
目录
🎯 你真的选对数据库了吗?
做上位机开发这几年,见过太多项目在数据库选型上走弯路。有人图省事直接上 SQL Server Express,结果部署到客户现场发现安装包将近 500MB,客户机器还跑着 Windows 7 精简版,当场翻车。也有人用 SQLite 撑起了日志系统,结果并发写入量一上来,数据丢失问题让整个项目险些烂尾。
数据库选型,从来不是"哪个更好",而是"哪个更合适"。
上位机软件有其独特的运行环境:工控现场网络隔离、客户机器配置参差不齐、数据读写模式高度集中、部署维护成本极度敏感。这些约束条件,决定了你的选型逻辑必须和普通业务系统完全不同。
读完这篇文章,你将掌握:
- SQLite 与 SQL Server Express 在上位机场景下的真实性能差异
- 两种数据库的架构接入方案与完整代码示例
- 一套可直接复用的选型决策框架,覆盖 80% 的上位机项目场景
🔍 问题深度剖析:上位机数据库的三大特殊挑战
挑战一:部署环境的不可控性
上位机不像 Web 系统,可以跑在你精心配置的服务器上。它要面对的是:老旧的工控机、精简版 Windows、有时候连 .NET 运行时都需要手动安装的现场环境。SQL Server Express 的安装程序超过 400MB,安装过程还依赖 VC++ 运行时、.NET Framework 特定版本,在网络隔离的工厂现场,这个安装过程可以让工程师在现场耗掉大半天。
SQLite 的整个核心库只有一个 DLL,不到 2MB,通过 NuGet 引入后直接打包进发布目录,零依赖、零配置,这一点在上位机场景里的价值被严重低估。
挑战二:数据读写的特殊模式
上位机的数据读写模式极为集中,通常是:高频小批量写入(采集数据)+ 低频大批量读取(报表查询)。一台设备每秒采集 10 个点位,24 小时运行下来一天就是 864,000 条记录。这种写入密度对 SQLite 的单写锁机制是个考验,但对 SQL Server Express 来说,其进程级的资源消耗又显得大材小用。
挑战三:维护成本的现实压力
上位机软件交付后,往往面临"无人运维"的现实。客户没有 DBA,出了问题只能靠电话远程指导。SQLite 的数据库就是一个文件,备份就是复制文件,恢复就是粘贴文件,这种简单性在实际维护中价值极高。SQL Server Express 的备份恢复流程对普通操作员来说门槛较高,一旦出现数据库损坏,远程处理的难度成倍增加。
💡 核心要点提炼:两者的本质差异
在深入代码之前,先把两者的核心架构差异说清楚,这是选型判断的基础。
SQLite 是进程内嵌入式数据库,没有独立的服务进程,数据库文件直接由应用程序读写。它的并发模型是"写时独占锁",同一时刻只允许一个写操作,读操作可以并发。这个设计在单应用场景下几乎没有问题,但多进程并发写入时会产生锁争用。
SQL Server Express 是完整的客户端-服务器架构,有独立的 sqlservr.exe 进程,通过 TCP 或命名管道与应用通信。它支持完整的事务隔离级别、行级锁、并发控制,是真正意义上的关系型数据库引擎。代价是:资源占用高(即使空载也会占用 200MB+ 内存),启动慢,部署复杂。
| 对比维度 | SQLite | SQL Server Express |
|---|---|---|
| 部署方式 | 单 DLL,零配置 | 独立服务进程,需安装 |
| 安装包大小 | ~2MB | ~400MB+ |
| 内存占用(空载) | 极低(随应用进程) | 200~400MB |
| 并发写入 | 写时独占锁 | 行级锁,支持高并发 |
| 最大数据库大小 | 281TB(理论) | 10GB(Express 限制) |
| 事务支持 | 完整 ACID | 完整 ACID |
| 远程连接 | 不支持 | 支持 |
| 维护难度 | 极低 | 中等 |
测试环境说明:以下性能数据基于 i7-10700 / 32GB RAM / SSD 环境,Windows 11 ,SQLite 3.42 / SQL Server Express 2022,.NET 10.0,单线程顺序写入测试。
🛠️ 解决方案设计
方案一:SQLite 高性能接入(适合单机采集场景)
这是上位机项目最常见的场景:单台设备、本地存储、无需远程访问。SQLite 完全胜任,但有几个关键配置必须做对,否则性能会差几十倍。
很多人用 SQLite 写入慢,根本原因是没有开启 WAL 模式,也没有用批量事务。下面这个封装把这些坑都堵上了。
csharp// SQLiteDataService.cs
// 适用场景:单机上位机,高频采集数据写入
// 依赖:Microsoft.Data.Sqlite(NuGet)
using Microsoft.Data.Sqlite;
using System.IO;
using System.Threading;
namespace AppWpf202606;
public sealed class SqliteDeviceDataRepository : IDeviceDataRepository, IDisposable
{
private readonly SqliteConnection _connection;
private readonly SemaphoreSlim _gate = new(1, 1);
public SqliteDeviceDataRepository(SqliteSettings settings)
{
var fullPath = Path.GetFullPath(settings.DbPath);
var dir = Path.GetDirectoryName(fullPath);
if (!string.IsNullOrWhiteSpace(dir))
{
Directory.CreateDirectory(dir);
}
var connectionString = $"Data Source={fullPath};Mode=ReadWriteCreate;Cache=Shared";
_connection = new SqliteConnection(connectionString);
_connection.Open();
InitializeDatabase();
}
private void InitializeDatabase()
{
using var cmd = _connection.CreateCommand();
cmd.CommandText = "PRAGMA journal_mode=WAL;";
cmd.ExecuteNonQuery();
cmd.CommandText = "PRAGMA synchronous=NORMAL;";
cmd.ExecuteNonQuery();
cmd.CommandText = "PRAGMA cache_size=-65536;";
cmd.ExecuteNonQuery();
cmd.CommandText = @"
CREATE TABLE IF NOT EXISTS DeviceData (
Id INTEGER PRIMARY KEY AUTOINCREMENT,
DeviceId TEXT NOT NULL,
TagName TEXT NOT NULL,
Value REAL NOT NULL,
Timestamp INTEGER NOT NULL
);
CREATE INDEX IF NOT EXISTS idx_device_time
ON DeviceData(DeviceId, Timestamp DESC);";
cmd.ExecuteNonQuery();
}
public async Task InsertBatchAsync(IEnumerable<DeviceDataPoint> points)
{
await _gate.WaitAsync();
try
{
await using var transaction = (SqliteTransaction)await _connection.BeginTransactionAsync();
await using var cmd = _connection.CreateCommand();
cmd.Transaction = transaction;
cmd.CommandText = @"
INSERT INTO DeviceData (DeviceId, TagName, Value, Timestamp)
VALUES (@deviceId, @tagName, @value, @timestamp);";
var pDeviceId = cmd.Parameters.Add("@deviceId", SqliteType.Text);
var pTagName = cmd.Parameters.Add("@tagName", SqliteType.Text);
var pValue = cmd.Parameters.Add("@value", SqliteType.Real);
var pTimestamp = cmd.Parameters.Add("@timestamp", SqliteType.Integer);
foreach (var point in points)
{
pDeviceId.Value = point.DeviceId;
pTagName.Value = point.TagName;
pValue.Value = point.Value;
pTimestamp.Value = point.Timestamp;
await cmd.ExecuteNonQueryAsync();
}
await transaction.CommitAsync();
}
finally
{
_gate.Release();
}
}
public async Task<List<DeviceDataPoint>> QueryRangeAsync(string deviceId, long start, long end)
{
var result = new List<DeviceDataPoint>();
await _gate.WaitAsync();
try
{
await using var cmd = _connection.CreateCommand();
cmd.CommandText = @"
SELECT DeviceId, TagName, Value, Timestamp
FROM DeviceData
WHERE DeviceId = @deviceId
AND Timestamp BETWEEN @start AND @end
ORDER BY Timestamp ASC;";
cmd.Parameters.AddWithValue("@deviceId", deviceId);
cmd.Parameters.AddWithValue("@start", start);
cmd.Parameters.AddWithValue("@end", end);
await using var reader = await cmd.ExecuteReaderAsync();
while (await reader.ReadAsync())
{
result.Add(new DeviceDataPoint
{
DeviceId = reader.GetString(0),
TagName = reader.GetString(1),
Value = reader.GetDouble(2),
Timestamp = reader.GetInt64(3)
});
}
}
finally
{
_gate.Release();
}
return result;
}
public void Dispose()
{
_connection.Dispose();
_gate.Dispose();
}
}
踩坑预警: 不要在 WPF UI 线程上直接调用数据库操作,哪怕是 SQLite 也会卡界面。务必用 async/await 或 Task.Run 将数据库操作推到后台线程。另外,PRAGMA synchronous=OFF 虽然性能最高,但断电时有数据丢失风险,上位机场景不建议使用。
方案二:SQL Server Express 接入(适合多客户端或复杂查询场景)
当项目需要多台上位机同时访问同一数据库,或者报表查询逻辑非常复杂(多表关联、存储过程、视图),SQL Server Express 的优势才真正体现出来。
csharp// SqlServerDataService.cs
// 适用场景:多客户端并发访问、复杂报表查询
// 依赖:Microsoft.Data.SqlClient(NuGet)
using Microsoft.Data.SqlClient;
using System.Data;
namespace AppWpf202606;
public sealed class SqlServerDeviceDataRepository : IDeviceDataRepository
{
private readonly string _connectionString;
public SqlServerDeviceDataRepository(SqlServerSettings settings)
{
var builder = new SqlConnectionStringBuilder
{
DataSource = settings.Server,
InitialCatalog = settings.Database,
IntegratedSecurity = settings.IntegratedSecurity,
TrustServerCertificate = settings.TrustServerCertificate,
ConnectTimeout = settings.ConnectTimeout,
MinPoolSize = settings.MinPoolSize,
MaxPoolSize = settings.MaxPoolSize
};
_connectionString = builder.ConnectionString;
EnsureTable();
}
private void EnsureTable()
{
using var conn = new SqlConnection(_connectionString);
conn.Open();
using var cmd = conn.CreateCommand();
cmd.CommandText = @"
IF OBJECT_ID('dbo.DeviceData','U') IS NULL
BEGIN
CREATE TABLE dbo.DeviceData
(
Id BIGINT IDENTITY(1,1) PRIMARY KEY,
DeviceId NVARCHAR(64) NOT NULL,
TagName NVARCHAR(64) NOT NULL,
Value FLOAT NOT NULL,
Timestamp BIGINT NOT NULL
);
CREATE INDEX IX_DeviceData_DeviceTime
ON dbo.DeviceData(DeviceId, Timestamp DESC);
END";
cmd.ExecuteNonQuery();
}
public async Task InsertBatchAsync(IEnumerable<DeviceDataPoint> points)
{
var table = new DataTable();
table.Columns.Add("DeviceId", typeof(string));
table.Columns.Add("TagName", typeof(string));
table.Columns.Add("Value", typeof(double));
table.Columns.Add("Timestamp", typeof(long));
foreach (var p in points)
{
table.Rows.Add(p.DeviceId, p.TagName, p.Value, p.Timestamp);
}
await using var conn = new SqlConnection(_connectionString);
await conn.OpenAsync();
using var bulkCopy = new SqlBulkCopy(conn)
{
DestinationTableName = "dbo.DeviceData",
BatchSize = 1000,
BulkCopyTimeout = 60
};
bulkCopy.ColumnMappings.Add("DeviceId", "DeviceId");
bulkCopy.ColumnMappings.Add("TagName", "TagName");
bulkCopy.ColumnMappings.Add("Value", "Value");
bulkCopy.ColumnMappings.Add("Timestamp", "Timestamp");
await bulkCopy.WriteToServerAsync(table);
}
public async Task<List<DeviceDataPoint>> QueryRangeAsync(string deviceId, long start, long end)
{
var result = new List<DeviceDataPoint>();
await using var conn = new SqlConnection(_connectionString);
await conn.OpenAsync();
await using var cmd = conn.CreateCommand();
cmd.CommandText = @"
SELECT DeviceId, TagName, Value, Timestamp
FROM dbo.DeviceData
WHERE DeviceId = @deviceId
AND Timestamp BETWEEN @start AND @end
ORDER BY Timestamp ASC;";
cmd.Parameters.AddWithValue("@deviceId", deviceId);
cmd.Parameters.AddWithValue("@start", start);
cmd.Parameters.AddWithValue("@end", end);
await using var reader = await cmd.ExecuteReaderAsync();
while (await reader.ReadAsync())
{
result.Add(new DeviceDataPoint
{
DeviceId = reader.GetString(0),
TagName = reader.GetString(1),
Value = reader.GetDouble(2),
Timestamp = reader.GetInt64(3)
});
}
return result;
}
}
踩坑预警: SQL Server Express 有 10GB 数据库大小限制,这在高频采集场景下比想象中更容易触碰到。建议做好数据归档策略,比如按月分表或定期将历史数据导出到文件。另外,Express 版本不支持 SQL Server Agent,定时任务需要在应用层自行实现。
方案三:抽象层设计(面向未来的可替换架构)
项目初期用 SQLite,后期业务扩张需要换 SQL Server,如果代码里到处都是具体的数据库调用,迁移成本会非常高。一个简单的 Repository 接口可以把这个问题消灭在萌芽状态。
csharpnamespace AppWpf202606;
public interface IDeviceDataRepository
{
Task InsertBatchAsync(IEnumerable<DeviceDataPoint> points);
Task<List<DeviceDataPoint>> QueryRangeAsync(string deviceId, long start, long end);
}
这个模式的价值在于:业务逻辑层完全感知不到底层数据库的存在,单元测试时可以注入 Mock 实现,生产环境可以随时切换,这才是工程化思维。
UI 代码
xml<Window x:Class="AppWpf202606.MainWindow"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:d="http://schemas.microsoft.com/expression/blend/2008"
xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006"
xmlns:local="clr-namespace:AppWpf202606"
mc:Ignorable="d"
Title="上位机数据库示例" Height="540" Width="860">
<Grid Margin="16">
<Grid.RowDefinitions>
<RowDefinition Height="Auto" />
<RowDefinition Height="Auto" />
<RowDefinition Height="*" />
</Grid.RowDefinitions>
<StackPanel>
<TextBlock FontSize="18" FontWeight="SemiBold" Text="SQLite vs SQL Server Express 示例" />
<TextBlock Margin="0,8,0,0" Text="本例通过统一仓储接口演示可替换数据层。" />
<TextBlock Margin="0,6,0,0" x:Name="ProviderTextBlock" FontWeight="SemiBold" />
</StackPanel>
<StackPanel Grid.Row="1" Orientation="Horizontal" Margin="0,14,0,14">
<Button Width="140" Height="34" x:Name="InsertButton" Click="InsertButton_Click" Content="写入 1000 条" />
<Button Width="170" Height="34" Margin="10,0,0,0" x:Name="QueryButton" Click="QueryButton_Click" Content="查询最近 5 分钟" />
</StackPanel>
<TextBox Grid.Row="2"
x:Name="OutputTextBox"
IsReadOnly="True"
TextWrapping="Wrap"
VerticalScrollBarVisibility="Auto"
HorizontalScrollBarVisibility="Auto"
FontFamily="Consolas" />
</Grid>
</Window>
c#using System.Collections.Generic;
using System.Linq;
using System.Windows;
using System.Windows.Controls;
namespace AppWpf202606
{
/// <summary>
/// Interaction logic for MainWindow.xaml
/// </summary>
public partial class MainWindow : Window
{
private readonly IDeviceDataRepository _repository;
private const string DeviceId = "PLC-01";
private TextBlock ProviderTextBlockControl => (TextBlock)FindName("ProviderTextBlock")!;
private TextBox OutputTextBoxControl => (TextBox)FindName("OutputTextBox")!;
private Button InsertButtonControl => (Button)FindName("InsertButton")!;
private Button QueryButtonControl => (Button)FindName("QueryButton")!;
public MainWindow()
{
InitializeComponent();
_repository = ((App)Application.Current).Repository
?? throw new InvalidOperationException("未初始化数据仓储");
ProviderTextBlockControl.Text = $"当前数据库:{_repository.GetType().Name}";
OutputTextBoxControl.Text = "准备就绪。";
}
private async void InsertButton_Click(object sender, RoutedEventArgs e)
{
try
{
SetBusy(true);
var now = DateTimeOffset.UtcNow.ToUnixTimeSeconds();
var random = new Random();
var points = new List<DeviceDataPoint>(1000);
for (var i = 0; i < 1000; i++)
{
points.Add(new DeviceDataPoint
{
DeviceId = DeviceId,
TagName = $"Tag-{i % 10:D2}",
Value = Math.Round(random.NextDouble() * 100, 3),
Timestamp = now - (1000 - i)
});
}
var start = DateTime.Now;
await _repository.InsertBatchAsync(points);
var elapsed = DateTime.Now - start;
OutputTextBoxControl.Text =
$"写入完成:{points.Count} 条\n耗时:{elapsed.TotalMilliseconds:F2} ms\n时间:{DateTime.Now:HH:mm:ss}";
}
catch (Exception ex)
{
OutputTextBoxControl.Text = $"写入失败:{ex.Message}";
}
finally
{
SetBusy(false);
}
}
private async void QueryButton_Click(object sender, RoutedEventArgs e)
{
try
{
SetBusy(true);
var end = DateTimeOffset.UtcNow.ToUnixTimeSeconds();
var start = end - 300;
var list = await _repository.QueryRangeAsync(DeviceId, start, end);
var preview = string.Join(Environment.NewLine,
list.Take(10).Select(x =>
$"{x.DeviceId,-8} {x.TagName,-8} {x.Value,8:F3} {DateTimeOffset.FromUnixTimeSeconds(x.Timestamp):HH:mm:ss}"));
OutputTextBoxControl.Text =
$"查询结果:{list.Count} 条(最近 5 分钟)\n\n{preview}";
}
catch (Exception ex)
{
OutputTextBoxControl.Text = $"查询失败:{ex.Message}";
}
finally
{
SetBusy(false);
}
}
private void SetBusy(bool isBusy)
{
InsertButtonControl.IsEnabled = !isBusy;
QueryButtonControl.IsEnabled = !isBusy;
}
}
}
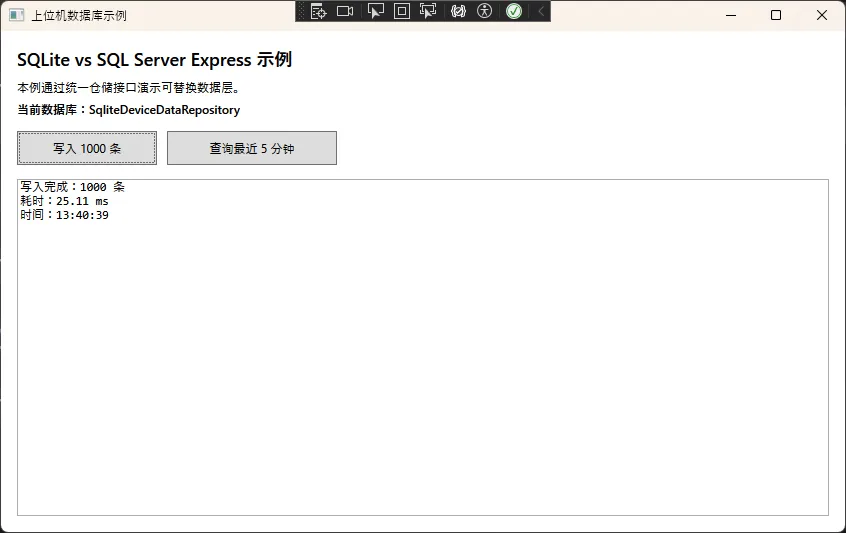
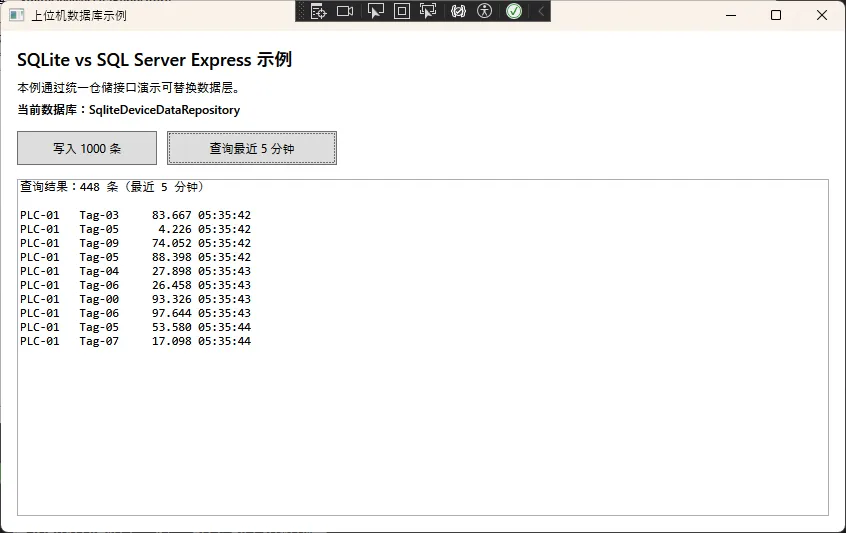
📊 选型决策框架
不用纠结,按下面这个逻辑走,覆盖 80% 的上位机场景:
选 SQLite,当满足以下条件时:
- 单台上位机独立运行,无需远程访问
- 日数据量在 500 万条以内
- 客户现场部署条件受限(老旧系统、网络隔离)
- 项目维护人员技术背景有限
选 SQL Server Express,当满足以下条件时:
- 多台上位机或 MES 系统需要访问同一数据库
- 需要复杂的多表关联查询或存储过程
- 已有 SQL Server 基础设施(IT 部门维护)
- 数据安全与权限管理有明确要求
两者都不够用时: 考虑 TimescaleDB(PostgreSQL 扩展,专为时序数据设计)或 InfluxDB,这是另一个话题了,后续可以单独展开。
🎯 三句话总结
SQLite 是上位机的瑞士军刀:轻量、可靠、零维护,单机场景下 90% 的需求它都能扛。
SQL Server Express 是当你需要"真正的数据库"时的选择:并发、权限、复杂查询,它的优势在多客户端场景才真正体现。
架构比实现更重要:无论选哪个,用接口隔离业务逻辑,给自己留退路。
💬 聊聊你的实践
在你的上位机项目里,数据库选型有没有踩过坑?比如 SQLite 在高频写入下的锁超时问题,或者 SQL Server Express 在现场部署时遇到的依赖地狱?欢迎在评论区分享你的经历,这类实战经验往往比文档更有价值。
另外抛一个思考题:如果采集频率达到 100Hz(每秒 100 条/设备),你会怎么设计数据落库策略?是内存缓冲批量写入,还是直接用时序数据库?
📚 学习路径
如果你想在这个方向继续深入,建议的路径是:
基础巩固 → 掌握 ADO.NET 原生操作与事务控制 → 工具提升 → 引入 Dapper 或 EF Core 提升开发效率 → 架构升级 → Repository 模式 + DI 容器 → 进阶方向 → 时序数据库选型(TimescaleDB / InfluxDB)
#C#开发 #WPF #上位机 #SQLite #数据库选型 #性能优化 #工控软件
相关信息
我用夸克网盘给你分享了「AppWpf202606.zip」,点击链接或复制整段内容,打开「夸克APP」即可获取。
/90803YpnpS:/
链接:https://pan.quark.cn/s/ee3942e45201
提取码:Qcvr

本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!