SQLite 是一个轻量级的关系型数据库管理系统,广泛应用于许多应用程序中。它的内存数据库功能允许在内存中运行数据库,这对于需要快速访问和处理数据的场景非常有用。本文将详细介绍如何在 C# 中使用 SQLite 创建和操作内存数据库,并通过示例进行讲解。
什么是 SQLite 内存数据库?
SQLite 内存数据库与常规 SQLite 数据库的主要区别在于它们存储数据的位置。内存数据库在 RAM 中创建,数据存取速度快。而常规数据库则存储在磁盘上,读写速度较慢。内存数据库的创建方式为 :memory:。
使用 C# 操作 SQLite 内存数据库
1. 准备工作
首先,确保你的 C# 项目中已经安装了 System.Data.SQLite 库。如果还没有安装,可以通过 NuGet 包管理器运行以下命令:
BashInstall-Package System.Data.SQLite
【导读】数据安全是应用开发的重中之重,一套可靠的备份恢复机制是确保数据安全的基础保障。本文详细讲解如何使用C#开发SQLite数据库备份与恢复服务,提供完整代码示例与最佳实践,助您构建更稳固的应用程序。
为什么需要SQLite备份恢复服务?
在开发使用SQLite的应用时,无论是桌面应用、小型Web服务还是移动应用,数据库备份与恢复功能都至关重要:
- 防范数据丢失风险:系统崩溃、误操作或硬件故障时恢复数据
- 支持系统迁移部署:轻松将数据库迁移到新环境
- 实现版本回滚能力:出现问题时快速恢复到稳定版本
- 提升应用可靠性:建立用户对应用的信任
- 满足合规性要求:某些行业要求定期备份数据
核心功能设计
一个完善的SQLite备份恢复服务应包含以下关键功能:
- 定期自动备份:按设定间隔执行自动备份
- 手动备份触发:支持用户随时创建备份点
- 备份文件管理:控制备份数量和占用空间
- 数据库恢复机制:从任意备份点恢复系统
- 日志与异常处理:记录备份恢复过程中的关键事件
在SQL Server中,选择正确的索引类型对于提高查询性能和优化数据库操作至关重要。本文将深入探讨覆盖索引、过滤索引和列存储索引的使用场景,并通过具体的例子和测试数据来说明它们的优势。
覆盖索引 (Covering Index)
覆盖索引是一个非聚集索引,它包含了查询中所有需要的列,因此查询可以直接从索引中获取数据而无需访问表数据。
适用场景
- 查询需要的所有列都包含在索引中。
- 查询频繁执行,且性能需优化。
示例
假设我们有一个销售记录表 SalesRecords:
SQLCREATE TABLE SalesRecords (
SalesRecordID INT PRIMARY KEY,
ProductID INT,
SaleDate DATETIME,
Quantity INT,
TotalAmount MONEY
);
插入测试数据:
SQLDECLARE @i INT = 1;
WHILE @i <= 1000
BEGIN
INSERT INTO SalesRecords (SalesRecordID, ProductID, SaleDate, Quantity, TotalAmount)
VALUES (@i, @i % 100 + 1, DATEADD(day, -(@i % 365), GETDATE()), @i % 10 + 1, @i * 10.00);
SET @i = @i + 1;
END
在SQL Server中,索引是提高查询性能的关键工具。然而,随着时间的推移和数据的变化,索引可能会变得不那么有效,导致查询性能下降。为了确保索引始终处于最佳状态,我们需要定期分析和维护索引。SQL Server提供了一系列动态管理视图(DMVs),可以帮助我们分析索引性能。在本文中,我们将通过一个具体的示例来展示如何使用这些DMVs分析索引性能。
准备测试数据
首先,我们需要创建一个测试表,并插入一些模拟数据。以下是测试表的结构和插入数据的脚本。
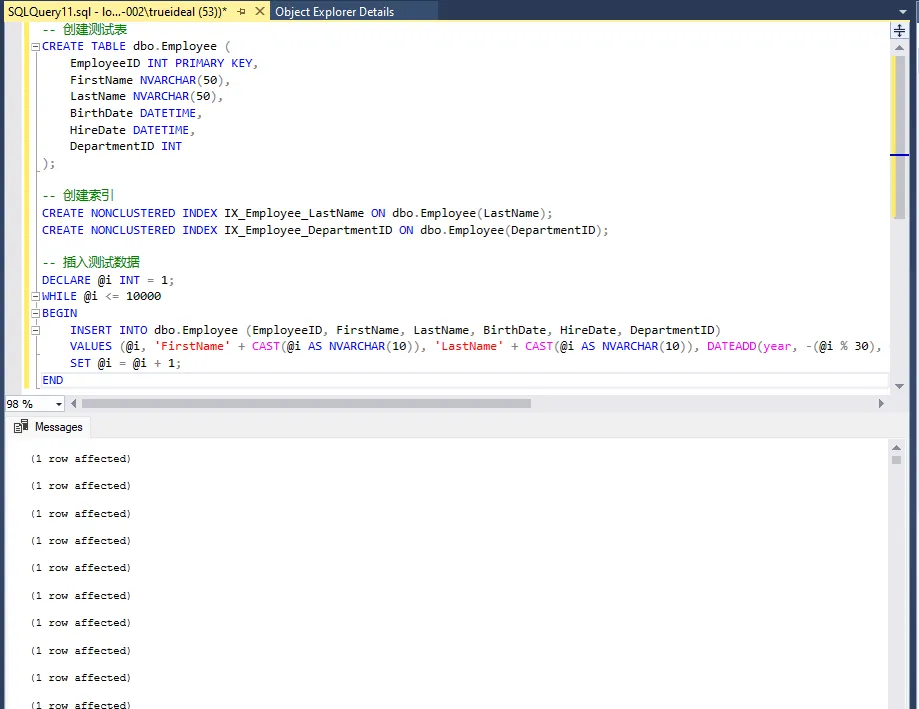
SQL-- 创建测试表
CREATE TABLE dbo.Employee (
EmployeeID INT PRIMARY KEY,
FirstName NVARCHAR(50),
LastName NVARCHAR(50),
BirthDate DATETIME,
HireDate DATETIME,
DepartmentID INT
);
-- 创建索引
CREATE NONCLUSTERED INDEX IX_Employee_LastName ON dbo.Employee(LastName);
CREATE NONCLUSTERED INDEX IX_Employee_DepartmentID ON dbo.Employee(DepartmentID);
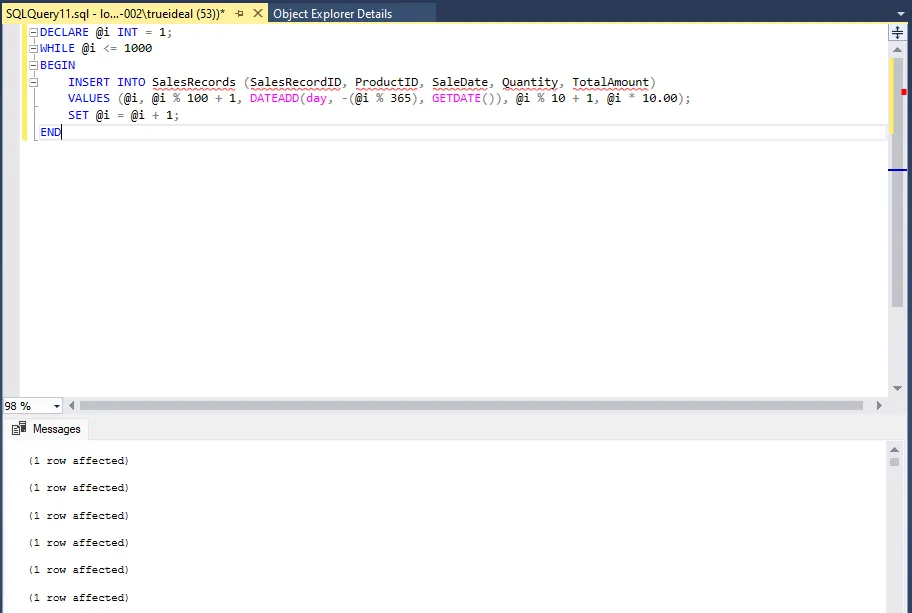
-- 插入测试数据
DECLARE @i INT = 1;
WHILE @i <= 10000
BEGIN
INSERT INTO dbo.Employee (EmployeeID, FirstName, LastName, BirthDate, HireDate, DepartmentID)
VALUES (@i, 'FirstName' + CAST(@i AS NVARCHAR(10)), 'LastName' + CAST(@i AS NVARCHAR(10)), DATEADD(year, -(@i % 30), GETDATE()), DATEADD(year, -(@i % 15), GETDATE()), @i % 10 + 1);
SET @i = @i + 1;
END
数据库索引类似于书籍的目录,可以帮助快速定位所需的数据。随着数据的增加和删除,索引可能会变得碎片化,从而降低查询性能。索引维护是为了优化索引性能,确保数据检索尽可能高效。在SQL Server中,索引维护通常包括索引重建(Rebuild)和索引重组(Reorganize)。下面,我们将通过一个具体的例子来展示如何进行索引维护。
示例场景
假设我们有一个名为Orders的表,存储了客户的订单信息。表的结构如下:
SQLCREATE TABLE Orders (
OrderID INT PRIMARY KEY,
CustomerID INT,
OrderDate DATETIME,
TotalAmount DECIMAL(10, 2)
);
为了提高查询性能,我们在CustomerID列和OrderDate列上创建了非聚集索引。
SQLCREATE NONCLUSTERED INDEX IX_Orders_CustomerID ON Orders(CustomerID);
CREATE NONCLUSTERED INDEX IX_Orders_OrderDate ON Orders(OrderDate);
接下来,我们将插入一些模拟数据来模拟订单表的使用。
SQL-- 插入测试数据
DECLARE @i INT = 1;
WHILE @i <= 10000
BEGIN
INSERT INTO Orders (OrderID, CustomerID, OrderDate, TotalAmount)
VALUES (@i, RAND() * 1000, DATEADD(day, RAND() * 1000, GETDATE()), RAND() * 1000);
SET @i = @i + 1;
END
索引碎片化检查
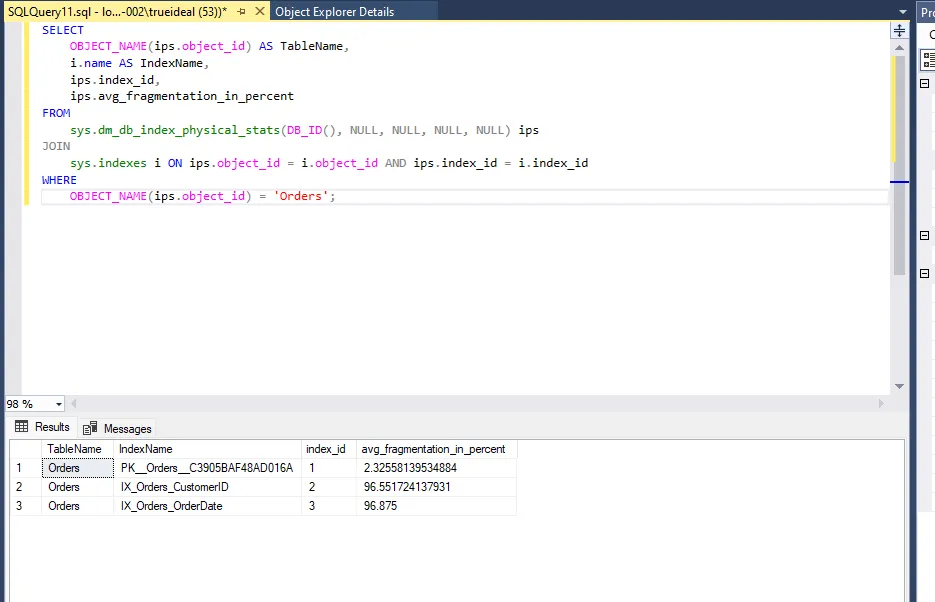
在进行索引维护之前,我们需要检查索引的碎片化程度。可以使用sys.dm_db_index_physical_stats动态管理函数来实现。
SQLSELECT
OBJECT_NAME(ips.object_id) AS TableName,
i.name AS IndexName,
ips.index_id,
ips.avg_fragmentation_in_percent
FROM
sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) ips
JOIN
sys.indexes i ON ips.object_id = i.object_id AND ips.index_id = i.index_id
WHERE
OBJECT_NAME(ips.object_id) = 'Orders';