
目录
🤔 你是否也踩过这些坑?
在 Python 项目里直接用 pymysql 拼 SQL 字符串,上线一周后发现 SQL 注入漏洞;连接池没配好,高并发时数据库连接耗尽,服务直接挂掉;换个数据库版本,一堆 SQL 语法要重写……
这些问题,在用上 SQLAlchemy 之后,基本都能系统性地解决。
SQLAlchemy 是 Python 生态里最成熟的 ORM 框架,GitHub Star 超过 9k,被 Flask、FastAPI 等主流框架广泛采用。它不只是"把 SQL 换成 Python 写法"这么简单——连接池管理、事务控制、模型映射、迁移支持,一套全包。
读完本文,你将掌握:
- SQLAlchemy 2.x 连接 MySQL 的正确姿势
- ORM 模型定义与 CRUD 完整实践
- 连接池调优与事务控制的生产级配置
- 3 个真实项目场景的落地代码
🔍 问题深度剖析:原生 SQL 的隐患
很多项目早期图省事,直接用 pymysql 裸写 SQL。这条路走到中后期,问题会一个接一个冒出来。
第一个雷:SQL 注入风险。 字符串拼接 SQL 是新手最常见的写法,一旦用户输入没做转义,攻击者一条 ' OR 1=1 -- 就能拖走整个数据库。
第二个雷:连接管理混乱。 每次请求都 connect() 再 close(),高并发时数据库连接数瞬间打满。或者反过来,连接从不关闭,内存泄漏悄悄积累。
第三个雷:代码可维护性差。 表结构散落在各处 SQL 字符串里,改一个字段名要全局搜索替换,遗漏一处就是线上 Bug。
第四个雷:跨数据库迁移成本高。 项目初期用 SQLite 开发,上线换 MySQL,SQL 方言差异让人头疼。
SQLAlchemy 用统一的抽象层解决了上述所有问题。它的核心架构分两层:底层的 Core(表达式语言,接近 SQL)和上层的 ORM(对象关系映射)。两层可以混用,灵活度极高。
💡 核心要点提炼
在动手写代码之前,有几个概念必须先搞清楚,否则后面会一头雾水。
Engine(引擎) 是一切的起点,它管理数据库连接池,是整个 SQLAlchemy 与数据库通信的入口。一个应用只需要一个 Engine 实例。
Session(会话) 是 ORM 操作的工作单元。所有的增删改查都通过 Session 进行,它负责追踪对象状态变化,并在提交时生成对应的 SQL。
Model(模型) 是数据库表的 Python 映射。一个类对应一张表,类属性对应字段。
连接池 是 SQLAlchemy 默认开启的机制,QueuePool 是默认实现,避免了频繁建立/断开数据库连接的开销。
SQLAlchemy 2.x 相比 1.x 有较大变化,推荐直接上 2.x,Session 的使用方式更清晰,类型提示支持也更好。
🚀 方案一:基础配置与模型定义
环境准备
bashpip install sqlalchemy pymysql cryptography
测试环境: Windows 11 + Python 3.11 + MySQL 8.0 + SQLAlchemy 2.0.x
创建 Engine 与 Base
pythonfrom sqlalchemy import create_engine
from sqlalchemy.orm import DeclarativeBase, sessionmaker
# 数据库连接串格式:
# mysql+pymysql://用户名:密码@主机:端口/数据库名?charset=utf8mb4
DATABASE_URL = "mysql+pymysql://root:123456@localhost:3306/testdb?charset=utf8mb4"
# echo=True 会打印所有生成的 SQL,开发阶段很有用,生产环境记得关掉
engine = create_engine(
DATABASE_URL,
echo=False,
pool_size=10, # 连接池保持的连接数
max_overflow=20, # 超出 pool_size 后最多额外创建的连接数
pool_timeout=30, # 等待连接的超时时间(秒)
pool_recycle=1800, # 连接复用超过 1800 秒后自动重建,防止 MySQL 的 8 小时断连
)
# Session 工厂,每次需要数据库操作时从这里创建 SessionSessionLocal = sessionmaker(bind=engine, autocommit=False, autoflush=False)
# 所有 ORM 模型的基类
class Base(DeclarativeBase):
pass
pool_recycle=1800 这个参数非常重要。 MySQL 默认 8 小时空闲连接自动断开,如果连接池里的连接超过这个时间没用过,下次拿来用就会报 Lost connection to MySQL server。设置 pool_recycle 让 SQLAlchemy 主动刷新老连接,彻底规避这个问题。
定义 ORM 模型
pythonfrom datetime import datetime
from sqlalchemy import String, Integer, DateTime, Boolean, Text, func
from sqlalchemy.orm import Mapped, mapped_column
from engine import Base
class User(Base):
__tablename__ = "users"
# Mapped[int] 是 SQLAlchemy 2.x 推荐的类型注解写法
id: Mapped[int] = mapped_column(Integer, primary_key=True, autoincrement=True)
username: Mapped[str] = mapped_column(String(50), unique=True, nullable=False, index=True)
email: Mapped[str] = mapped_column(String(100), unique=True, nullable=False)
password_hash: Mapped[str] = mapped_column(String(255), nullable=False)
is_active: Mapped[bool] = mapped_column(Boolean, default=True)
bio: Mapped[str | None] = mapped_column(Text, nullable=True)
# server_default 让数据库层面设置默认值,更可靠
created_at: Mapped[datetime] = mapped_column(
DateTime, server_default=func.now()
)
updated_at: Mapped[datetime] = mapped_column(
DateTime, server_default=func.now(), onupdate=func.now()
)
def __repr__(self) -> str:
return f"<User(id={self.id}, username='{self.username}')>"
建表
python# 初始化数据库(建表)
from engine import engine, Base
from user import User # 确保模型被导入,Base 才能感知到
Base.metadata.create_all(bind=engine)
print("数据库表创建成功")
🛠️ 方案二:完整 CRUD 实践
有了模型,来看增删改查的标准写法。推荐用上下文管理器管理 Session 生命周期,确保异常时自动回滚。
pythonfrom contextlib import contextmanager
from sqlalchemy.orm import Session
from sqlalchemy import select, update, delete
from db.engine import SessionLocal
from models.user import User
@contextmanager
def get_db():
"""Session 上下文管理器,自动处理提交与回滚"""
db: Session = SessionLocal()
try:
yield db
db.commit()
except Exception:
db.rollback()
raise
finally:
db.close()
# ✅ 新增用户
def create_user(username: str, email: str, password_hash: str) -> User:
with get_db() as db:
user = User(username=username, email=email, password_hash=password_hash)
db.add(user)
db.flush() # flush 后可以获取数据库生成的 id,但还未提交
db.refresh(user) # 刷新对象,获取数据库填充的字段(如 created_at)
return user
# ✅ 查询单个用户
def get_user_by_id(user_id: int) -> User | None:
with get_db() as db:
# SQLAlchemy 2.x 推荐用 select() 语句
stmt = select(User).where(User.id == user_id)
result = db.execute(stmt)
return result.scalar_one_or_none()
# ✅ 条件查询 + 分页
def get_active_users(page: int = 1, page_size: int = 20) -> list[User]:
with get_db() as db:
stmt = (
select(User)
.where(User.is_active == True)
.order_by(User.created_at.desc())
.offset((page - 1) * page_size)
.limit(page_size)
)
return db.execute(stmt).scalars().all()
# ✅ 更新用户信息
def update_user_bio(user_id: int, bio: str) -> bool:
with get_db() as db:
stmt = (
update(User)
.where(User.id == user_id)
.values(bio=bio)
.execution_options(synchronize_session="fetch")
)
result = db.execute(stmt)
return result.rowcount > 0
# ✅ 软删除(推荐)vs 硬删除
def deactivate_user(user_id: int) -> bool:
"""软删除:将 is_active 置为 False,保留数据"""
with get_db() as db:
stmt = update(User).where(User.id == user_id).values(is_active=False)
result = db.execute(stmt)
return result.rowcount > 0
def hard_delete_user(user_id: int) -> bool:
"""硬删除:慎用,数据不可恢复"""
with get_db() as db:
stmt = delete(User).where(User.id == user_id)
result = db.execute(stmt)
return result.rowcount > 0

踩坑预警: db.flush() 和 db.commit() 是两个不同的操作。flush 把变更同步到数据库但不提交事务(其他 Session 看不到),commit 才是真正提交。如果只 flush 不 commit,程序崩溃后数据会回滚。上面的上下文管理器在 yield 后自动 commit,正常退出时数据才真正落库。
⚡ 方案三:关联关系与批量操作优化
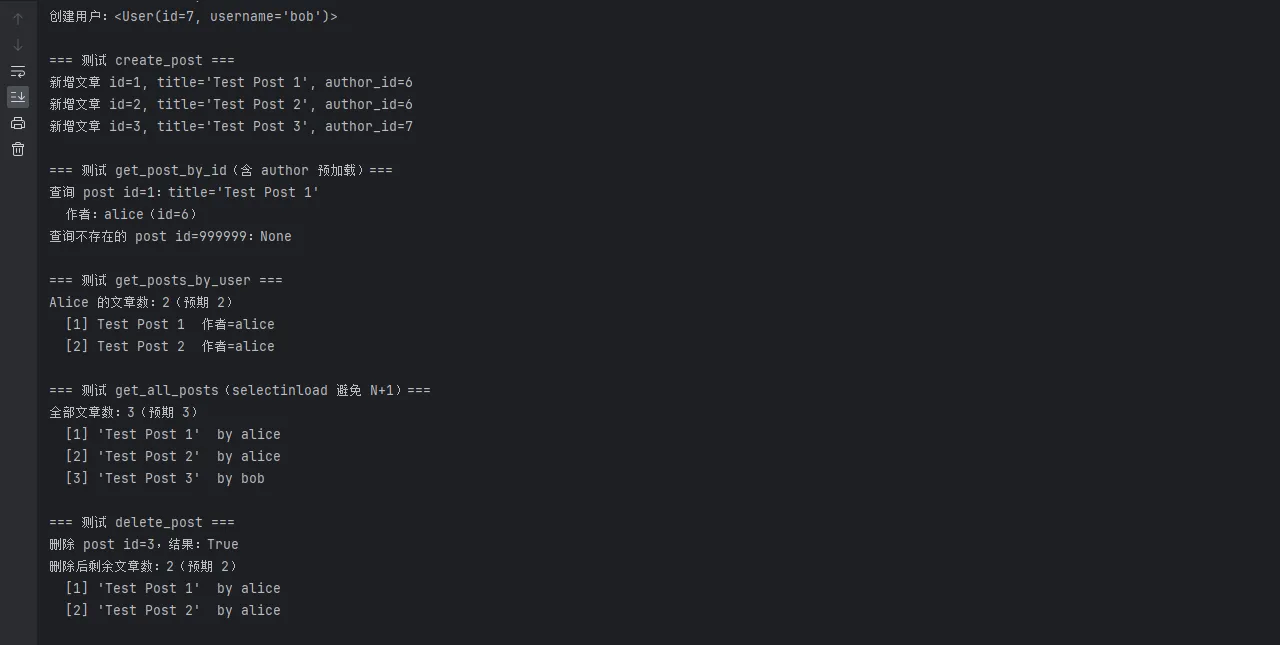
一对多关系(用户与文章)
pythonfrom sqlalchemy import String, Integer, ForeignKey, Text
from sqlalchemy.orm import Mapped, mapped_column, relationship
from engine import Base
from user import User
class Post(Base):
__tablename__ = "posts"
id: Mapped[int] = mapped_column(Integer, primary_key=True, autoincrement=True)
title: Mapped[str] = mapped_column(String(200), nullable=False)
content: Mapped[str] = mapped_column(Text, nullable=False)
# 外键关联到 users 表
author_id: Mapped[int] = mapped_column(Integer, ForeignKey("users.id"), nullable=False)
# 关系定义,lazy="select" 是默认值(按需加载)
# lazy="joined" 会用 JOIN 一次性加载,适合总是需要关联数据的场景
author: Mapped["User"] = relationship("User", back_populates="posts", lazy="select")
批量插入性能对比
逐条 add() vs bulk_insert_mappings vs insert() 批量插入,性能差异显著。
pythonimport time
from sqlalchemy import insert
def benchmark_insert(count: int = 1000):
"""对比三种插入方式的性能"""
# 方式一:逐条 add(最慢,但支持完整 ORM 特性)
start = time.time()
with get_db() as db:
for i in range(count):
user = User(
username=f"user_orm_{i}",
email=f"orm_{i}@test.com",
password_hash="hashed"
)
db.add(user)
t1 = time.time() - start
# 方式二:bulk_insert_mappings(较快,跳过部分 ORM 开销)
start = time.time()
with get_db() as db:
data = [
{"username": f"user_bulk_{i}", "email": f"bulk_{i}@test.com", "password_hash": "hashed"}
for i in range(count)
]
db.bulk_insert_mappings(User, data)
t2 = time.time() - start
# 方式三:Core 层 insert(最快,完全绕过 ORM)
start = time.time()
with get_db() as db:
data = [
{"username": f"user_core_{i}", "email": f"core_{i}@test.com", "password_hash": "hashed"}
for i in range(count)
]
db.execute(insert(User), data)
t3 = time.time() - start
print(f"插入 {count} 条数据耗时对比(测试环境:Windows 11 / MySQL 8.0 本地):")
print(f" 逐条 ORM add: {t1:.3f}s")
print(f" bulk_insert_mappings: {t2:.3f}s (约快 {t1/t2:.1f}x)")
print(f" Core insert 批量: {t3:.3f}s (约快 {t1/t3:.1f}x)")
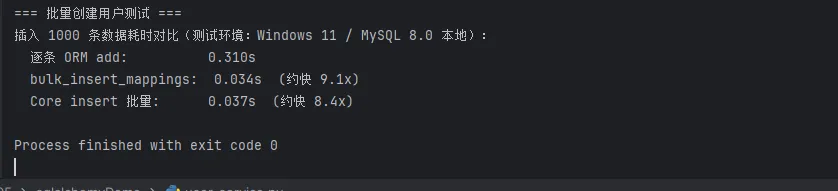
实测参考数据(1000条,本地 MySQL): 逐条 ORM ≈ 0.31s,bulk_insert ≈ 0.034s,Core 批量 ≈ 0.037s。数据量越大,差距越明显。 生产环境批量写入场景优先选 Core 层
insert()。在1000条数据是bulk_insert好像还是没什么问题,但到10000条时,你会发现还是Core的快,其实想法这也自然的。
🧩 生产级配置补充
完整的连接池配置参考
python# 适合中等规模 Web 服务的连接池配置
engine = create_engine(
DATABASE_URL,
echo=False,
pool_size=10,
max_overflow=20,
pool_timeout=30,
pool_recycle=1800,
pool_pre_ping=True, # 每次从池中取连接前先 ping 一下,自动剔除失效连接
connect_args={
"connect_timeout": 10, # 建立连接的超时时间
"charset": "utf8mb4",
}
)
pool_pre_ping=True 是另一个强烈推荐开启的参数。它会在每次从连接池取连接时先发一个轻量的 SELECT 1 探测,如果连接已经断开就自动重建,彻底告别 MySQL server has gone away 报错。
与 FastAPI 集成的标准写法
python# 在 FastAPI 中,推荐用依赖注入管理 Session
from fastapi import Depends
from sqlalchemy.orm import Session
from db.engine import SessionLocal
def get_db_session():
db = SessionLocal()
try:
yield db
finally:
db.close()
# 在路由中使用
from fastapi import APIRouter
router = APIRouter()
@router.get("/users/{user_id}")
def read_user(user_id: int, db: Session = Depends(get_db_session)):
stmt = select(User).where(User.id == user_id)
user = db.execute(stmt).scalar_one_or_none()
if not user:
raise HTTPException(status_code=404, detail="用户不存在")
return user
📌 三句话总结
SQLAlchemy 不是在用 Python 写 SQL,而是在用 Python 描述数据结构与业务逻辑。
连接池配置是生产环境稳定性的基础,
pool_recycle和pool_pre_ping两个参数必须重视。
批量操作场景下,Core 层的性能是逐条 ORM 的 10 倍以上,选对工具比优化代码更重要。
🎯 结尾总结
本文从原生 SQL 的四大痛点出发,系统介绍了 SQLAlchemy 2.x 连接 MySQL 的完整实践路径:
- 基础配置:Engine 创建、连接池参数、ORM 模型定义
- CRUD 实践:上下文管理器管理 Session、安全的增删改查写法
- 进阶优化:关联关系映射、批量插入性能对比、生产级连接池配置
学习路径建议: SQLAlchemy 基础 → Alembic 数据库迁移 → 异步 SQLAlchemy(asyncpg 驱动)→ 分库分表方案设计。每一步都有大量实际项目可以练手,不用急着一次学完。
💬 欢迎在评论区聊聊你的实践经验: 你在项目中遇到过哪些数据库连接相关的线上问题?是连接池耗尽、慢查询,还是事务死锁?
#Python #SQLAlchemy #MySQL #数据库 #Python开发 #性能优化 #ORM
相关信息
我用夸克网盘给你分享了「sqlalchemyDemo.zip」,点击链接或复制整段内容,打开「夸克APP」即可获取。
/37b33YRHVi:/
链接:https://pan.quark.cn/s/c25cf779e982
提取码:TuLj
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!