
目录
🏭 从一台老旧设备说起
车间里有台注塑机,跑了八年了。老板问我:能不能实时看到它的温度、压力、转速?数据还得存下来,方便以后查问题。
预算?没有。买SCADA?太贵。
就这样,我用Python捣鼓出了一套方案——Tkinter做界面,Modbus采PLC数据,SQLite存历史记录。整个项目从零到上线,花了三天。踩了不少坑,但最终跑得挺稳。
这篇文章,我把完整的思路和代码都摆出来,你照着做,基本能直接用。
🧩 整体架构,先想清楚再动手
很多人一上来就写代码,写着写着发现逻辑乱成一锅粥。我吃过这个亏。
这套系统说白了就三件事:采数据、存数据、显数据。对应三个模块:
plc_reader.py— 负责跟PLC通信,拿原始数据db_manager.py— 负责把数据塞进SQLite,查询也在这里main_app.py— Tkinter主界面,把数据展示出来,还要触发定时采集
三个模块各司其职,互相不乱插手。这种结构,后期改起来不会崩。
🔌 第一步:跟PLC建立连接
工业现场最常见的协议是Modbus TCP。Python有个库叫pymodbus,用起来很顺手。
bashpip install pymodbus
来看PLC读取模块的核心代码:
pythonfrom pymodbus.client import ModbusTcpClient
from pymodbus.exceptions import ModbusException
import logging
logger = logging.getLogger(__name__)
class PLCReader:
def __init__(self, host: str, port: int = 502):
self.host = host
self.port = port
self.client = ModbusTcpClient(host=host, port=port, timeout=3)
self._connected = False
def connect(self) -> bool:
"""尝试连接PLC,返回是否成功"""
try:
self._connected = self.client.connect()
if self._connected:
logger.info(f"已连接PLC: {self.host}:{self.port}")
return self._connected
except Exception as e:
logger.error(f"连接失败: {e}")
return False
def read_holding_registers(self, address: int, count: int) -> list | None:
"""
读取保持寄存器
address: 起始地址
count: 读取数量
"""
if not self._connected:
logger.warning("PLC未连接,尝试重连...")
if not self.connect():
return None
try:
result = self.client.read_holding_registers(address, count)
if result.isError():
logger.error(f"读取寄存器失败,地址: {address}")
return None
return result.registers
except ModbusException as e:
logger.error(f"Modbus异常: {e}")
self._connected = False # 标记断线,下次自动重连
return None
def parse_data(self, raw_registers: list) -> dict:
"""
把原始寄存器值转换成有意义的工程量
具体换算比例要看PLC程序里的定义
"""
if not raw_registers or len(raw_registers) < 4:
return {}
return {
"temperature": raw_registers[0] / 10.0, # 假设精度0.1°C
"pressure": raw_registers[1] / 100.0, # 单位 MPa
"speed": raw_registers[2], # 转速 RPM
"status_code": raw_registers[3] # 设备状态码
}
def close(self):
self.client.close()
self._connected = False
有几个细节值得注意。断线重连这块,我没用复杂的心跳机制,就是读取失败时把_connected置为False,下次读取前自动尝试重连。简单粗暴,但在工厂环境里够用了。
寄存器地址和换算比例,一定要跟做PLC程序的工程师确认,这个没有通用答案,每个项目都不一样。
🗄️ 第二步:SQLite数据库设计
SQLite不需要安装,Python自带,零配置,对于这种单机采集系统来说是最合适的选择。
pythonimport sqlite3
import threading
from datetime import datetime
from contextlib import contextmanager
class DBManager:
def __init__(self, db_path: str = "plc_data.db"):
self.db_path = db_path
self._lock = threading.Lock() # 多线程写入时必须加锁
self._init_db()
def _init_db(self):
"""建表,如果表已存在就跳过"""
with self._get_conn() as conn:
conn.execute("""
CREATE TABLE IF NOT EXISTS plc_records (
id INTEGER PRIMARY KEY AUTOINCREMENT,
timestamp TEXT NOT NULL,
temperature REAL,
pressure REAL,
speed INTEGER,
status_code INTEGER,
device_id TEXT DEFAULT 'PLC_01'
)
""")
# 给timestamp建索引,查历史数据时快很多
conn.execute("""
CREATE INDEX IF NOT EXISTS idx_timestamp
ON plc_records (timestamp)
""")
@contextmanager
def _get_conn(self):
"""用上下文管理器处理连接,自动提交和关闭"""
conn = sqlite3.connect(self.db_path)
conn.row_factory = sqlite3.Row # 让查询结果支持按列名访问
try:
yield conn
conn.commit()
except Exception:
conn.rollback()
raise
finally:
conn.close()
def insert_record(self, data: dict) -> bool:
"""插入一条采集记录"""
with self._lock:
try:
with self._get_conn() as conn:
conn.execute("""
INSERT INTO plc_records
(timestamp, temperature, pressure, speed, status_code)
VALUES (?, ?, ?, ?, ?)
""", (
datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
data.get("temperature"),
data.get("pressure"),
data.get("speed"),
data.get("status_code")
))
return True
except sqlite3.Error as e:
print(f"数据库写入失败: {e}")
return False
def query_recent(self, limit: int = 100) -> list:
"""查最近N条记录"""
with self._get_conn() as conn:
cursor = conn.execute("""
SELECT * FROM plc_records
ORDER BY id DESC
LIMIT ?
""", (limit,))
return [dict(row) for row in cursor.fetchall()]
def query_by_timerange(self, start: str, end: str) -> list:
"""按时间段查询,start/end格式: '2025-01-01 00:00:00'"""
with self._get_conn() as conn:
cursor = conn.execute("""
SELECT * FROM plc_records
WHERE timestamp BETWEEN ? AND ?
ORDER BY timestamp ASC
""", (start, end))
return [dict(row) for row in cursor.fetchall()]
def get_stats(self) -> dict:
"""统计总记录数和最新一条的时间"""
with self._get_conn() as conn:
row = conn.execute("""
SELECT COUNT(*) as total,
MAX(timestamp) as last_time
FROM plc_records
""").fetchone()
return dict(row) if row else {}
这里有个坑我要专门说一下:SQLite在多线程环境下写入必须加锁。Tkinter的定时器回调和主线程是同一个线程,但如果你后面想加后台线程,不加锁迟早出问题。threading.Lock()这一行,别省。
🖥️ 第三步:Tkinter界面,把数据立起来
界面这块,我尽量做得实用,不花哨。一个状态栏显示连接情况,一块实时数据区显示当前值,下面是历史记录表格。
pythonimport tkinter as tk
from tkinter import ttk, messagebox
import threading
from plc_reader import PLCReader
from db_manager import DBManager
class PLCMonitorApp:
def __init__(self, root: tk.Tk):
self.root = root
self.root.title("PLC实时监控系统 v1.0")
self.root.geometry("900x620")
self.root.resizable(True, True)
# 初始化核心模块
self.plc = PLCReader(host="192.168.1.100", port=502)
self.db = DBManager(db_path="plc_data.db")
self._collecting = False
self._collect_interval = 2000 # 毫秒,即2秒采一次
self._build_ui()
self._refresh_table() # 启动时加载一次历史数据
# ── 界面构建 ──────────────────────────────────────────
def _build_ui(self):
# 顶部工具栏
toolbar = tk.Frame(self.root, bg="#2c3e50", height=50)
toolbar.pack(fill=tk.X)
toolbar.pack_propagate(False)
tk.Label(toolbar, text="🏭 PLC数据监控",
bg="#2c3e50", fg="white",
font=("微软雅黑", 14, "bold")).pack(side=tk.LEFT, padx=15)
self.btn_start = tk.Button(
toolbar, text="▶ 开始采集",
bg="#27ae60", fg="white", relief=tk.FLAT,
padx=12, font=("微软雅黑", 10),
command=self._toggle_collection
)
self.btn_start.pack(side=tk.RIGHT, padx=10, pady=8)
# 状态栏
self.status_var = tk.StringVar(value="● 未连接")
status_bar = tk.Label(
self.root, textvariable=self.status_var,
bg="#ecf0f1", fg="#7f8c8d",
anchor=tk.W, padx=10, font=("微软雅黑", 9)
)
status_bar.pack(fill=tk.X)
# 实时数据卡片区
card_frame = tk.Frame(self.root, bg="#f5f6fa", pady=10)
card_frame.pack(fill=tk.X, padx=15)
self.data_vars = {}
fields = [
("温度", "temperature", "°C", "#e74c3c"),
("压力", "pressure", "MPa", "#3498db"),
("转速", "speed", "RPM", "#2ecc71"),
("状态", "status_code", "", "#9b59b6"),
]
for label, key, unit, color in fields:
self._make_card(card_frame, label, key, unit, color)
# 历史记录表格
table_frame = tk.LabelFrame(
self.root, text=" 历史记录 ",
font=("微软雅黑", 10), padx=8, pady=8
)
table_frame.pack(fill=tk.BOTH, expand=True, padx=15, pady=(0, 10))
cols = ("时间", "温度(°C)", "压力(MPa)", "转速(RPM)", "状态码")
self.tree = ttk.Treeview(table_frame, columns=cols,
show="headings", height=12)
for col in cols:
self.tree.heading(col, text=col)
self.tree.column(col, width=150, anchor=tk.CENTER)
scrollbar = ttk.Scrollbar(table_frame, orient=tk.VERTICAL,
command=self.tree.yview)
self.tree.configure(yscrollcommand=scrollbar.set)
self.tree.pack(side=tk.LEFT, fill=tk.BOTH, expand=True)
scrollbar.pack(side=tk.RIGHT, fill=tk.Y)
def _make_card(self, parent, label, key, unit, color):
"""生成一个数据展示卡片"""
card = tk.Frame(parent, bg="white", relief=tk.RAISED,
bd=1, width=180, height=80)
card.pack(side=tk.LEFT, padx=8, pady=4)
card.pack_propagate(False)
tk.Label(card, text=label, bg="white",
fg="#7f8c8d", font=("微软雅黑", 9)).pack(pady=(8, 0))
var = tk.StringVar(value="--")
self.data_vars[key] = var
tk.Label(card, textvariable=var, bg="white",
fg=color, font=("微软雅黑", 18, "bold")).pack()
tk.Label(card, text=unit, bg="white",
fg="#bdc3c7", font=("微软雅黑", 8)).pack()
# ── 采集逻辑 ──────────────────────────────────────────
def _toggle_collection(self):
if not self._collecting:
self._start_collection()
else:
self._stop_collection()
def _start_collection(self):
"""连接PLC,启动定时采集"""
if not self.plc.connect():
messagebox.showerror("连接失败",
"无法连接到PLC,请检查IP地址和网络。")
return
self._collecting = True
self.btn_start.config(text="⏹ 停止采集", bg="#e74c3c")
self.status_var.set("● 采集中...")
self._do_collect() # 立即采一次,别等第一个interval
def _stop_collection(self):
self._collecting = False
self.plc.close()
self.btn_start.config(text="▶ 开始采集", bg="#27ae60")
self.status_var.set("● 已停止")
def _do_collect(self):
"""实际的采集动作,在后台线程执行,避免卡界面"""
if not self._collecting:
return
def worker():
raw = self.plc.read_holding_registers(address=0, count=4)
if raw is None:
self.root.after(0, lambda: self.status_var.set(
"⚠ 读取失败,等待重试..."))
return
data = self.plc.parse_data(raw)
self.db.insert_record(data)
# 更新UI必须回到主线程
self.root.after(0, lambda: self._update_ui(data))
threading.Thread(target=worker, daemon=True).start()
# 安排下一次采集
self.root.after(self._collect_interval, self._do_collect)
def _update_ui(self, data: dict):
"""更新实时数据卡片和表格"""
self.data_vars["temperature"].set(
f"{data.get('temperature', '--'):.1f}")
self.data_vars["pressure"].set(
f"{data.get('pressure', '--'):.2f}")
self.data_vars["speed"].set(str(data.get("speed", "--")))
self.data_vars["status_code"].set(str(data.get("status_code", "--")))
self.status_var.set(
f"● 采集中 | 最新: {data.get('temperature')}°C "
f"{data.get('pressure')}MPa {data.get('speed')}RPM"
)
self._refresh_table()
def _refresh_table(self):
"""刷新历史记录表格,取最近50条"""
for row in self.tree.get_children():
self.tree.delete(row)
records = self.db.query_recent(limit=50)
for rec in records:
self.tree.insert("", tk.END, values=(
rec["timestamp"],
rec["temperature"],
rec["pressure"],
rec["speed"],
rec["status_code"]
))
if __name__ == "__main__":
root = tk.Tk()
app = PLCMonitorApp(root)
root.mainloop()
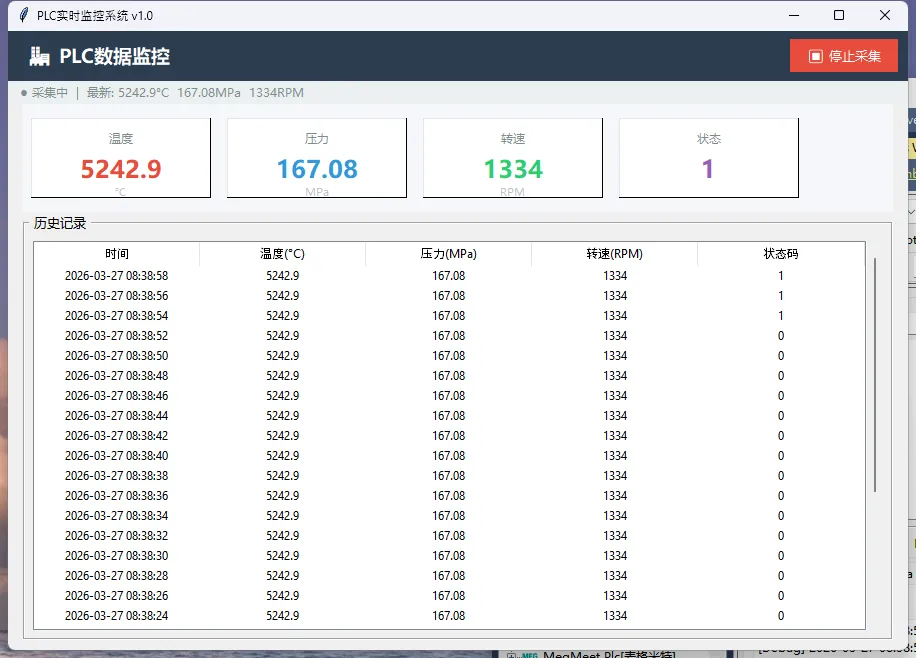
⚠️ 那些差点让我崩溃的坑
坑一:Tkinter不是线程安全的。 在子线程里直接操作Label.config(),有时候能跑,有时候直接崩。解决方案就是root.after(0, callback),把UI更新操作扔回主线程队列。这是铁律,不能省。
坑二:PLC断线没有异常,只有超时。 Modbus TCP断线不会立刻抛异常,而是等到超时才报错。所以timeout=3这个参数要设合理,太长了界面会假死,太短了正常通信也会误判断线。我在实际项目里设的是3秒,基本够用。
坑三:SQLite文件被占用。 有次我在程序还跑着的时候,用DB Browser for SQLite打开数据库文件,结果程序写入报错。这是SQLite的文件锁机制,正常现象。用WAL模式可以缓解这个问题:
python# 在_init_db方法里加上这行
conn.execute("PRAGMA journal_mode=WAL")
开了WAL模式,读写可以并发,外部工具查数据的时候程序还能继续写入,互不干扰。
坑四:长时间运行内存慢慢涨。 这个问题藏得很深。根源是_refresh_table每次都把Treeview里的数据全删了再重建。数据量一大,这个操作就很耗内存。解决办法是只在有新数据写入时才刷新,而不是每次采集都刷:
python# 只在insert_record返回True时才调用_refresh_table
if self.db.insert_record(data):
self.root.after(0, lambda: self._update_ui(data))
📦 项目结构和依赖
整个项目的文件结构很干净:
plc_monitor/ ├── main_app.py # 主入口 ├── plc_reader.py # PLC通信 ├── db_manager.py # 数据库操作 ├── plc_data.db # 运行后自动生成 └── requirements.txt
requirements.txt内容:
pymodbus>=3.5.0
就这一个外部依赖。Tkinter和SQLite都是Python标准库自带的,不用额外安装。
🚀 跑起来之前,确认这几件事
一,确认PLC的IP地址和Modbus TCP端口(默认502),改掉代码里PLCReader(host="192.168.1.100")这行。
二,跟PLC工程师确认寄存器地址和数据换算关系,修改parse_data方法里的换算逻辑。
三,如果手头没有真实PLC做测试,可以用pymodbus自带的模拟器:
bashpython -m pymodbus.server --host 127.0.0.1 --port 502
把PLCReader的host改成127.0.0.1,先把界面和数据库逻辑跑通,再接真机。
💬 写在最后
这套方案我在三个不同的工厂项目里用过,稳定运行了大半年没出过大问题。代码量不多,逻辑也不复杂,但每一块都是踩过坑之后的结果。
如果你的场景比这复杂——比如要接多台PLC、要做报警推送、或者要把数据同步到云端——这套架构也能扩展,核心思路是一样的。
欢迎在评论区聊聊你在工控数采项目里遇到的具体问题,说不定大家都踩过同一个坑。
#Python #Tkinter #PLC #工业自动化 #SQLite
相关信息
我用夸克网盘给你分享了「plcsqlite20260502.zip」,点击链接或复制整段内容,打开「夸克APP」即可获取。
/7f6d3YOQcy:/
链接:https://pan.quark.cn/s/581d063148f6
提取码:anLf
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!