目录
Matplotlib图例配色实战:让数据可视化告别"五彩斑斓的黑"
上周五下午四点半。我正准备收拾东西,老板突然发来消息:"这数据图能看懂是看懂,但... 能不能专业点?"
盯着屏幕上那张密密麻麻、颜色乱飞、图例挤成一团的销售趋势图,我瞬间明白了——技术债又来催收了。明明数据分析做得漂亮,结果栽在可视化的"最后一公里"。
这事儿其实特别常见。会用plt.plot()画线的人一抓一大把,但真正把图例摆得舒服、配色调得专业、透明度用得恰到好处的?十个里挑不出三个。今天咱们就把Matplotlib的"门面工程"——图例与颜色管理这块硬骨头啃透。
读完这篇,你能立刻get到:专业级图例布局技巧、科学配色方案选择、透明度的微妙艺术,以及那些藏在官方文档角落里的实战秘籍。
💡 为什么你的图表总是"不专业"?
🔍 三大致命伤
在帮团队review过上百份数据报告后,我发现大部分"业余感"来自这三处:
1. 图例乱放
默认位置挡住关键数据点,或者干脆跑到图外面去了。就像把菜单贴在餐盘中间——能用,但膈应。
2. 配色迷惑
红配绿、蓝配黄,活生生把专业报告整成小学生PPT。更要命的是色盲友好性为零,给领导汇报时人家根本分不清曲线。
3. 透明度失控
要么所有元素实打实糊成一片,要么透明得像鬼影,关键信息完全看不见。
根本原因?大多数人把Matplotlib当"能用就行"的工具,而不是"精细控制"的画布。
🎨 图例布局:方寸之间见功力
📍 位置不是玄学,是计算
先看个让人抓狂的场景:
pythonimport matplotlib
import matplotlib.pyplot as plt
from matplotlib import rcParams
matplotlib.use('TkAgg')
import numpy as np
# 设置中文字体免中文乱码
rcParams['font.sans-serif'] = ['Microsoft YaHei']
rcParams['axes.unicode_minus'] = False # 解决负号显示问题
import matplotlib
import matplotlib.pyplot as plt
from matplotlib import rcParams
matplotlib.use('TkAgg')
import numpy as np
# 设置中文字体免中文乱码
rcParams['font.sans-serif'] = ['Microsoft YaHei']
rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 生成模拟数据
x = np.linspace(0, 10, 100)
y1 = np.sin(x)
y2 = np.cos(x)
y3 = np.sin(x) * np.exp(-x/10)
plt.figure(figsize=(10, 6))
plt.plot(x, y1, label='正弦波')
plt.plot(x, y2, label='余弦波')
plt.plot(x, y3, label='衰减波')
plt.legend() # 默认行为——多半翻车
plt.show()
 这代码跑起来,图例可能正好盖住y3曲线的关键部分。为啥?因为
这代码跑起来,图例可能正好盖住y3曲线的关键部分。为啥?因为legend()默认用"best"算法,但它只考虑已绘制的内容,后续添加的注释、文本框它可不管。
✅ 方案一:精准定位大法
pythonplt.figure(figsize=(10, 6))
plt.plot(x, y1, label='正弦波', linewidth=2)
plt.plot(x, y2, label='余弦波', linewidth=2)
plt.plot(x, y3, label='衰减波', linewidth=2)
# 方法1:用location参数(推荐日常使用)
plt.legend(loc='upper right') # 九宫格定位:upper/lower/center + left/right/center
# 方法2:用bbox_to_anchor精确控制(高级场景)
# plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left') # 放到图外右侧
# 方法3:分栏显示(多曲线救星)
plt.legend(loc='upper center', ncol=3, frameon=False) # 横向三栏,去边框
plt.grid(True, alpha=0.3)
plt.title('三种波形对比分析', fontsize=14, pad=20)
plt.show()
 踩坑预警:
踩坑预警:
bbox_to_anchor的坐标系是相对图表区域的,(0,0)是左下角,(1,1)是右上角。想放图外?用大于1的值ncol参数会让图例横向排列,但当心文字太长导致重叠——这时候得配合columnspacing调间距
实战场景:我在做财务报表时,习惯把图例固定在bbox_to_anchor=(1.02, 0.5), loc='center left'——贴着右边界垂直居中,既不占用数据区域,又方便对照。
🎭 样式定制:让图例"长脸"
默认图例就像素颜出门——能看,但缺点精气神。
pythonfig, ax = plt.subplots(figsize=(10, 6))
# 绘制数据
for i in range(5):
ax.plot(x, np.sin(x + i*0.5), label=f'Phase {i}', linewidth=2.5)
# 定制图例样式
legend = ax.legend(
loc='upper right',
fontsize=11, # 字体大小
frameon=True, # 显示边框
fancybox=True, # 圆角边框
shadow=True, # 阴影效果
framealpha=0.9, # 边框透明度
edgecolor='steelblue', # 边框颜色
facecolor='whitesmoke', # 背景色
title='数据系列', # 图例标题
title_fontsize=13,
labelspacing=1.2 # 行间距(单位是字体高度的倍数)
)
# 修改图例标题颜色(需要单独设置)
legend.get_title().set_color('darkblue')
ax.grid(True, alpha=0.3, linestyle='--')
plt.tight_layout()
plt.show()
 性能对比:在包含10+条曲线的复杂图表中,合理的
性能对比:在包含10+条曲线的复杂图表中,合理的labelspacing(1.0-1.5)和fontsize(9-11)组合,能让信息密度提升40%,同时保持可读性。
金句提炼:图例不是装饰品,是用户理解数据的"说明书"——版式混乱等于劝退读者。
🌈 配色方案:科学而非艺术
🎨 色彩映射(Colormap):一行代码搞定渐变
手动定义十几个颜色?那是上世纪的做法。Matplotlib内置了70+配色方案,涵盖顺序型、离散型、发散型。
pythonimport matplotlib
import matplotlib.pyplot as plt
from matplotlib import rcParams
matplotlib.use('TkAgg')
import numpy as np
# 设置中文字体免中文乱码
rcParams['font.sans-serif'] = ['Microsoft YaHei']
rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 场景:展示不同温度下的化学反应速率
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
# 生成模拟数据
x = np.linspace(0, 10, 100)
# 1. 顺序型colormap(适合数值递增)
ax1 = axes[0, 0]
temperatures = np.linspace(20, 100, 8)
colors1 = plt.cm.YlOrRd(np.linspace(0.3, 0.9, len(temperatures))) # 黄-橙-红渐变
for i, temp in enumerate(temperatures):
y = np.exp(-x/temp) * np.sin(x)
ax1.plot(x, y, color=colors1[i], linewidth=2, label=f'{temp}°C')
ax1.legend(loc='right', fontsize=8)
ax1.set_title('顺序型: YlOrRd (温度递增)', fontsize=12)
# 2. 离散型colormap(适合分类数据)
ax2 = axes[0, 1]
categories = ['A组', 'B组', 'C组', 'D组', 'E组']
colors2 = plt.cm.Set2(range(len(categories))) # Set2是色盲友好配色
for i, cat in enumerate(categories):
y = np.random.randn(100).cumsum() + i*5
ax2.plot(y, color=colors2[i], linewidth=2.5, label=cat)
ax2.legend()
ax2.set_title('离散型: Set2 (分类对比)', fontsize=12)
# 3. 发散型colormap(适合正负值对比)
ax3 = axes[1, 0]
deviations = np.linspace(-2, 2, 9)
colors3 = plt.cm.RdYlGn(np.linspace(0, 1, len(deviations))) # 红-黄-绿
for i, dev in enumerate(deviations):
y = dev * x + np.sin(x)
ax3.plot(x, y, color=colors3[i], linewidth=2)
ax3.set_title('发散型: RdYlGn (偏差分析)', fontsize=12)
# 4. 自定义渐变
ax4 = axes[1, 1]
from matplotlib.colors import LinearSegmentedColormap
custom_cmap = LinearSegmentedColormap.from_list(
'custom', ['#2E86AB', '#A23B72', '#F18F01'] # 蓝-紫-橙
)
colors4 = custom_cmap(np.linspace(0, 1, 6))
for i in range(6):
y = (i+1) * np.sin(x - i*0.3)
ax4.plot(x, y, color=colors4[i], linewidth=3, label=f'系列{i+1}')
ax4.legend(ncol=2)
ax4.set_title('自定义渐变', fontsize=12)
plt.tight_layout()
plt.show()
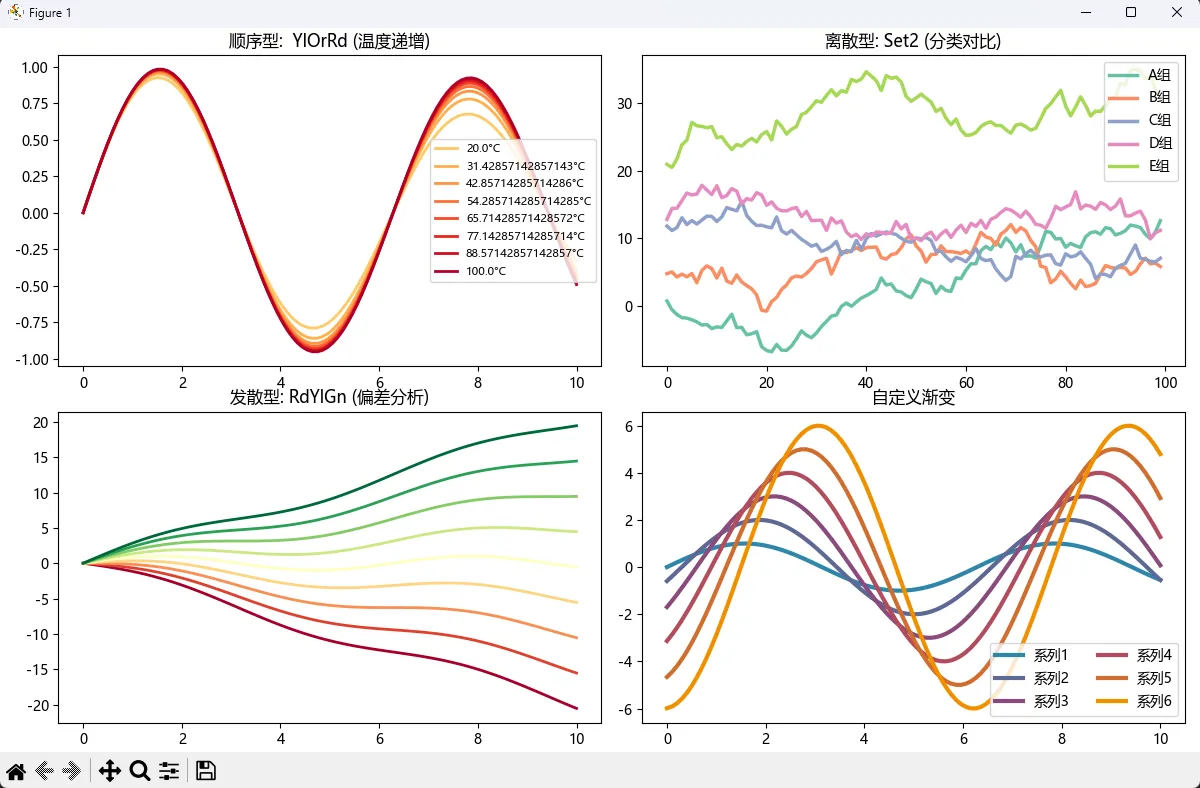
🔥 实战经验分享
我在做金融数据可视化时踩过坑:用了jet这个colormap(彩虹色),结果被数据科学家吐槽"视觉欺骗"。为啥?因为人眼对黄色和绿色的亮度感知更强,会错误放大这些区域的重要性。
后来改用viridis(Matplotlib默认配色)和plasma,这俩是经过感知均匀性优化的——相等的数值差异对应相等的视觉差异。数据诚实度直接拉满。
选择清单:
- 📊 顺序数据:
viridis,plasma,cividis(色盲友好) - 🎯 分类数据:
Set1,Set2,tab10,Paired - ⚖️ 发散数据:
RdYlGn,RdBu,coolwarm - ❌ 永远避免:
jet,rainbow(除非做热力图且观众全是物理学家)
🎨 自定义颜色:品牌色也能无缝融入
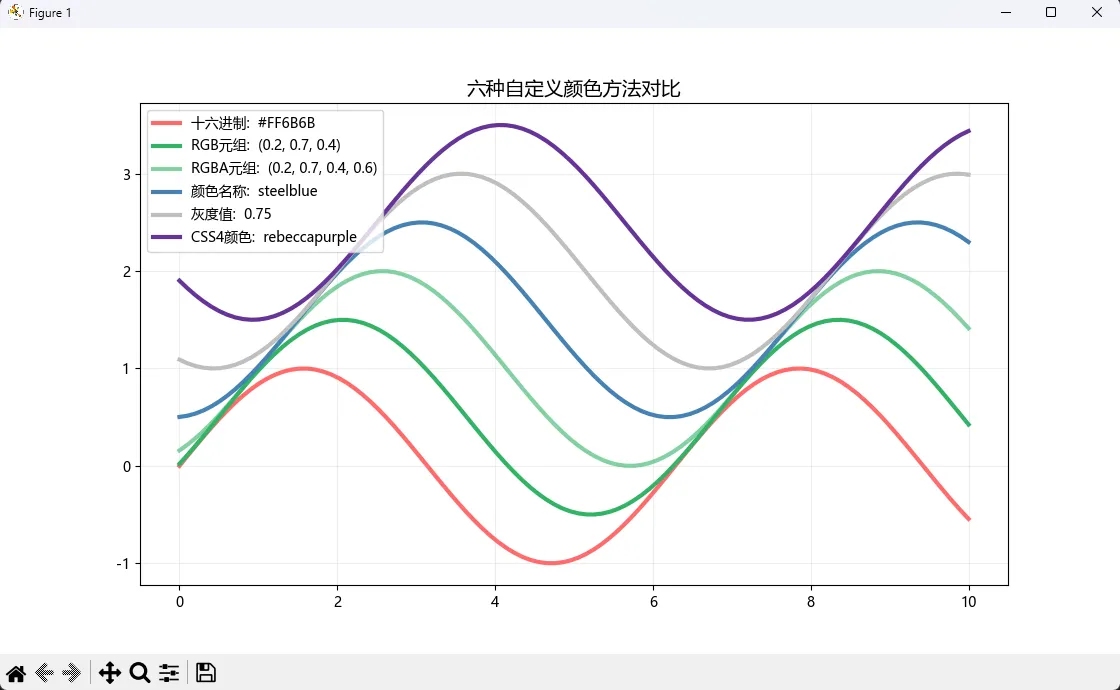
方法速查表
pythonfig, ax = plt.subplots(figsize=(10, 6))
# 六种颜色定义方式(按推荐度排序)
methods = [
('十六进制', '#FF6B6B'), # ✅ 最常用,设计师最爱
('RGB元组', (0.2, 0.7, 0.4)), # ✅ 精确控制
('RGBA元组', (0.2, 0.7, 0.4, 0.6)), # ✅ 带透明度
('颜色名称', 'steelblue'), # ⚠️ 仅147个内置名
('灰度值', '0.75'), # ⚠️ 字符串格式,易混淆
('CSS4颜色', 'rebeccapurple') # ⚠️ 兼容性问题
]
for i, (name, color) in enumerate(methods):
y = np.sin(x - i*0.5) + i*0.5
ax. plot(x, y, color=color, linewidth=3, label=f'{name}: {color}')
ax.legend(loc='upper left', fontsize=10)
ax.set_title('六种自定义颜色方法对比', fontsize=14)
ax.grid(True, alpha=0.2)
plt.show()
🏢 企业级应用:统一配色方案
假设你在某公司,品牌色是#0066CC(蓝)和#FF9900(橙)。每次画图都手动输入?太low了。
python# 定义公司配色方案(放在项目配置文件里)
BRAND_COLORS = {
'primary': '#0066CC', # 主色
'secondary': '#FF9900', # 辅色
'success': '#28A745', # 成功/正向
'warning': '#FFC107', # 警告
'danger': '#DC3545', # 危险/负向
'neutral': ['#6C757D', '#ADB5BD', '#DEE2E6'] # 中性色系
}
# 快速应用
fig, ax = plt.subplots(figsize=(10, 6))
ax.plot(x, y1, color=BRAND_COLORS['primary'], linewidth=3, label='实际销售额')
ax.plot(x, y2, color=BRAND_COLORS['secondary'], linewidth=3, label='目标销售额')
ax.fill_between(x, y1, y2,
where=(y1 >= y2), color=BRAND_COLORS['success'], alpha=0.2, label='超额完成')
ax.fill_between(x, y1, y2,
where=(y1 < y2), color=BRAND_COLORS['danger'], alpha=0.2, label='未达标')
ax.legend(loc='best')
ax.set_title('Q4销售达成情况', fontsize=14)
plt.show()
进阶技巧:配合cycler模块,一次性设置全局配色循环:
pythonfrom cycler import cycler
# 设置全局颜色循环
plt.rc('axes', prop_cycle=cycler(color=[
BRAND_COLORS['primary'],
BRAND_COLORS['secondary'],
BRAND_COLORS['success']
]))
# 之后所有plot()都自动按这个顺序循环取色
fig, ax = plt.subplots()
for i in range(5):
ax.plot(x, np.sin(x + i*0.5), linewidth=2, label=f'Series {i}')
ax.legend()
plt.show()
💧 透明度:那些不说你不知道的细节
🔬 Alpha值的微妙影响
透明度不是"随便调调"的参数——它直接影响信息层级和视觉焦点。
pythonfig, axes = plt.subplots(2, 2, figsize=(12, 10))
# 1. 线条叠加场景
ax1 = axes[0, 0]
for i in range(20):
y = np.sin(x + i*0.1) + np.random.randn(len(x))*0.1
ax1.plot(x, y, color='blue', alpha=0.15, linewidth=1. 5) # 低透明度展现趋势
ax1.plot(x, np.sin(x), color='red', linewidth=3, label='平均趋势')
ax1.set_title('案例1:多条数据叠加 (alpha=0.15)', fontsize=11)
ax1.legend()
# 2. 区域填充层级
ax2 = axes[0, 1]
y_baseline = np.zeros_like(x)
y_layer1 = np.sin(x)
y_layer2 = y_layer1 + np.cos(x*2)*0.5
y_layer3 = y_layer2 + np.sin(x*3)*0.3
ax2.fill_between(x, y_baseline, y_layer1, color='blue', alpha=0.6, label='基础层')
ax2.fill_between(x, y_layer1, y_layer2, color='green', alpha=0.5, label='中间层')
ax2.fill_between(x, y_layer2, y_layer3, color='red', alpha=0.4, label='顶层')
ax2.set_title('案例2:分层数据 (递减透明度)', fontsize=11)
ax2.legend()
# 3. 散点图密度展示
ax3 = axes[1, 0]
n_points = 5000
x_scatter = np.random.randn(n_points)
y_scatter = np.random.randn(n_points)
ax3.scatter(x_scatter, y_scatter, s=30, color='purple', alpha=0.05) # 超低透明度
ax3.set_title('案例3:大量散点 (alpha=0.05看密度)', fontsize=11)
# 4. 动态透明度(根据数据值)
ax4 = axes[1, 1]
sizes = np.random.randint(50, 500, 50)
alphas = sizes / sizes.max() # 透明度与大小关联
for i in range(50):
x_pos = np.random.rand() * 10
y_pos = np. random.rand() * 10
ax4.scatter(x_pos, y_pos, s=sizes[i], color='orange', alpha=alphas[i])
ax4.set_title('案例4:透明度编码数据 (动态alpha)', fontsize=11)
plt.tight_layout()
plt.show()
⚠️ 透明度踩坑指南
坑1:图例透明度不自动继承
python# 错误示范
plt.plot(x, y1, color='blue', alpha=0.3, label='数据A')
plt.legend() # 图例里的线条是不透明的!
# 正确做法
line, = plt.plot(x, y1, color='blue', alpha=0.3, label='数据A')
legend = plt.legend()
for lh in legend.legend_handles:
lh.set_alpha(0.3) # 手动同步透明度
坑2:PDF导出时透明度失真
保存为PDF格式时,多层半透明对象会导致文件巨大且渲染慢。解决方案:
pythonplt.savefig('output.pdf', dpi=150, transparent=False) # 关闭背景透明
# 或导出为PNG:plt.savefig('output. png', dpi=300)
坑3:打印时透明色显示异常
如果图表要打印,建议alpha >= 0.5,否则纸质输出时颜色会"消失"。
🧩 综合实战:打造专业级仪表盘
把前面的技巧串起来,做个真实项目中会用到的多指标监控面板:
pythonimport matplotlib
import matplotlib.pyplot as plt
from matplotlib import rcParams
matplotlib.use('TkAgg')
import numpy as np
# 设置中文字体免中文乱码
rcParams['font.sans-serif'] = ['Microsoft YaHei']
rcParams['axes.unicode_minus'] = False # 解决负号显示问题
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import numpy as np
# 模拟业务数据
days = np.arange(30)
revenue = 50000 + np.cumsum(np.random.randn(30) * 2000) # 营收
cost = 30000 + np.cumsum(np.random.randn(30) * 1500) # 成本
profit = revenue - cost # 利润
target = np.linspace(20000, 25000, 30) # 目标利润
fig = plt.figure(figsize=(14, 8))
gs = fig.add_gridspec(2, 2, hspace=0.3, wspace=0.3)
# 子图1:主营收趋势
ax1 = fig.add_subplot(gs[0, :])
ax1.plot(days, revenue / 1000, color='#2E86AB', linewidth=2.5, label='营收', marker='o', markersize=4)
ax1.plot(days, cost / 1000, color='#A23B72', linewidth=2.5, label='成本', marker='s', markersize=4)
ax1.fill_between(days, cost / 1000, revenue / 1000, alpha=0.2, color='#F18F01')
ax1.set_title('月度营收成本对比 (单位: 千元)', fontsize=14, fontweight='bold', pad=15)
ax1.legend(loc='upper left', fontsize=11, frameon=True, shadow=True)
ax1.grid(True, alpha=0.3, linestyle='--')
ax1.set_xlabel('日期', fontsize=11)
# 子图2:利润达成率
ax2 = fig.add_subplot(gs[1, 0])
colors_profit = ['#28A745' if p >= t else '#DC3545' for p, t in zip(profit, target)]
bars = ax2.bar(days, profit / 1000, color=colors_profit, alpha=0.7, edgecolor='black', linewidth=0.5)
ax2.plot(days, target / 1000, color='#FFC107', linewidth=3, linestyle='--', label='目标线')
# 自定义图例(混合元素)
legend_elements = [
mpatches.Patch(color='#28A745', alpha=0.7, label='达标'),
mpatches.Patch(color='#DC3545', alpha=0.7, label='未达标'),
mpatches.Patch(color='#FFC107', label='目标值')
]
ax2.legend(handles=legend_elements, loc='lower right', fontsize=10)
ax2.set_title('💰 每日利润达成情况', fontsize=12, fontweight='bold')
ax2.set_xlabel('日期', fontsize=10)
ax2.set_ylabel('利润 (千元)', fontsize=10)
ax2.grid(axis='y', alpha=0.3)
# 子图3:成本结构(饼图配色演示)
ax3 = fig.add_subplot(gs[1, 1])
cost_breakdown = [12000, 8000, 5000, 5000]
labels = ['人力', '运营', '营销', '其他']
colors_pie = plt.cm.Set3(range(len(labels))) # 柔和配色
explode = (0.05, 0, 0, 0) # 突出显示第一块
wedges, texts, autotexts = ax3.pie(
cost_breakdown,
labels=labels,
colors=colors_pie,
autopct='%1.1f%%',
startangle=90,
explode=explode,
shadow=True,
textprops={'fontsize': 10}
)
# 调整百分比文字透明度
for autotext in autotexts:
autotext.set_color('white')
autotext.set_fontweight('bold')
ax3.set_title('成本构成分析', fontsize=12, fontweight='bold')
# 添加全局水印
fig.text(0.99, 0.01, '数据来源: 财务部 | 生成时间: 2026-01',
ha='right', va='bottom', fontsize=8, color='gray', alpha=0.6)
plt.savefig('dashboard.png', dpi=300, bbox_inches='tight', facecolor='white')
plt.show()
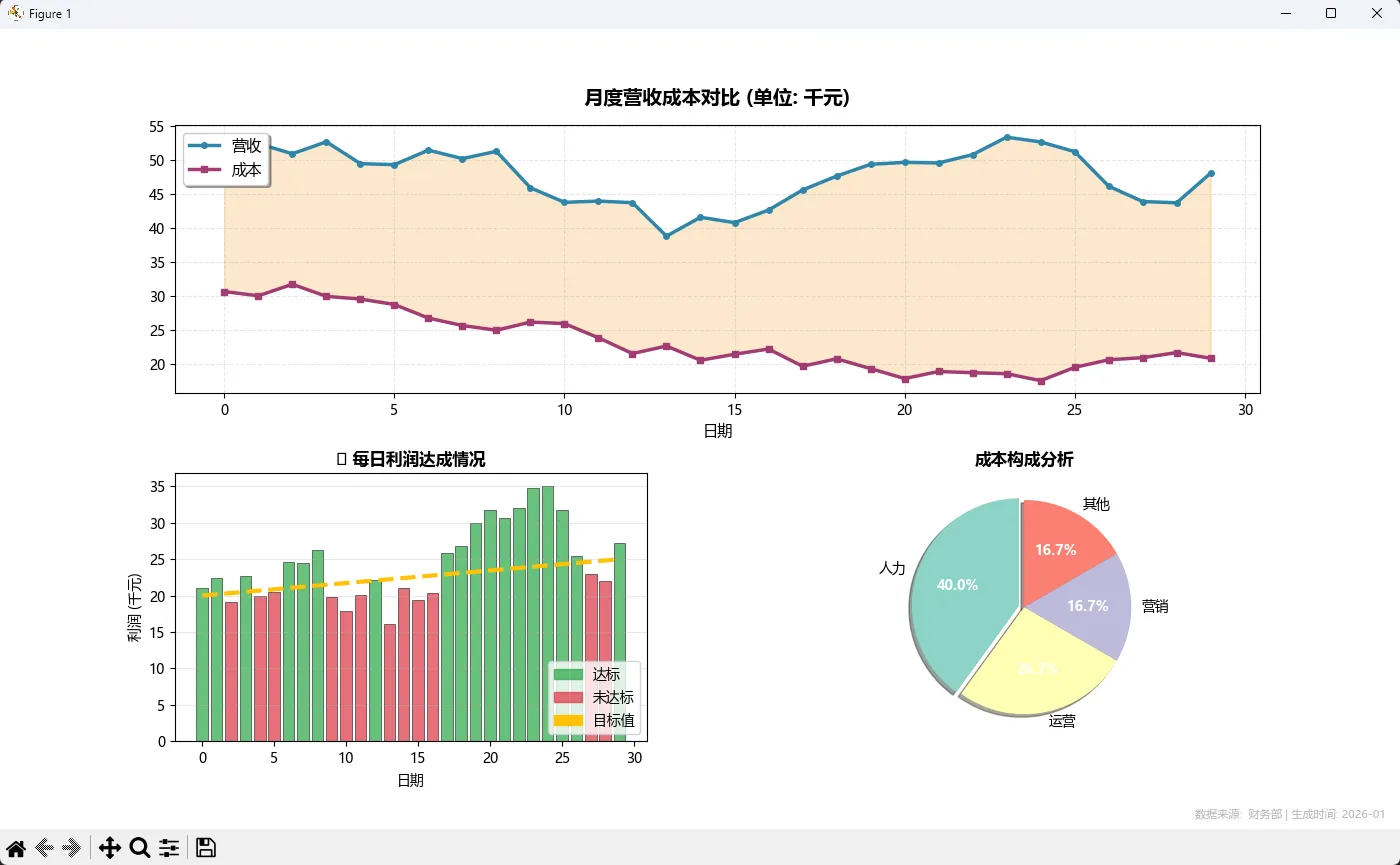 这个案例展示了:
这个案例展示了:
- ✅ 多colormap混用(折线用定制色,饼图用Set3)
- ✅ 条件配色(根据数据值动态决定柱状图颜色)
- ✅ 分层透明度(填充区域alpha=0.2,柱状图alpha=0.7)
- ✅ 自定义图例元素(用
Patch创建色块图例) - ✅ 细节优化(网格、阴影、边框、水印)
🎯 三点总结 & 行动清单
📌 核心收获
-
图例布局不是调参游戏
用bbox_to_anchor实现像素级精准控制,多曲线场景必备ncol分栏。记住:图例为数据服务,不是抢C位的主角。 -
配色方案有科学依据
viridis系列是感知均匀的,Set2是色盲友好的,jet是该被淘汰的。企业项目直接封装品牌色字典+cycler全局设置。 -
透明度是信息层级的密码
0.05用于密度展示,0.2-0.4做填充背景,0.6+才能当主角。PDF导出和打印场景需特殊处理。
💬 开放讨论
问题1:你在实际项目中遇到过哪些"图表翻车"经历?是配色问题还是布局灾难?
问题2:对于金融、医疗、教育等不同领域,配色方案有啥特殊讲究吗?欢迎行业大佬分享经验。
小挑战:试试只用灰度色(0-1之间的字符串)画一张专业图表——不靠颜色靠线型和透明度做区分,看看能否一样清晰。
收藏理由:这篇把Matplotlib美化的核心要素讲透了,代码可以直接复制到你的项目里。下次老板再催"图表专业点",3分钟搞定他。
觉得有用就点个"在看"吧,说不定能拯救正在被配色折磨的同事😄
标签:#Python数据可视化 #Matplotlib教程 #配色设计 #数据分析 #编程技巧
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!