
目录
去年我接手一个化工厂的上位机改造项目,前任开发者留下来的系统跑了五年,SQLite数据库文件有将近12GB。某天夜班,工控机硬盘突发坏道,系统直接挂掉。运维打电话过来问我:备份在哪?
翻遍整台机器,没有。一条备份脚本都没有。
五年的设备运行记录、工艺参数历史、报警日志——全没了。那次事故最终导致工厂停产将近两天,损失不是我能估算的数字。
这件事给我的教训很深:备份不是"有空了再做"的事,是系统上线第一天就必须到位的基础设施。 工业场景尤其如此——设备数据往往不可再生,一旦丢失,没有任何办法补回来。
这篇文章,咱们就把工业SQLite数据库的备份与恢复这件事,从头到尾说清楚。代码全部可以直接跑,不是那种"示意性伪代码"。
🔍 工业备份的特殊挑战
普通Web应用的备份,停服、导出、完事。工业数据库不行。
原因有三个。第一,不能停服。 设备24小时上报数据,你不可能为了备份让PLC停止通信。第二,数据库文件可能很大。 跑了几年的工业数据库,几个GB到几十GB很正常,直接复制文件的时间窗口太长,期间数据库状态可能变化。第三,恢复时间要求苛刻。 工厂等不起,恢复必须快,最好能精确到某个时间点。
这三个约束,决定了工业备份策略必须比普通应用更精细。
SQLite提供了一个官方的热备份API——sqlite3_backup,Python的sqlite3模块直接封装了这个接口,叫做conn.backup()。它的核心优势是在数据库正常读写的同时完成备份,不需要锁表,不影响业务。这是工业场景备份的基础工具。
🚀 方案一:在线热备份,业务不停机
先把最基础的热备份封装好:
pythonimport sqlite3
import os
import time
import shutil
from datetime import datetime
from pathlib import Path
class IndustrialBackupManager:
"""
工业数据库备份管理器
核心设计原则:备份过程对业务零干扰
"""
def __init__(self, source_db: str, backup_dir: str):
self.source_db = source_db
self.backup_dir = Path(backup_dir)
self.backup_dir.mkdir(parents=True, exist_ok=True)
def hot_backup(self, pages_per_step: int = 100, sleep_ms: int = 10) -> str:
"""
在线热备份 —— 数据库正常运行时安全复制
pages_per_step: 每步复制的页数,越小对业务影响越低
sleep_ms: 每步之间的休眠毫秒数,让出CPU给业务线程
返回: 备份文件路径
"""
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
backup_path = self.backup_dir / f"backup_{timestamp}.db"
source_conn = sqlite3.connect(self.source_db)
backup_conn = sqlite3.connect(str(backup_path))
try:
# progress_callback 每步都会被调用,可以在这里记录进度
def progress_callback(status, remaining, total):
if total > 0:
pct = (total - remaining) / total * 100
print(f"\r备份进度: {pct:.1f}% ({total-remaining}/{total} pages)",
end='', flush=True)
source_conn.backup(
backup_conn,
pages=pages_per_step, # 每次复制100页
progress=progress_callback,
sleep=sleep_ms / 1000.0 # 转换为秒
)
print(f"\n热备份完成: {backup_path}")
return str(backup_path)
finally:
source_conn.close()
backup_conn.close()
def verify_backup(self, backup_path: str) -> bool:
"""
备份完整性验证 —— 备份了但没验证,等于没备份
SQLite的integrity_check会检查页校验和、索引一致性等
"""
try:
conn = sqlite3.connect(backup_path)
cursor = conn.cursor()
cursor.execute('PRAGMA integrity_check')
result = cursor.fetchone()
conn.close()
is_ok = result[0] == 'ok'
status = "✅ 完整" if is_ok else f"❌ 损坏: {result[0]}"
print(f"备份验证 [{Path(backup_path).name}]: {status}")
return is_ok
except Exception as e:
print(f"❌ 验证失败: {e}")
return False
pages_per_step这个参数值得多说一句。SQLite数据库由固定大小的页(默认4KB)组成,backup()每次复制pages页后会暂停sleep秒,让业务线程有机会继续写入。值设得越小,备份对业务的影响越低,但备份总时间也越长。工业场景里,我一般设100页 + 10ms休眠,在一台普通工控机上备份1GB数据库大约需要3~4分钟,业务完全无感知。
⏰ 方案二:定时备份 + 自动轮转,防止磁盘撑爆
热备份的接口有了,下一步是让它自动跑起来,并且管理好历史备份文件——不然时间一长,备份把磁盘吃满,又是另一种事故。
pythonimport threading
import logging
from typing import Optional
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s [%(levelname)s] %(message)s',
handlers=[
logging.FileHandler('backup.log', encoding='utf-8'),
logging.StreamHandler()
]
)
class ScheduledBackupService:
"""
定时备份服务 —— 后台线程自动执行,主程序无需关心
支持:全量备份 + 自动清理过期文件
"""
def __init__(self, manager: IndustrialBackupManager,
full_backup_interval: int = 3600, # 全量备份间隔(秒),默认1小时
max_backups: int = 72): # 最多保留72个备份(3天)
self.manager = manager
self.full_interval = full_backup_interval
self.max_backups = max_backups
self._stop_event = threading.Event()
self._thread: Optional[threading.Thread] = None
def start(self):
"""启动后台备份服务"""
self._thread = threading.Thread(
target=self._backup_loop,
name='BackupService',
daemon=True # 主程序退出时自动结束
)
self._thread.start()
logging.info("定时备份服务已启动")
def stop(self):
self._stop_event.set()
if self._thread:
self._thread.join(timeout=30)
logging.info("定时备份服务已停止")
def _backup_loop(self):
while not self._stop_event.is_set():
try:
self._do_full_backup()
self._rotate_old_backups()
except Exception as e:
logging.error(f"备份任务异常: {e}", exc_info=True)
# 等待下一次备份,期间可响应stop信号
self._stop_event.wait(timeout=self.full_interval)
def _do_full_backup(self):
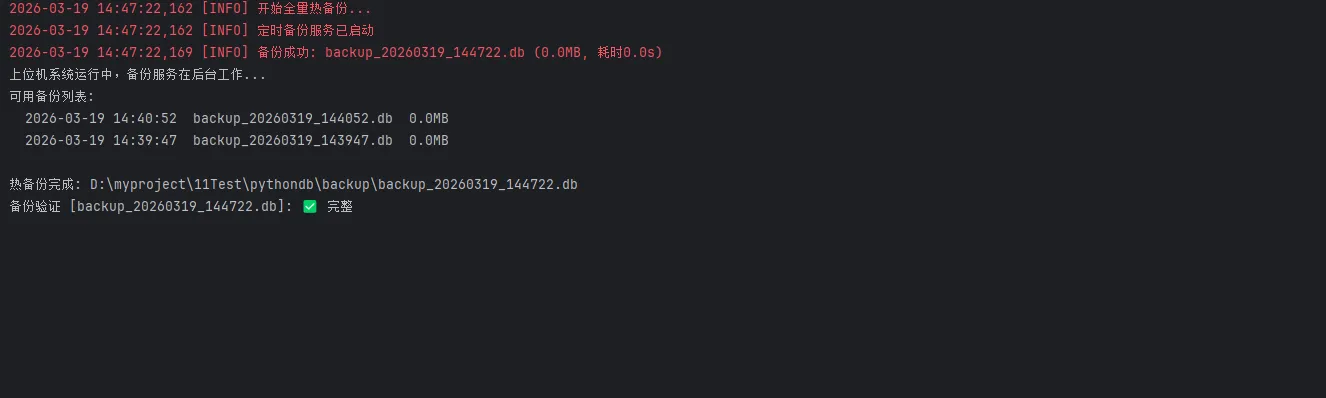
logging.info("开始全量热备份...")
t0 = time.time()
backup_path = self.manager.hot_backup()
elapsed = time.time() - t0
# 备份完立刻验证
if self.manager.verify_backup(backup_path):
size_mb = os.path.getsize(backup_path) / 1024 / 1024
logging.info(f"备份成功: {Path(backup_path).name} "
f"({size_mb:.1f}MB, 耗时{elapsed:.1f}s)")
else:
logging.error(f"备份文件损坏,已删除: {backup_path}")
os.remove(backup_path)
def _rotate_old_backups(self):
"""清理超出数量限制的旧备份,保留最新的N个"""
backups = sorted(
self.manager.backup_dir.glob('backup_*.db'),
key=lambda p: p.stat().st_mtime,
reverse=True # 最新的排前面
)
to_delete = backups[self.max_backups:]
for old_backup in to_delete:
old_backup.unlink()
logging.info(f"清理过期备份: {old_backup.name}")
这里有个细节——daemon=True让备份线程成为守护线程,主程序(上位机应用)退出时备份线程自动结束,不会出现"主程序关了备份线程还在跑"的僵尸进程问题。
踩坑预警:备份目录别和数据库文件放在同一块硬盘。硬盘坏了,数据库和备份一起没。备份的意义在于冗余,至少要放到不同的物理存储介质上——外接U盘、网络共享目录、甚至另一台机器的SMB共享都行。
🔄 方案三:增量备份思路,应对超大数据库
全量备份对于几百MB的数据库完全够用。但如果你的数据库已经长到10GB以上,每小时全量备份一次,既耗时又耗空间。这时候需要引入增量备份的思路。
SQLite本身没有原生的增量备份API,但我们可以借助WAL(Write-Ahead Log)文件来实现近似的增量效果:
pythonimport hashlib
class IncrementalBackupManager:
"""
基于WAL的增量备份策略
原理:WAL文件记录了自上次checkpoint以来的所有变更
通过定期归档WAL文件,实现增量备份
"""
def __init__(self, source_db: str, backup_dir: str):
self.source_db = source_db
self.wal_file = source_db + '-wal'
self.backup_dir = Path(backup_dir)
self.backup_dir.mkdir(parents=True, exist_ok=True)
self._last_wal_hash = None
def archive_wal_if_changed(self) -> bool:
"""
检测WAL文件是否有新变更,有则归档
每5分钟调用一次,捕获高频写入场景下的增量数据
"""
if not os.path.exists(self.wal_file):
return False # WAL模式未开启,或无待提交事务
wal_size = os.path.getsize(self.wal_file)
if wal_size == 0:
return False
# 计算WAL文件哈希,判断是否有新内容
current_hash = self._file_hash(self.wal_file)
if current_hash == self._last_wal_hash:
return False # 没有变化,跳过
# 有变化,归档这份WAL快照
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
archive_path = self.backup_dir / f"wal_archive_{timestamp}.wal"
shutil.copy2(self.wal_file, str(archive_path))
self._last_wal_hash = current_hash
size_kb = wal_size / 1024
logging.info(f"WAL增量归档: {archive_path.name} ({size_kb:.1f}KB)")
return True
def force_checkpoint_and_backup(self, conn: sqlite3.Connection) -> str:
"""
强制WAL checkpoint后做全量备份
建议每天深夜执行一次,作为基准快照
"""
# checkpoint:把WAL里的变更合并回主数据库文件
conn.execute('PRAGMA wal_checkpoint(TRUNCATE)')
conn.commit()
logging.info("WAL checkpoint完成,开始全量基准备份")
mgr = IndustrialBackupManager(self.source_db, str(self.backup_dir))
return mgr.hot_backup()
@staticmethod
def _file_hash(filepath: str) -> str:
h = hashlib.md5()
with open(filepath, 'rb') as f:
while chunk := f.read(65536):
h.update(chunk)
return h.hexdigest()
这套策略的组合用法是:每天凌晨做一次全量基准备份 + 每5分钟归档一次WAL增量。恢复时,先恢复最近的全量备份,再按时间顺序重放WAL归档文件,就能把数据还原到任意5分钟粒度的时间点。
🛠️ 方案四:完整的恢复流程,才是备份的终点
备份做得再好,不会恢复等于白搭。很多团队平时备份认真,真出事了手忙脚乱,恢复操作把备份文件也搞坏了。
pythonclass RecoveryManager:
"""
数据库恢复管理器
原则:恢复操作永远在副本上进行,原备份文件只读不动
"""
def __init__(self, backup_dir: str, target_db: str):
self.backup_dir = Path(backup_dir)
self.target_db = target_db
def list_available_backups(self) -> list:
"""列出所有可用备份,按时间倒序"""
backups = []
for f in sorted(self.backup_dir.glob('backup_*.db'),
key=lambda p: p.stat().st_mtime, reverse=True):
size_mb = f.stat().st_size / 1024 / 1024
mtime = datetime.fromtimestamp(f.stat().st_mtime)
backups.append({
'path': str(f),
'name': f.name,
'size_mb': round(size_mb, 1),
'time': mtime.strftime('%Y-%m-%d %H:%M:%S')
})
return backups
def restore_from_backup(self, backup_path: str,
create_safety_copy: bool = True) -> bool:
"""
从指定备份文件恢复数据库
create_safety_copy: 恢复前先把当前数据库备份一份
—— 万一恢复的备份也有问题,还能退回去
"""
backup_path = Path(backup_path)
if not backup_path.exists():
logging.error(f"备份文件不存在: {backup_path}")
return False
# 第一步:验证备份文件完整性
logging.info("验证备份文件完整性...")
mgr = IndustrialBackupManager(str(backup_path), str(self.backup_dir))
if not mgr.verify_backup(str(backup_path)):
logging.error("备份文件损坏,中止恢复")
return False
# 第二步:把当前数据库做一个安全副本(如果存在的话)
if create_safety_copy and os.path.exists(self.target_db):
safety_path = self.target_db + f".before_restore_{int(time.time())}"
shutil.copy2(self.target_db, safety_path)
logging.info(f"当前数据库已备份至: {safety_path}")
# 第三步:用备份覆盖目标数据库
# 注意:先复制到临时文件,再原子性重命名,避免复制到一半系统崩溃
tmp_path = self.target_db + '.tmp_restore'
try:
shutil.copy2(str(backup_path), tmp_path)
os.replace(tmp_path, self.target_db) # 原子操作
# 清理WAL和SHM文件,避免旧的WAL干扰恢复后的数据库
for ext in ['-wal', '-shm']:
leftover = self.target_db + ext
if os.path.exists(leftover):
os.remove(leftover)
logging.info(f"清理残留文件: {leftover}")
logging.info(f"恢复成功: {backup_path.name} -> {self.target_db}")
return True
except Exception as e:
logging.error(f"恢复失败: {e}")
if os.path.exists(tmp_path):
os.remove(tmp_path)
return False
def restore_latest(self) -> bool:
"""一键恢复到最新备份——应急场景最常用"""
backups = self.list_available_backups()
if not backups:
logging.error("没有找到任何备份文件")
return False
latest = backups[0]
logging.info(f"准备恢复最新备份: {latest['name']} "
f"({latest['time']}, {latest['size_mb']}MB)")
return self.restore_from_backup(latest['path'])
注意os.replace()这个调用——它在Windows上是原子操作(POSIX语义),确保即使恢复过程中断电,目标文件要么是旧的完整版本,要么是新的完整版本,不会出现半截文件。这个细节在工控机这种可能随时断电的环境里非常重要。
🔧 把所有东西串起来,一个完整的使用示例
pythonif __name__ == '__main__':
SOURCE_DB = r'C:\IndustrialApp\data\production.db'
BACKUP_DIR = r'D:\Backups\production_db' # D盘,不同于数据库所在的C盘
# 初始化备份管理器
backup_mgr = IndustrialBackupManager(SOURCE_DB, BACKUP_DIR)
# 启动定时备份服务(每小时全量备份,保留3天)
scheduler = ScheduledBackupService(
manager=backup_mgr,
full_backup_interval=3600,
max_backups=72
)
scheduler.start()
# 初始化恢复管理器(应急时用)
recovery_mgr = RecoveryManager(BACKUP_DIR, SOURCE_DB)
# 模拟主程序运行(实际是你的上位机主循环)
print("上位机系统运行中,备份服务在后台工作...")
print("可用备份列表:")
for b in recovery_mgr.list_available_backups()[:5]:
print(f" {b['time']} {b['name']} {b['size_mb']}MB")
try:
# 主循环...
time.sleep(7200)
except KeyboardInterrupt:
scheduler.stop()
print("系统正常退出")
💡 三句话带走的核心洞察
备份验证和备份本身同等重要——没有经过
integrity_check验证的备份,只是一个你以为安全的文件。
工业场景的恢复操作永远先做安全副本,再执行覆盖,给自己留一条退路。
os.replace()的原子性是工控机断电保护的最后一道防线,别用shutil.copy直接覆盖目标文件。
📚 延伸方向
本文覆盖的是单机SQLite场景。如果你的工业系统在演进——比如从单机上位机升级为多节点数据采集平台——可以进一步研究:SQLite的复制扩展(如Litestream,支持实时流式备份到S3/MinIO)、PostgreSQL的PITR(时间点恢复)机制,以及工业场景下的主备切换架构设计。备份策略会随着系统规模的增长而演进,但核心原则不变:冗余、验证、快速恢复。
欢迎在评论区分享你在工业项目里遇到过的数据备份问题,或者你现在用的是什么备份方案——不同场景下的实践经验,往往比文档更有参考价值。
标签:#Python开发 #SQLite备份 #工业数据库 #容灾恢复 #性能优化
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!