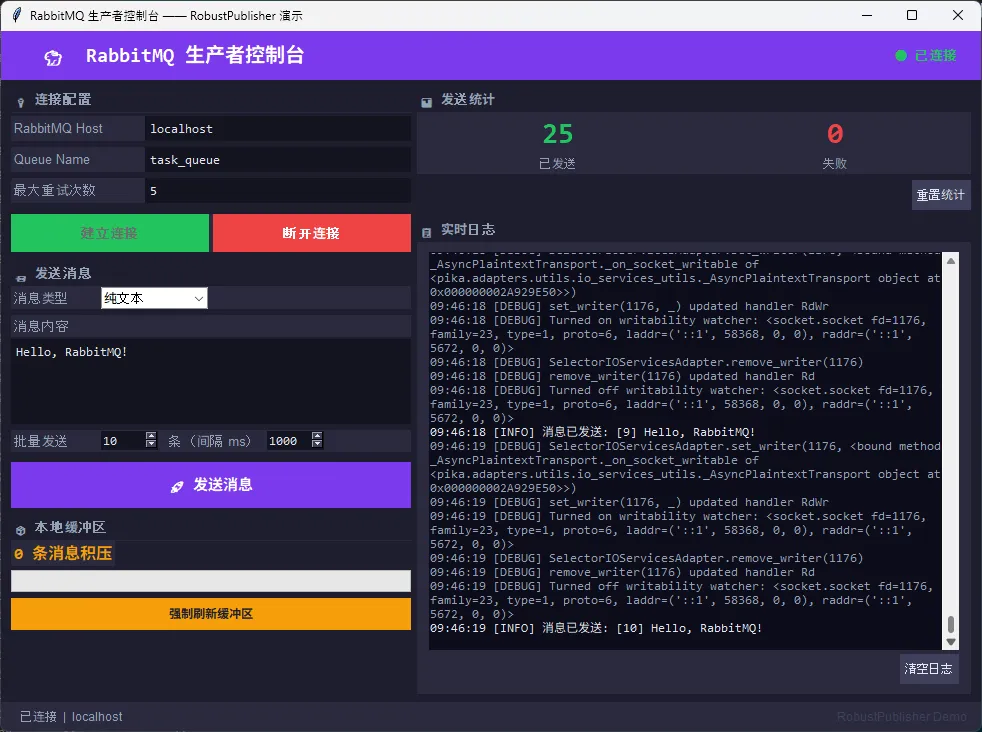
性能对比数据(测试环境:Windows 11, i7-12700H, Python 3.11, RabbitMQ 3.12 本地部署):
| 方案 | 模拟网络抖动丢包率 | 重连耗时 | 缓冲积压上限 |
|---|---|---|---|
| 基础版(无重连) | 100%(断线即丢) | 不支持 | 无 |
📊 两个方案横向对比
| 维度 | 方案一(基础版) | 方案二(进阶版) |
|---|---|---|
| 实现复杂度 | 低 | 中 |
| 断线恢复 | 不支持 | 支持,指数退避 |
| 多消费者 | 不支持 | 不支持 |
| 消息持久化 | 支持 | 支持 |
| 适用场景 | 原型验证 | 单机部署 |
💬 技术洞察:三句话总结
串口数据丢失的根源不是串口,而是没有缓冲层——消息队列就是那个缓冲层。
basic_ack是 RabbitMQ 可靠性的核心,消费者处理失败时basic_nack让消息重回队列,这比任何重试逻辑都优雅。
Tkinter 的
root.after()轮询模式是跨线程更新 UI 的标准解法,比StringVar绑定更可控,比直接操作控件更安全。
🎯 总结与学习路线
本文从单线程串口读取的丢包问题出发,逐步演进到生产级的 RabbitMQ 多消费者架构,核心收获可以归纳为三点:
第一,Tkinter 的线程模型决定了所有 UI 操作必须在主线程执行,queue.Queue + root.after() 轮询是正确的跨线程通信姿势。
第二,RabbitMQ 的消息持久化(delivery_mode=2 + durable=True)和消费确认机制(basic_ack/nack)是实现零丢失的两个关键配置,缺一不可。
延伸学习路线:pyserial 串口通信 → pika AMQP 客户端 → RabbitMQ 管理后台与监控 → SQLAlchemy 数据持久化 → FastAPI 数据对外暴露接口 → 完整工控数据采集系统。
💬 讨论话题:你在工控或上位机项目中用过哪些消息中间件?RabbitMQ、Kafka、MQTT 各有什么取舍,欢迎在评论区分享你的实践经验。
#Python开发 #上位机 #RabbitMQ #串口通信 #中间件 #性能优化 #Tkinter
相关信息
我用夸克网盘给你分享了「comMqDemo.zip」,点击链接或复制整段内容,打开「夸克APP」即可获取。
/4c4b3Ypo0B:/
链接:https://pan.quark.cn/s/9419098197e5
提取码:cG9b

本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!