
目录
在Python开发中,字符串格式化是最常用的操作之一。无论是Windows桌面应用开发、上位机数据处理,还是日志输出,我们都离不开字符串格式化。面对Python提供的三种主流格式化方式——f-strings、str.format()和百分号格式化(%),很多开发者会困惑:到底该用哪种?性能差距有多大?在实际项目中如何选择?
本文将从实战角度出发,通过详细的代码示例和性能测试,帮你彻底掌握Python字符串格式化的精髓,让你在面对不同场景时能够做出最优选择。
🔍 三种格式化方式深度解析
💫 f-strings:Python 3.6+的现代化选择
f-strings(格式化字符串字面量)是Python 3.6引入的最新格式化语法,以其简洁和高效著称。
基础语法:
Pythonname = "张三"
age = 25
score = 95.678
# 基本用法
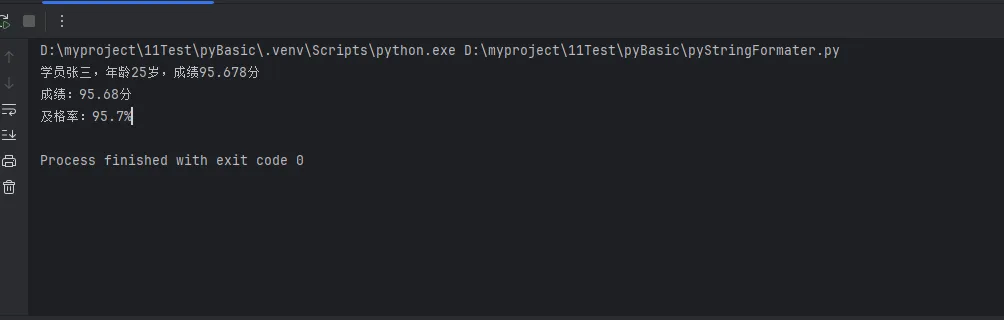
message = f"学员{name},年龄{age}岁,成绩{score}分"
print(message)
# 格式控制
formatted_score = f"成绩:{score:.2f}分" # 保留2位小数
print(formatted_score)
# 表达式计算
total_students = 100
pass_rate = f"及格率:{(score/100)*100:.1f}%"
print(pass_rate)
高级特性:
Pythonimport datetime
# 日期格式化
now = datetime.datetime.now()
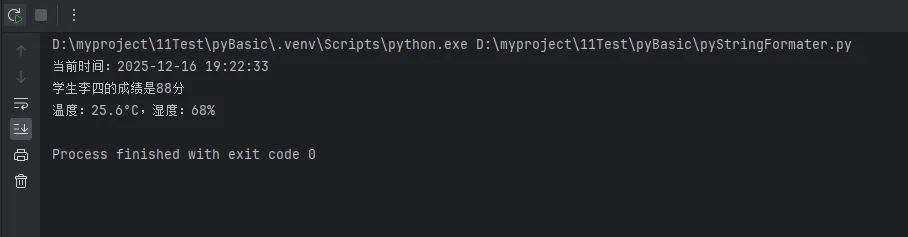
timestamp = f"当前时间:{now:%Y-%m-%d %H:%M:%S}"
print(timestamp)
# 对象属性访问
class Student:
def __init__(self, name, grade):
self.name = name
self.grade = grade
student = Student("李四", 88)
info = f"学生{student.name}的成绩是{student.grade}分"
print(info)
# 字典访问
data = {"temperature": 25.6, "humidity": 68}
report = f"温度:{data['temperature']}°C,湿度:{data['humidity']}%"
print(report)
🔧 str.format():灵活强大的经典方式
str.format()方法在Python 2.7和3.x中都可用,提供了丰富的格式化选项。
位置参数和关键字参数:
Python# 位置参数
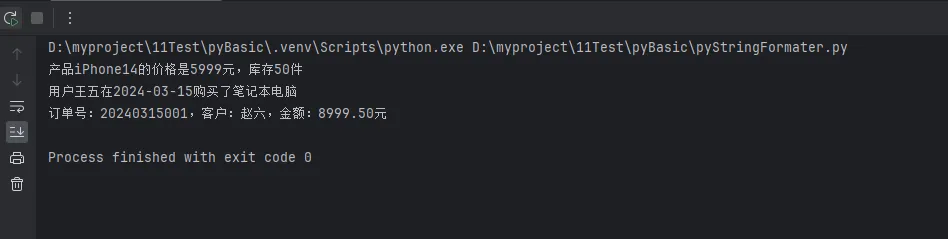
template = "产品{0}的价格是{1}元,库存{2}件"
product_info = template.format("iPhone14", 5999, 50)
print(product_info)
# 关键字参数
template = "用户{name}在{date}购买了{product}"
order_info = template.format(
name="王五",
date="2024-03-15",
product="笔记本电脑"
)
print(order_info)
# 混合使用
mixed = "订单号:{0},客户:{customer},金额:{1:.2f}元".format(
"20240315001", 8999.50, customer="赵六"
)
print(mixed)
高级格式化技巧:
Python# 数字格式化
numbers = [1234, 5678, 9999]
for num in numbers:
# 千位分隔符
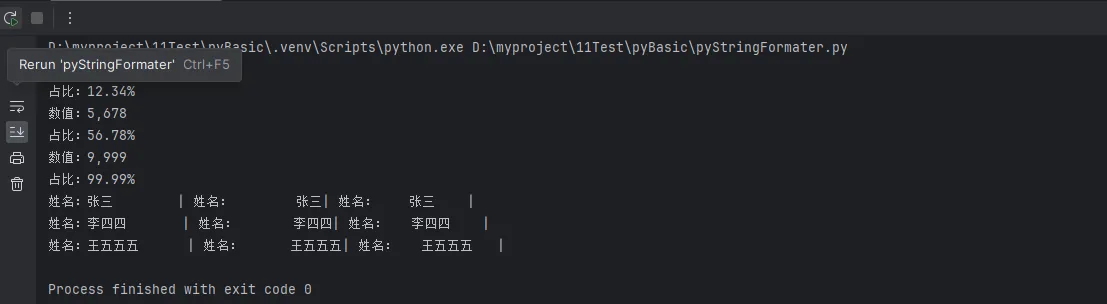
formatted = "数值:{:,}".format(num)
print(formatted)
# 百分比显示
percentage = "{:.2%}".format(num/10000)
print(f"占比:{percentage}")
# 字符串对齐
names = ["张三", "李四四", "王五五五"]
for name in names:
left_align = "姓名:{:<10}|".format(name) # 左对齐
right_align = "姓名:{:>10}|".format(name) # 右对齐
center_align = "姓名:{:^10}|".format(name) # 居中对齐
print(left_align, right_align, center_align)
📊 百分号格式化:传统但依然有效
百分号格式化是Python最古老的字符串格式化方式,类似C语言的printf。
基础用法:
Python# 基本格式
name = "陈七"
age = 30
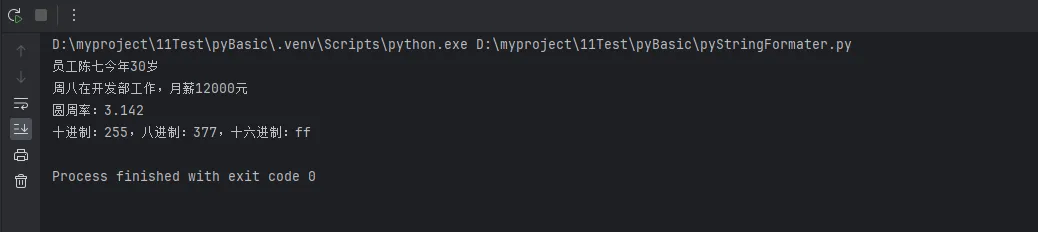
info = "员工%s今年%d岁" % (name, age)
print(info)
# 字典格式化
employee = {"name": "周八", "department": "开发部", "salary": 12000}
report = "%(name)s在%(department)s工作,月薪%(salary)d元" % employee
print(report)
# 数字格式化
pi = 3.14159
formatted_pi = "圆周率:%.3f" % pi # 保留3位小数
print(formatted_pi)
# 进制转换
number = 255
formats = "十进制:%d,八进制:%o,十六进制:%x" % (number, number, number)
print(formats)
⚡ 性能对比实战测试
让我们通过实际代码来测试三种格式化方式的性能差异:
Pythonimport timeit
import sys
def performance_test():
"""性能测试函数"""
# 测试数据
name = "测试用户"
age = 25
score = 95.678
# f-strings测试
def test_fstring():
return f"用户{name},年龄{age},分数{score:.2f}"
# str.format()测试
def test_format():
return "用户{},年龄{},分数{:.2f}".format(name, age, score)
# 百分号格式化测试
def test_percent():
return "用户%s,年龄%d,分数%.2f" % (name, age, score)
# 执行测试
test_count = 1000000
fstring_time = timeit.timeit(test_fstring, number=test_count)
format_time = timeit.timeit(test_format, number=test_count)
percent_time = timeit.timeit(test_percent, number=test_count)
# 输出结果
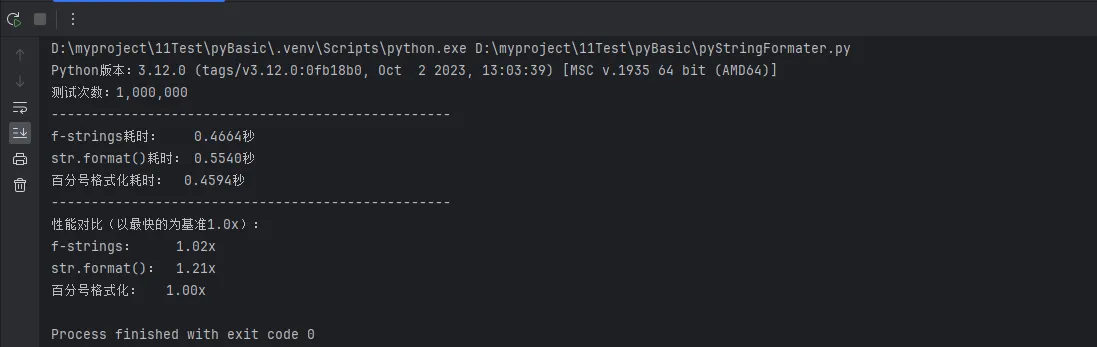
print(f"Python版本:{sys.version}")
print(f"测试次数:{test_count:,}")
print("-" * 50)
print(f"f-strings耗时: {fstring_time:.4f}秒")
print(f"str.format()耗时: {format_time:.4f}秒")
print(f"百分号格式化耗时: {percent_time:.4f}秒")
print("-" * 50)
# 计算性能比率
fastest = min(fstring_time, format_time, percent_time)
print("性能对比(以最快的为基准1.0x):")
print(f"f-strings: {fstring_time/fastest:.2f}x")
print(f"str.format(): {format_time/fastest:.2f}x")
print(f"百分号格式化: {percent_time/fastest:.2f}x")
if __name__ == "__main__":
performance_test()
典型测试结果分析:
在大多数现代Python环境中,性能排序通常是:
- f-strings - 最快(1.0x基准)
- 百分号格式化 - 中等(约1.2-1.5x)
- str.format() - 最慢(约1.5-2.0x)
🎯 实际项目选择指南
🔥 推荐使用f-strings的场景
1. 现代Python项目(3.6+)
Python# Windows应用日志记录
import logging
from datetime import datetime
class AppLogger:
def __init__(self):
self.logger = logging.getLogger(__name__)
def log_user_action(self, user_id, action, timestamp):
# f-strings让日志格式化更清晰
message = f"用户[{user_id}]在{timestamp:%Y-%m-%d %H:%M:%S}执行了{action}"
self.logger.info(message)
# 使用示例
logger = AppLogger()
logger.log_user_action("USER_001", "登录系统", datetime.now())
2. 数据处理和分析
Python# 上位机数据监控
def format_sensor_data(sensor_id, temperature, humidity, pressure):
# 实时数据格式化
return f"传感器{sensor_id}: 温度{temperature:.1f}°C | 湿度{humidity:.1f}% | 气压{pressure:.2f}hPa"
# 批量处理传感器数据
sensor_readings = [
(1, 25.6, 68.3, 1013.25),
(2, 26.1, 65.8, 1012.89),
(3, 24.9, 70.2, 1013.67)
]
for reading in sensor_readings:
formatted = format_sensor_data(*reading)
print(formatted)

⚙️ str.format()的适用场景
1. 模板化字符串
Python# 报表模板系统
class ReportTemplate:
def __init__(self):
self.template = """
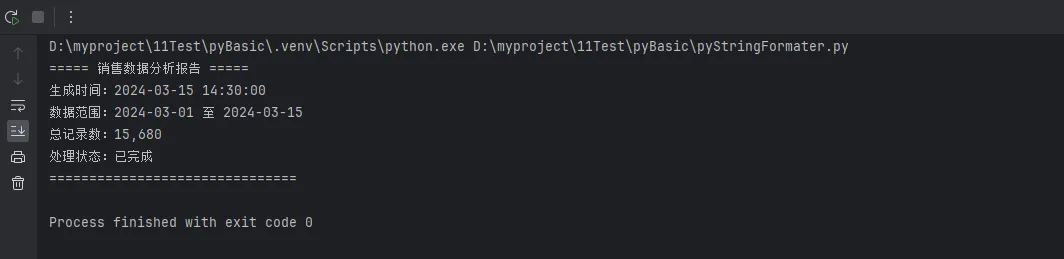
===== {title} =====
生成时间:{generate_time}
数据范围:{start_date} 至 {end_date}
总记录数:{total_count:,}
处理状态:{status}
===============================
""".strip()
def generate_report(self, **kwargs):
return self.template.format(**kwargs)
# 使用示例
template = ReportTemplate()
report = template.generate_report(
title="销售数据分析报告",
generate_time="2024-03-15 14:30:00",
start_date="2024-03-01",
end_date="2024-03-15",
total_count=15680,
status="已完成"
)
print(report)
2. 国际化支持
Python# 多语言字符串格式化
MESSAGES = {
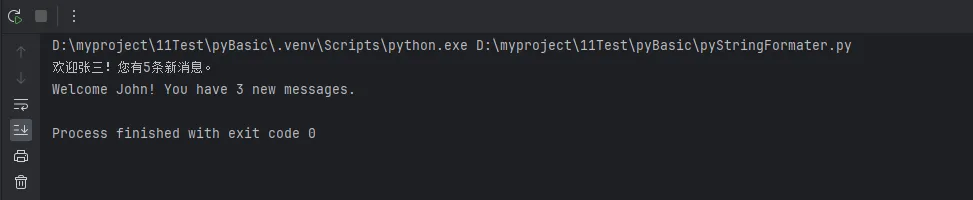
'zh': "欢迎{username}!您有{count}条新消息。",
'en': "Welcome {username}! You have {count} new messages."
}
def get_welcome_message(language, username, message_count):
template = MESSAGES.get(language, MESSAGES['en'])
return template.format(username=username, count=message_count)
# 测试不同语言
print(get_welcome_message('zh', '张三', 5))
print(get_welcome_message('en', 'John', 3))
📋 百分号格式化的保留场景
1. 日志格式化(兼容性考虑)
Pythonimport logging
# 配置日志格式,某些旧系统仍然使用百分号格式
logging.basicConfig(
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
level=logging.INFO
)
# 在日志消息中使用
logger = logging.getLogger(__name__)
user_id = "USER_001"
operation = "数据导出"
logger.info("用户%s执行%s操作", user_id, operation)
2. SQL查询字符串构建
Python# 数据库查询(注意:实际项目中推荐使用参数化查询)
def build_query_log(table_name, condition_count, order_field):
"""构建查询日志信息"""
log_message = "执行查询:表[%s],条件数量[%d],排序字段[%s]" % (
table_name, condition_count, order_field
)
return log_message
query_log = build_query_log("user_info", 3, "create_time")
print(query_log)

🎯 总结与选择建议
通过详细的分析和实战测试,我们可以得出以下三个核心要点:
🚀 性能优先选择:在Python 3.6+的现代项目中,f-strings是首选方案,它不仅性能最优(比其他方式快20-50%),而且语法简洁直观,特别适合Windows应用开发和上位机编程中的实时数据处理场景。
🔧 场景化应用:str.format()在需要模板化、国际化支持或复杂格式控制时仍有优势;百分号格式化主要保留在日志系统和需要与旧代码兼容的场景中。选择合适的格式化方式要根据具体的业务需求和技术环境来决定。
💡 代码质量提升:无论选择哪种格式化方式,都要注重代码的可读性和安全性。避免过长的格式化字符串,对用户输入进行适当的清理和验证,这样才能写出既高效又安全的Python代码。
掌握了这些字符串格式化技巧,你就能在Python开发中游刃有余,无论是构建桌面应用、处理数据分析,还是开发上位机系统,都能选择最合适的方案,让代码既优雅又高效!
想了解更多Python开发技巧?关注我们,获取更多实战经验分享!
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!