
目录
🌱 开头:大模型火了,但很多人其实没搞懂
这两年,只要谈技术,绕不开两个词:AI 和大模型。
开会会上,领导说“要用大模型赋能业务”;方案评审时,PPT上写着“打造企业级大模型平台”;朋友圈里则是一串“xxCopilot”“智能体”“RAG”“长上下文”。
但冷静下来问一句:什么叫“大模型”?
它到底大在哪?为什么大家都说它要“重构软件开发范式”“颠覆内容生产方式”?
更现实一点——和你手上的业务、KPI、性能指标,到底有什么直接关系?
不少同学心里其实是这样的:
- 觉得大模型“很神奇”,但一落地就变成“问答机器人”,用几天就没人理。
- 以为接了某个云厂商 API,就算“完成大模型改造”,结果效果平平,还被质疑“花架子”。
- 做技术的一肚子焦虑:不会大模型,好像就要被时代甩下;真做项目,又不知道从哪儿下手。
这篇文章,我们不讲玄学,也不过度追热点。
就围绕一个问题展开——从工程视角,什么是大模型,它给业务带来的“真实价值”究竟是什么?
同时,结合一个具体代表——通义千问——来拆解参数、版本号、上下文、Turbo、Preview、视觉能力这些标签到底在说啥。
🤯 一、问题深度剖析:大模型的三大“认知错位”
1️⃣ 错位一:把“大模型”当成“高级聊天机器人”
很多团队第一次接触大模型,是通过 ChatGPT、通义千问、文心一言、Claude 这一类产品。久而久之,会形成一个潜意识:大模型 = 会聊天的搜索增强版。
这会带来三个直接误区:
- 只做“问答Bot”,不做“业务能力”
- 典型表现:只在官网或App里放一个“智能客服”,问问就结束了。
- 没有把大模型真正接入订单、库存、风控、工单等业务系统。
- 只看“能不能答”,不看“答得有没有用”
- 满足于“模型能说话”,而不是“模型能帮你做成事”。
- 比如,它会写一段 SQL,但字段名、库名全是瞎编的——看起来很聪明,用起来很危险。
- 只堆提示词,不做工程化治理
- 业务方说:“再给它加几句提示试试。”
- 最后成了提示词泥石流,却没有日志、评测、迭代闭环。
结果:项目上线了,体验花哨,业务指标却没有明显起色。
2️⃣ 错位二:只盯模型参数,不看系统整体能力
另一个极端,是技术同学一上来就问:
- “你们这个大模型多少参数?是 72B 还是 671B?”
- “上下文是多少?32k 还是 1M?”
- “是不是最新一代,比如通义千问3、DeepSeek-671B 这种?”
这些问题本身没错,但单看模型本身,就像只看发动机马力,不看底盘、油耗和具体路况。
在真实业务里,更常见的问题反而是:
- 知识不更新:模型不知道你公司昨天刚上线的新产品。
- 流程不落地:模型知道“客服要走三步流程”,但没权限查订单、创建工单。
- 无法可控:偶尔“胡说八道”,却没有可靠的监控和兜底方案。
从结果看,大模型项目常见的失败模式是:
“效果不稳定、无法评估、不敢放量、不敢上生产。”
而这些,很大一部分不是模型本身的问题,而是系统设计问题。
3️⃣ 错位三:误以为“大模型能一次性解决所有问题”
还有一种隐性误解:
既然大模型这么厉害,那是不是上了一个通用大模型,所有智能化需求都能搞定?
现实却是:
- 在强结构化决策场景(风控、信贷审批、策略引擎)里,很多时候传统机器学习或规则引擎依然更稳、更好控。
- 在算力成本敏感的场景,用小模型 + 特征工程,可能比用大模型更便宜、更可控。
- 在实时性极强的链路上(比如毫秒级广告竞价),大模型的推理延迟是天生短板。
大模型不是银弹。
它更适合的是那类“开放、模糊、半结构化、靠经验判断”的任务,比如:
- 用自然语言描述需求,生成代码草稿。
- 根据用户上下文生成文案、摘要、报告。
- 对复杂业务流程进行“模糊决策 + 人工复核”。
🧠 二、什么是大模型:从“参数数量”到“能力边界”
🔍 1️⃣ 技术视角:大模型的底层机制
从工程角度看,所谓“大模型”,通常具备几类特征:
- 海量参数的神经网络
- 以 Transformer 为主(当然现在也出现了一些结构改良,但大部分还是“Transformer家族”)。
- 参数规模从几十亿到上千亿不等。
- 参数越多,理论上表达能力越强,但也更吃算力。
- 大规模预训练
- 在海量语料上进行自监督学习——“看到一堆文本,预测下一个词”。
- 这一步让模型学会:语言结构、常识、世界知识、基本推理。
- 指令微调与对齐(Instruction Tuning & Alignment)
- 用人工标注的问答对、对话样本等,教会模型“如何按照人类指令来回答”。
- 再通过 RLHF(人类反馈增强学习)等方式,让模型更符合“人类偏好”,比如:更安全、不乱喷、不攻击性。
- 多模态扩展(可选)
- 文字 + 图片 + 音频 + 视频等。
- 通过统一的向量空间,让不同模态之间“能互相理解”。
你可以把大模型简单理解成:
一个超大规模、训练充分的“通用函数”: 输入一串Token(文字 / 代码 / 图像特征),输出下一串Token。 它本身不懂业务规则,但对“世界的统计规律”有极强记忆与拟合能力。
🧩 2️⃣ 能力视角:大模型带来的关键“新能力”
与传统机器学习、NLP 相比,大模型真正颠覆的能力主要有三点:
- 强泛化:不依赖场景特定标注
- 传统模型需要大量人肉标注才能迁移到新任务。
- 大模型只要换个提示词,就能在很多任务上拿到“能用”的效果。
- 统一接口:用自然语言调用复杂能力
- 不再需要设计一堆固定表单、按钮、开关。
- 用户直接用自然语言互动,系统再把需求拆解为后端调用。
- 知识 + 推理的一体化
- 过去,知识库和推理引擎分离:
- 知识存数据库 / 文档;
- 推理靠规则引擎 / 逻辑树。
- 大模型把**“记住知识 + 模糊推理”**揉成了一坨——虽然不完美,但在很多模糊场景已经“够好”。
- 过去,知识库和推理引擎分离:
🧾 三、借通义千问,拆一拆大模型常见“标签”到底在说啥
很多朋友看到模型列表时,往往会蒙圈:
比如看到类似下面的名字:
qwen2.5-72b-instruct DeepSeek-671B-V
这串看似“暗号”的后缀,其实都在传递具体信息。我们就以通义千问2.5为例,拆一下这些标识的工程含义。
🌐 1️⃣ “通义千问2.5”:代际和能力升级
“通义千问2.5”代表的是这一系列大模型的第 2.5 代通用模型。
- “2.5”不是一个纯粹的“版本号+1”,而通常意味着:
- 基于 2.0 代的架构和训练经验,做了一轮较大规模的能力升级;
- 在理解、生成、多语言、代码、多模态等方面做了综合优化;
- 对延迟、吞吐、推理稳定性做了工程级改造。
从工程视角看,可以大致理解为:
在保持整体架构相近的前提下,训练数据、目标、推理策略都迈了一小代。 你可以把 2.5 当成“2.0 的 Pro 版”。
📅 2️⃣ “2025-12-15”:版本编号是日期,不是魔法
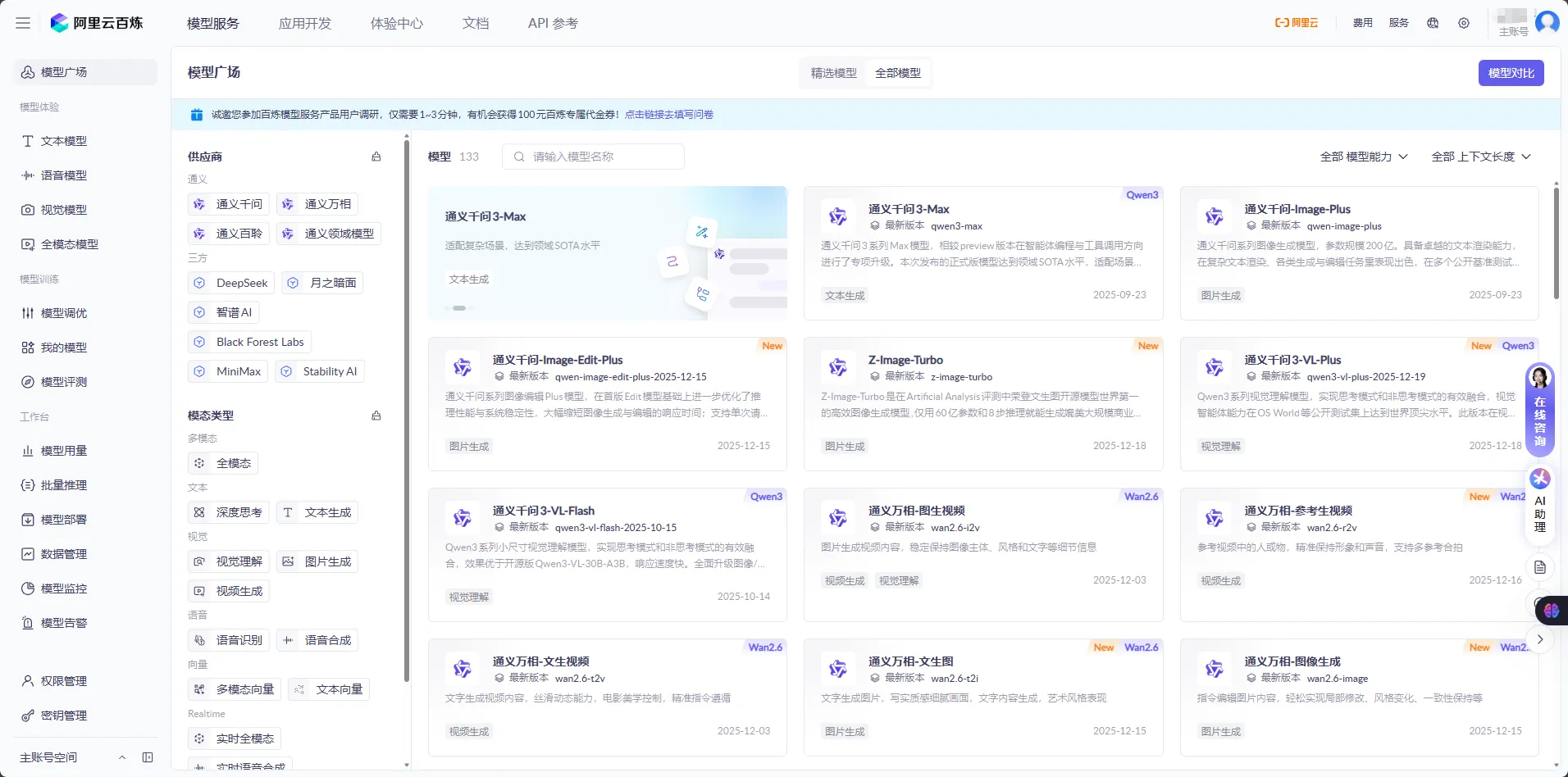
模型后面常常会带一个类似 2025-12-15 这样的字符串,例如:
qwen3-max-2025-09-23qwen3-vl-plus-2025-12-19
这些数字通常代表该模型的发布或修订日期。
2025-12-15则直接是“2025 年 12 月 15 日”的完整日期。
对工程团队来说,这些信息非常关键:
- 你可以明确知道自己到底在用哪个版本,方便对比不同版本的效果变化;
- 出现线上问题(比如回答变“奇怪”了),可以快速追踪:
- 是否是最近切换了模型版本?
- 是否是某个特定日期之后的版本引入了新行为?
- 在回滚或灰度发布时,也更容易做出“按日期、按版本”维度的选择。
🧮 3️⃣ “72B”:参数量是“脑容量”的粗略量尺
看到 72B、32B、7B 时,基本都是在说一件事:参数量。
72B:表示这个大模型大约有 72 Billion(720 亿)个参数;1B就是 10 亿参数,671B就是 6710 亿参数,比如常被提到的 满血版 DeepSeek-671B。
参数量越大,一般意味着:
- 模型具备更强的表达能力和拟合能力;
- 在复杂任务(比如多轮推理、跨领域知识)上,更有潜力表现更好;
- 但同时:
- 训练成本更高;
- 推理延迟更大;
- 部署资源更重(显存、算力要求显著提升)。
在工程实践中,经常会做一个平衡:
- 对话机器人、知识问答核心场景,可能用
72B或以上的模型做主力; - 在边缘场景、端侧部署、低成本场景,则采用
7B、14B等小模型,甚至蒸馏版本。
你可以简单记一句:
“B”是粗略的脑容量指标,但不是唯一的能力判断标准。
📏 4️⃣ “1M”:一次能“看”多长的文本?
很多模型名字里会出现 32k、128k、1M 之类的标记,比如:
qwen2.5-vl-32b-instruct- 其他模型上的
32k、128k等
这些标签通常指的是模型处理文本时的最大 token 数,也就是所谓的上下文窗口大小(context length)。
简单理解:在一次推理调用里,模型最多能“看见”多少字节的信息。
32k:可以处理最多约 32,000 个 token;1M:可以处理到百万级别的 token,这属于超长上下文。
为什么这很重要?
- 如果你要让模型读一份长报告、一本书、一堆代码文件、或者几十条聊天记录,上下文窗口就是瓶颈;
- 窗口太小,你就不得不做复杂的拆分、检索、拼接逻辑;
- 窗口变大,你在很多场景下可以更直接地“把材料都扔给它”。
当然,工程上也有几个需要注意的点:
- 上下文越长,推理成本和延迟也会上升,要合理限制输入长度;
- 即便写着
1M,也要通过评测确认:- 在超长上下文下,模型是否仍能聚焦在关键信息上,而不是“读了个寂寞”。
🚀 5️⃣ “Turbo”:更快、更省的优化版本
名字里如果带了 turbo,大多是在强调一件事:更快、更便宜的推理体验。比如:
qwen-turbo-latest- 其他云厂商家族里的
turbo型号
一般来说,Turbo 版本会在以下方面做文章:
- 推理加速:
- 使用更高效的内核、KV Cache 优化、图融合等技术;
- 在不明显牺牲质量的前提下,把单次调用的延迟压下来。
- 成本下探:
- 从底层算子到集群调度做优化,降低单 token 成本;
- 这对高并发、ToB 场景尤其关键。
- 质量–性能平衡:
- 有时会在极限能力上稍微做一点点妥协,换取整体吞吐量提升;
- 真实体验中,很多业务场景其实感受不到“轻微削峰”,只会觉得“就是快”。
你可以把 Turbo 版本当成:
“为线上生产环境量身打造的高性价比版本”,尤其适合大规模并发场景。
🧪 6️⃣ “Preview”:先体验,再决定是否“上生产”
模型名最后如果带了 preview,通常是在提醒你:
- 这是一个供早期访问、测试、预览的版本;
- 功能、效果可能已经不错,但:
- 还在快速迭代阶段;
- 接口、行为特征可能会有不稳定;
- 官方也在持续收集反馈做优化。
在工程实践中,可以这样使用 Preview 模型:
- 在沙箱环境 / 内部测试环境中,先跑一轮效果和稳定性验证;
- 与稳定版模型做AB 对比,观察:
- 正确率是否有明显提升?
- 幻觉、有害输出、延迟是否可控?
- 如果表现好,再考虑迁移到生产环境,并且:
- 设置灰度比例;
- 配合评测和监控,至少跑一两周。
一句话:Preview 适合“抢先体验、内部试点”,别一上来就全量替换生产主力。
👀 7️⃣ “带 V 字”:视觉增强的多模态模型
当你看到模型名中带一个 “V”,十有八九是在暗示——这是一个带视觉能力的多模态模型。例如:
qwen3-vl-plus(命名可能不完全相同,但“V / VL / vision”通常代表视觉)DeepSeek-V、某某-V等
这类模型通常在架构上做了两件事:
- 接一个视觉编码器(Vision Encoder)
- 将图片(甚至视频帧)编码成向量表示;
- 再把这些向量投射到和文本 token 同一个语义空间中。
- 让文本 + 图像融合输入
- 模型可以“同时看到”文字和图片信息;
- 从而支持:
- 看图说话、表格理解;
- UI 截图解析;
- 文档图片 + 文字混合理解。
对业务来说,带 “V” 的多模态大模型,开出新的落地空间:
- 客服:理解用户上传的截图、账单照片、报错页面;
- 运营:自动分析海报、商品图、图文内容;
- 研发:识别报错截图中的关键信息(端口、路径、异常堆栈等);
- 办公:对 PPT、PDF 中的图表进行说明、总结。
一句话:“V”= 不只会读写,还会“看图”。
🏗 四、大模型落地的关键技术模式
真正进入工程实践,你会发现:
“裸用模型 API”基本上都不行,必须有一整套工程化的组合拳。
无论你用的是通义千问2.5、3.0、DeepSeek 还是其他家族,思路基本类似。
⚙️ 1️⃣ RAG:用“外接知识库”给模型补脑
RAG(Retrieval-Augmented Generation)= 检索 + 生成。
简单说,就是:
- 用户提问;
- 系统先在企业知识库 / 文档中检索相关内容(向量检索 + 关键词检索混合);
- 把检索结果塞进提示词,让大模型在“看到相关资料”的前提下回答。
这种模式可以有效解决三件事:
- 知识时效性:不怕模型不知道昨天刚发布的政策、今天刚改的接口。
- 行业私有性:公司内部的 SOP、私有 API、风控策略等,都是外部模型看不到的。
- 可追溯性:回答可以携带“引用来源”,方便审计与复核。
实战建议:
- “1M 上下文”的通义千问之类模型,可以让你在一些场景下直接塞入更长材料,减少复杂切分逻辑;
- 但即便上下文很长,检索质量依然是瓶颈,不要迷信“全扔进去就行”。
🧮 2️⃣ Function Calling:让模型“开口说话,动手做事”
大模型本身只会生成文本。
要让它“真正驱动业务系统”,就需要通过 Function Calling(或 Tool Calling)这种模式:
- 预先定义一组函数(工具),比如:
get_order_detail(order_id)create_ticket(user_id, content)calculate_price(sku, quantity)
- 把这些函数签名(包括参数类型、含义)告知模型;
- 让模型根据用户自然语言,决定是否调用工具、调用哪个、用什么参数;
- 应用层执行该工具,把结果再丢回模型,由它生成最终回复。
价值点:
- 把“自然语言理解”交给大模型,把“关键操作控制权”留在你的服务端;
- 适合与通义千问3 这类通用模型配合,用自然语言做编排,用工具做落地。
🧪 3️⃣ 模型评测与监控:从“玄学调参”走向“可度量治理”
如果不做评测和监控,大模型落地后常见现象是——
“昨天还挺好用的,今天感觉不对劲,但谁也说不上来哪儿不对。”
一个基本可行的实践路径:
- 构建评测集(Eval Set)
- 从真实日志中抽样问题,拉上业务专家给“标答”或“评分标准”。
- 尽量覆盖多种场景:简单问答、复杂流程、多轮对话、越界问题等。
- 设计多维指标
- 准确性(Correctness)
- 覆盖度(Recall / 是否漏信息)
- 安全性(是否暴露敏感信息、是否违规)
- 可用性(是否易懂、是否给了下一步行动建议)
- 定期/自动跑评测
- 更换通义千问的不同版本号时,必须跑 eval;
- 切换 Turbo / 非 Turbo、1M / 32k 等配置,也要重新评估。
- 上线后的监控
- 记录每次模型调用的输入、输出、工具调用、延迟、错误;
- 日志中对抽样请求做人工复核,建立“反馈池”,不断更新评测集。
✅ 4️⃣ 小模型 + 大模型混合:不是只有“越大越好”
适用对象:
- 有稳定高并发业务,且成本敏感。
实践经验:
- 把任务拆成两类:
- 规则明确、特征清晰的,用小模型(或规则)解决;
- 需要自然语言理解、模糊判断的,让大模型(如通义千问2.5-72B)来兜底。
- 常见策略:
- 分流:用轻量分类模型判断“是否需要大模型参与”,只把复杂请求分给大模型;
- 级联:先用小模型尝试回答,信心不足时再调用大模型重试;
- 缓存:对高频相似问题做“向量缓存”,减少重复推理。
- 监控成本:
- 统计每个业务路径的平均Token消耗;
- 和人力成本、业务收益一并评估,而不是只看算力账单。
✨ 三个“金句”总结
- 大模型不是一个会聊天的搜索框,而是一台可以被编排、被调用的“通用智能引擎”。
- 真正落地大模型,不是多写几句提示词,而是把检索、工具调用、评测和监控都纳入工程体系。
- 看懂通义千问 这些“版本号、72B、1M、Turbo、Preview、V”的细节,比单纯喊口号更接近真实生产力。
🧷 结尾:重新理解“大模型”的三层价值
回到开头那个问题——从工程和业务视角,什么是大模型?
可以用三个关键点来收个尾,顺便帮你构建一个稍微“立体”的认知框架:
-
从技术底座看:
大模型是一类以 Transformer 为主、通过大规模预训练获得“通用语言与知识能力”的 AI 系统。
它把“理解语言、生成内容、做模糊推理”的能力封装成一个统一接口,用自然语言就能调用。
像通义千问这样的新一代通用模型,通过参数规模(如 72B)、更长上下文(如 1M)、Turbo 加速和多模态 V 版本,一步步把“底层智力”往上托。
-
从工程实践看:
真正在生产上跑的大模型系统,绝不是一个单独API,而是一整套工程化组合:
- 以 RAG 和向量检索来补足知识;
- 以 Function Calling 驱动真实业务操作;
- 以评测、监控、版本号(0314、2025-03-05 等)管理来保证可控和可持续。
大模型只是发动机,车好不好开,还得看底盘、刹车、方向盘。
-
从业务价值看:
大模型的意义不在于“换一套更聪明的聊天工具”,而在于改写我们和软件打交道的方式:
- 不用再学习复杂指令,而是“说人话”;
- 不再只给你一个冷冰冰的表单,而是给你一个会配合、会解释、会思考的“智能同事”;
- 不再仅限于“按照规则执行”,而是能在不完全信息下给出“有经验的建议”,再让人来拍板。
如果你所在的团队正在思考如何上大模型,不妨先想清楚两件事:
- 我希望它帮我解决什么具体问题?是提效、降本,还是开创新产品?
- 我有没有准备好一套“以工程为中心”的落地路径,而不仅仅是一个“可以聊天的入口”?
🙋♂️ 文末互动
- 在你所在的业务里,你觉得哪一个场景最适合先用大模型试一试?是客服、运营,还是开发与测试辅助?
- 在实际尝试大模型落地(无论是通义千问,还是其他 AI 大模型)时,你遇到过哪些“踩坑瞬间”——比如幻觉、对接混乱、评估困难?欢迎在评论里分享,我们可以后续单开一篇专门聊“坑与填坑”。
如果这篇文章对你有一点点启发,欢迎转发给更多做产品、做架构、做业务的同事,一起把“会聊天的大模型”,真正变成“能上岗的AI同事”。

本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!