
目录
上周一个朋友找我,说他想把某个大佬 GitHub 上的所有开源项目都下载到本地慢慢研究,手动一个个点"Download ZIP"——他数了数,127 个仓库。
我当时的反应是:这活儿交给代码干。
说实话,这类需求在团队里挺常见的。新人入职要批量拉取公司账号下的所有服务仓库;技术调研阶段要把某个组织的项目全部存档;甚至有些公司做代码审计,也需要把账号下的仓库打包归档。手动操作?费时费力,还容易漏。
所以我花了一个下午,用 C# WinForms 写了一个带界面的 GitHub 仓库批量下载工具。功能说起来不复杂:输入用户名,拉取仓库列表,勾选你要的,一键全部 ZIP 到本地。但里面有不少细节值得聊聊。
🧱 整体架构,先有个全局观
工具分三层,逻辑很清晰:
UI 层负责展示和交互,WinForms 写的,ListView 展示仓库列表,ProgressBar 显示下载进度,RichTextBox 做实时日志输出——就是那种深色背景、绿色字体的终端风格,看着挺带劲的。
网络层只用了一个 HttpClient,整个应用生命周期共用同一个实例。这里有个坑很多人踩过:每次请求都 new HttpClient() 会导致 socket 耗尽,尤其下载量大的时候,系统端口会被撑爆。静态单例,记住这一点。
数据层就是一个简单的 RepoInfo 模型类,把 GitHub API 返回的 JSON 字段映射过来,没有引入任何 ORM 或者数据库,纯内存操作。
整个项目零第三方依赖,System.Net.Http 做请求,System.Text.Json 解析数据,System.IO 写文件。.NET 8 自带的东西,够用了。
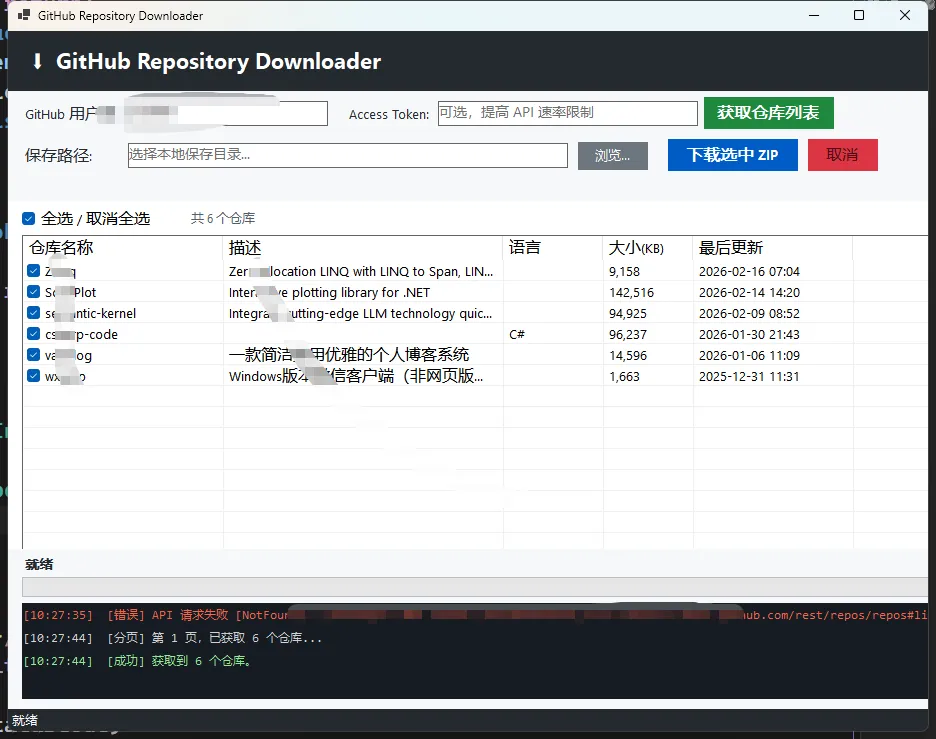
🌐 先看效果
🌐 跟 GitHub API 打交道,有几个地方要注意
接口地址和翻页
获取某用户所有仓库的接口是:
GET https://api.github.com/users/{username}/repos?per_page=100&page=1&sort=updated
每页最多返回 100 条,超过 100 个仓库就得翻页。翻页逻辑很简单,page 参数递增,直到返回的数组为空为止:
csharpprivate async Task<List<RepoInfo>> FetchAllReposAsync(
string user, CancellationToken ct)
{
var result = new List<RepoInfo>();
int page = 1;
while (true)
{
string url = $"{ApiBase}/users/{user}/repos" +
$"?per_page=100&page={page}&sort=updated";
using var resp = await _http.GetAsync(url, ct);
if (!resp.IsSuccessStatusCode)
{
string body = await resp.Content.ReadAsStringAsync(ct);
throw new Exception($"API 请求失败 [{resp.StatusCode}]: {body}");
}
string json = await resp.Content.ReadAsStringAsync(ct);
using var doc = JsonDocument.Parse(json);
// 空数组说明已到最后一页,退出循环
if (doc.RootElement.GetArrayLength() == 0) break;
foreach (var item in doc.RootElement.EnumerateArray())
{
result.Add(new RepoInfo
{
Name = item.GetProperty("name").GetString() ?? "",
FullName = item.GetProperty("full_name").GetString() ?? "",
Description = item.TryGetProperty("description", out var d)
&& d.ValueKind != JsonValueKind.Null
? d.GetString() ?? "" : "",
Language = item.TryGetProperty("language", out var l)
&& l.ValueKind != JsonValueKind.Null
? l.GetString() ?? "" : "",
SizeKb = item.GetProperty("size").GetInt64(),
UpdatedAt = item.GetProperty("updated_at").GetString() ?? "",
DefaultBranch = item.GetProperty("default_branch").GetString() ?? "main",
});
}
page++;
}
return result;
}
注意 description 和 language 字段在 API 里可能是 null,直接 GetString() 会抛异常,要先判断 ValueKind。这个坑我第一版没处理,跑到有空描述的仓库就崩了。
速率限制——Token 是救命稻草
未认证请求每小时只有 60 次额度,获取一次列表就可能用掉好几次,再加上下载请求,分分钟触顶。
填了 Personal Access Token(只需要勾选 public_repo 读权限)之后,额度涨到每小时 5000 次,完全够用。Token 注入方式:
csharpprivate void ApplyToken()
{
_http.DefaultRequestHeaders.Authorization = null;
string token = txtToken.Text.Trim();
if (!string.IsNullOrEmpty(token))
{
_http.DefaultRequestHeaders.Authorization =
new AuthenticationHeaderValue("Bearer", token);
}
}
Token 在界面上用 PasswordChar = '●' 做了掩码处理,不会明文显示。
⬇️ 下载 ZIP,流式写入才是正解
GitHub 提供了直接下载仓库 ZIP 的地址,格式是:
https://github.com/{owner}/{repo}/archive/refs/heads/{branch}.zip
下载逻辑看着简单,但有一个关键决策:不能把整个响应体读进内存再写文件。遇到几十 MB 的大仓库,内存会撑得很难看,批量下载十几个更是灾难。正确做法是流式传输——边读边写:
csharpprivate static async Task SaveStreamToFileAsync(
HttpResponseMessage response, string filePath, CancellationToken ct)
{
await using var httpStream = await response.Content.ReadAsStreamAsync(ct);
await using var fileStream = new FileStream(
filePath,
FileMode.Create,
FileAccess.Write,
FileShare.None,
bufferSize: 81920, // 80KB 缓冲区,平衡性能与内存
useAsync: true);
await httpStream.CopyToAsync(fileStream, 81920, ct);
}
GetAsync 调用时传入 HttpCompletionOption.ResponseHeadersRead,这样收到响应头就返回,不等整个 body 下载完——这才是流式下载的关键开关,很多人忽略这个参数。
分支名回退机制
还有个小坑:GitHub 这几年把默认分支从 master 改成了 main,但历史仓库未必跟着改。API 返回的 default_branch 字段理论上是准的,但偶尔会遇到下载 404 的情况。所以我加了一个回退逻辑:
csharp// 先用 API 返回的默认分支名
using var response = await _http.GetAsync(url,
HttpCompletionOption.ResponseHeadersRead, ct);
if (!response.IsSuccessStatusCode && repo.DefaultBranch != "master")
{
// 404 了就回退尝试 master
string fallbackUrl =
$"https://github.com/{repo.FullName}/archive/refs/heads/master.zip";
using var fallback = await _http.GetAsync(fallbackUrl,
HttpCompletionOption.ResponseHeadersRead, ct);
// ...
}
不优雅,但管用。工程实践里这种防御性代码很有必要。
🎛️ 异步与取消——别让界面卡死
WinForms 开发最容易犯的错误就是在 UI 线程上做耗时操作,界面直接假死。所有网络请求都用 async/await,按钮事件处理器标记为 async void(WinForms 事件处理器只能这样)。
取消操作用 CancellationTokenSource 实现,点「取消」按钮就调用 _cts.Cancel()。所有异步方法都接受 CancellationToken 参数,在每个 await 点自动响应取消信号,抛出 OperationCanceledException 后在 catch 里优雅处理:
csharpcatch (OperationCanceledException)
{
AppendLog("[已取消] 操作被用户中止。", Color.Orange);
SetStatus("已取消。");
}
跨线程更新 UI 的问题也要处理。日志输出、状态栏更新这些操作可能从异步上下文回调,必须切回 UI 线程:
csharpprivate void AppendLog(string message, Color color)
{
if (rtbLog.InvokeRequired)
{
rtbLog.Invoke(() => AppendLog(message, color));
return;
}
// 正常更新 UI...
}
InvokeRequired + Invoke 的经典组合,.NET 6 之后可以用 Lambda,代码简洁多了。
🎨 界面设计,程序员也可以写出好看的 UI
说实话,WinForms 做出来的界面大多数都挺丑的。这次我在 Designer.cs 里花了点心思:
顶部用了深色 Header(Color.FromArgb(36, 41, 47),就是 GitHub 的深色导航栏颜色),白色大字标题,整体有点 GitHub 风格。日志区域黑底浅字,模拟终端风格,看着比白底黑字更有感觉。按钮颜色语义化——绿色是「获取」,蓝色是「下载」,红色是「取消」,用户一眼就知道该点哪个。
控件命名也严格遵守了前缀规范:btn 开头的是按钮,txt 开头的是文本框,lv 是 ListView,pgb 是进度条,rtb 是富文本框……团队协作的时候,这种命名规范能省掉很多沟通成本,强烈建议养成习惯。
🧪 实测效果
拿 microsoft 账号测试了一下(他们有几百个公开仓库),获取列表大概花了 3~5 秒,翻了好几页。批量下载 20 个中等大小的仓库,全程流畅,日志实时滚动,进度条稳步推进,没有任何卡顿。
内存占用也很克制,始终在 50MB 以内,流式写入的效果立竿见影。
💡 三句话总结
- HttpClient 要单例复用,每次
new是在给自己挖坑,端口耗尽不是开玩笑。 - 流式下载是标配,
ResponseHeadersRead+CopyToAsync,大文件场景内存省一大半。 - CancellationToken 要贯穿始终,异步操作没有取消机制,用户体验会很糟糕。
完整项目三个文件:Program.cs、FrmMain.cs、FrmMain.Designer.cs,零依赖,.NET 8 直接跑。有用的话收藏备用,说不定哪天就用上了。
#C# #WinForms #GitHub #爬虫 #开发工具
相关信息
通过网盘分享的文件:AppGitHubDownloader.zip 链接: https://pan.baidu.com/s/1oiFxCvVCL8562cZwcxzmrg?pwd=bqq2 提取码: bqq2 --来自百度网盘超级会员v9的分享
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!