目录
昨天有同事向我咨询了这个问题,我发现了一种新的方法来处理字符串的聚合与分割,你是否为了分割一个包含多个值的字符串字段而不得不编写复杂的循环代码?
作为数据库开发者,我们经常遇到这样的场景:
- 需要将员工的多个技能合并显示:
"Java,Python,SQL" - 要将订单的多个商品ID拆分成单独的记录进行处理
- 统计报表中需要动态拼接查询条件
如果你还在使用传统的游标循环或复杂的XML PATH方法,那你就OUT了!SQL Server为我们提供了两个强大的内置函数:STRING_AGG 和 STRING_SPLIT,它们能让这些操作变得异常简单和高效。
本文将通过实战案例,带你掌握这两个函数的精髓,让你的SQL代码更加优雅和高效!
🔥 STRING_AGG:多行变一行的艺术
💡 问题分析:传统聚合的痛点
在SQL Server 2017之前,我们要实现多行数据的字符串聚合,通常需要这样写:
SQL-- 老式写法:复杂且难理解
SELECT STUFF((
SELECT ',' + skill_name
FROM employee_skills e2
WHERE e2.employee_id = e1.employee_id
FOR XML PATH('')
), 1, 1, '') AS skills
FROM employees e1;
这种写法不仅代码冗长,性能也不够理想,这个写法在以前基本这第干了。
⚡ STRING_AGG:优雅的解决方案
基础语法:
SQLSTRING_AGG(expression, separator) [WITHIN GROUP (ORDER BY order_expression)]
🛠️ 实战案例1:员工技能聚合
SQL-- 创建测试数据
CREATE TABLE #employees (
employee_id INT,
employee_name NVARCHAR(50)
);
CREATE TABLE #employee_skills (
employee_id INT,
skill_name NVARCHAR(50),
skill_level INT
);
INSERT INTO #employees VALUES
(1, '张三'), (2, '李四'), (3, '王五');
INSERT INTO #employee_skills VALUES
(1, 'Java', 5), (1, 'Python', 4), (1, 'SQL', 5),
(2, 'C#', 4), (2, 'JavaScript', 3),
(3, 'Python', 5), (3, 'React', 4), (3, 'Node.js', 3);
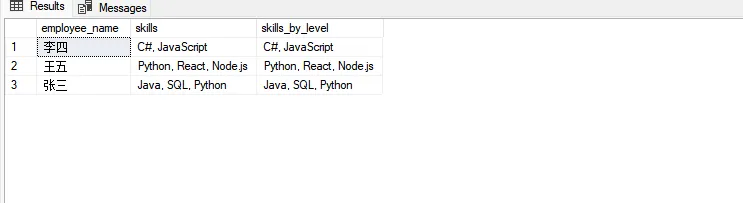
SQLSELECT
e.employee_name,
STRING_AGG(s.skill_name, ', ') AS skills,
STRING_AGG(s.skill_name, ', ') WITHIN GROUP (ORDER BY s.skill_level DESC) AS skills_by_level
FROM #employees e
LEFT JOIN #employee_skills s ON e.employee_id = s.employee_id
GROUP BY e.employee_id, e.employee_name;
🎯 实战案例2:动态SQL构建
SQL-- 创建分类表
CREATE TABLE #categories (
category_id INT PRIMARY KEY,
category_name NVARCHAR(50),
is_active BIT,
create_date DATETIME
);
-- 创建商品表
CREATE TABLE #products (
product_id INT PRIMARY KEY,
product_name NVARCHAR(100),
category_id INT,
price DECIMAL(10,2),
stock_quantity INT
);
-- 插入分类数据
INSERT INTO #categories VALUES
(1, '电子产品', 1, '2024-01-01'),
(2, '服装鞋帽', 0, '2024-01-02'), -- 未激活
(3, '家居用品', 1, '2024-01-03'),
(4, '图书音像', 0, '2024-01-04'), -- 未激活
(5, '运动户外', 1, '2024-01-05'),
(6, '美妆护肤', 1, '2024-01-06'),
(7, '食品饮料', 1, '2024-01-07'),
(8, '汽车用品', 0, '2024-01-08'), -- 未激活
(9, '母婴用品', 1, '2024-01-09');
-- 插入商品数据
INSERT INTO #products VALUES
(101, 'iPhone 15', 1, 7999.00, 50),
(102, '耐克运动鞋', 2, 599.00, 0),
(103, '宜家书架', 3, 299.00, 20),
(104, '编程书籍', 4, 89.00, 15),
(105, '瑜伽垫', 5, 128.00, 30),
(106, '兰蔻面霜', 6, 458.00, 25),
(107, '有机牛奶', 7, 25.00, 100),
(108, '汽车香水', 8, 39.00, 12),
(109, '婴儿奶粉', 9, 298.00, 40);
SQL-- 构建动态WHERE条件
DECLARE @category_ids NVARCHAR(MAX);
DECLARE @sql NVARCHAR(MAX);
-- 获取所有激活的分类ID
SELECT @category_ids = STRING_AGG(CAST(category_id AS NVARCHAR), ',')
FROM #categories
WHERE is_active = 1;
PRINT '激活的分类ID: ' + @category_ids;
-- 输出:激活的分类ID: 1,3,5,6,7,9
-- 构建完整的动态SQL
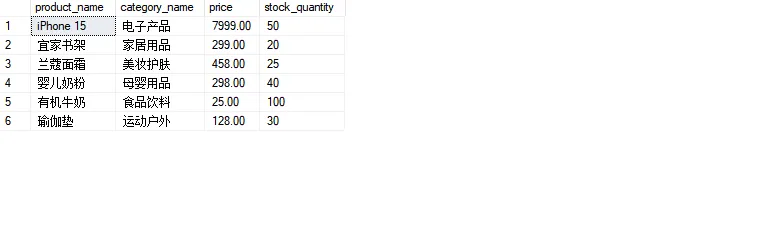
SET @sql = '
SELECT
p.product_name,
c.category_name,
p.price,
p.stock_quantity
FROM #products p
JOIN #categories c ON p.category_id = c.category_id
WHERE p.category_id IN (' + @category_ids + ')
AND p.stock_quantity > 0
ORDER BY c.category_name, p.price DESC';
PRINT '动态SQL:';
PRINT @sql;
-- 执行动态SQL
EXEC sp_executesql @sql;
⚠️ 常见坑点提醒
- NULL值处理:STRING_AGG会忽略NULL值
- 数据类型:确保聚合的列是字符串类型,数值需要CAST转换
- 长度限制:结果字符串最大长度为8000(NVARCHAR(MAX)除外)
SQL-- 🚨 错误示例
SELECT STRING_AGG(employee_id, ',') FROM employees; -- 报错:数据类型
-- ✅ 正确示例
SELECT STRING_AGG(CAST(employee_id AS NVARCHAR), ',') FROM employees;
🔧 STRING_SPLIT:一行变多行的魔法
💡 问题场景:字符串分割的需求
假设你有这样的数据:
- 商品标签字段:
"电子产品,数码配件,热销商品" - 权限字段:
"read,write,delete,admin"
需要将这些数据拆分成独立的记录进行查询和统计。
⚡ STRING_SPLIT:简洁高效的分割
基础语法:
SQLSTRING_SPLIT(string, separator [, enable_ordinal])
🛠️ 实战案例1:商品标签分析
SQL-- 创建商品表
CREATE TABLE #products (
product_id INT,
product_name NVARCHAR(100),
tags NVARCHAR(500)
);
INSERT INTO #products VALUES
(1, 'iPhone 15', '电子产品,智能手机,Apple,热销'),
(2, 'MacBook Pro', '电子产品,笔记本电脑,Apple,专业'),
(3, '小米充电宝', '电子产品,数码配件,充电设备,便携');
-- 使用STRING_SPLIT分割标签并统计
SELECT
TRIM(s.value) as tag_name,
COUNT(*) as product_count
FROM #products p
CROSS APPLY STRING_SPLIT(p.tags, ',') AS s
WHERE LEN(TRIM(s.value)) > 0
GROUP BY TRIM(s.value)
ORDER BY product_count DESC;
-- 清理临时表
DROP TABLE #products;

🆕 SQL Server 2022 新特性:启用序号
SQL-- 启用ordinal参数,获取分割后的位置信息
SELECT
value AS tag_name,
ordinal AS position
FROM STRING_SPLIT('电子产品,数码配件,热销商品', ',', 1)
ORDER BY ordinal;

⚠️ 使用注意事项
- 版本要求:STRING_SPLIT需要SQL Server 2016+
- 分隔符限制:分隔符只能是单个字符
- 空值处理:会返回空字符串,需要手动过滤
SQL-- 🚨 处理空值和空格
SELECT TRIM(value) AS clean_value
FROM STRING_SPLIT('a, ,b, ,c', ',')
WHERE LEN(TRIM(value)) > 0; -- 过滤空值
🔄 组合使用:分割后重新聚合
💡 实际应用场景
有时我们需要对字符串进行"清洗":去重、排序、格式化等。
SQL-- 标签去重和排序
DECLARE @messy_tags NVARCHAR(500) = '电子产品,数码,电子产品,配件,数码,热销';
-- 🔥 分割 → 去重 → 排序 → 重新聚合
WITH cleaned_tags AS (
SELECT DISTINCT TRIM(value) AS tag_name
FROM STRING_SPLIT(@messy_tags, ',')
WHERE LEN(TRIM(value)) > 0
)
SELECT STRING_AGG(tag_name, ',') WITHIN GROUP (ORDER BY tag_name) AS clean_tags
FROM cleaned_tags;
-- 结果:'ань,数码,热销,配件'

🎯 高级应用:数据透视
SQL-- 创建员工表
CREATE TABLE #employees (
employee_id INT,
employee_name NVARCHAR(50)
);
-- 创建员工技能表
CREATE TABLE #employee_skills (
employee_id INT,
skill_name NVARCHAR(50),
skill_level INT -- 1-5分,4分及以上为专家级
);
-- 插入员工数据
INSERT INTO #employees VALUES
(1, '张三'),
(2, '李四'),
(3, '王五');
-- 插入技能数据
INSERT INTO #employee_skills VALUES
(1, 'Java', 5), -- 张三:专家级
(1, 'Python', 4), -- 张三:专家级
(1, 'JavaScript', 3), -- 张三:学习中
(2, 'C#', 4), -- 李四:专家级
(2, 'SQL', 5), -- 李四:专家级
(2, 'React', 2), -- 李四:学习中
(3, 'Python', 3), -- 王五:学习中
(3, 'Vue', 2); -- 王五:学习中
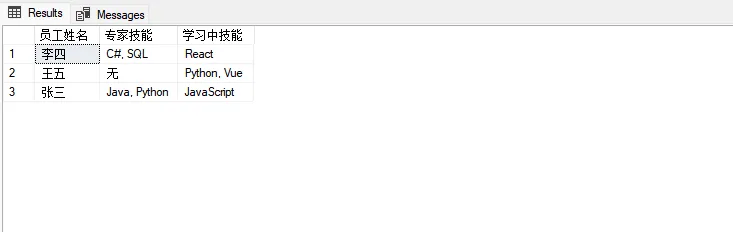
SQL-- 将行数据转换为列数据展示
WITH skill_pivot AS (
SELECT
employee_name,
STRING_AGG(
CASE WHEN skill_level >= 4 THEN skill_name END,
', '
) AS expert_skills,
STRING_AGG(
CASE WHEN skill_level < 4 THEN skill_name END,
', '
) AS learning_skills
FROM #employees e
JOIN #employee_skills s ON e.employee_id = s.employee_id
GROUP BY e.employee_id, e.employee_name
)
SELECT
employee_name AS 员工姓名,
ISNULL(expert_skills, '无') AS 专家技能,
ISNULL(learning_skills, '无') AS 学习中技能
FROM skill_pivot
ORDER BY employee_name;
🎯 总结核心要点
通过本文的学习,我们掌握了SQL Server中两个强大的字符串处理函数:
- STRING_AGG:让多行数据聚合变得优雅高效,告别复杂的FOR XML PATH
- STRING_SPLIT:轻松实现字符串分割,为数据分析提供更多可能性
- 组合应用:两个函数的结合使用,能解决更复杂的数据处理场景
这些函数不仅提升了代码的可读性,更重要的是显著提高了开发效率和查询性能。在实际项目中,它们已经成为我处理字符串数据的首选工具。
💬 互动时间
- 你在项目中还遇到过哪些棘手的字符串处理场景?
- 使用这两个函数时,你踩过哪些坑?
欢迎在评论区分享你的经验和问题,让我们一起探讨更多SQL Server的实用技巧!
觉得这篇文章有用吗?请转发给更多需要的同行,让我们一起提升SQL技能! 🚀
关注我,获取更多数据库实战干货!
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录