
目录
工厂车间里,一台设备每秒吐出20条传感器数据。程序员小李盯着屏幕——界面卡死了。SQLite写入堵塞了Tkinter主线程,整个GUI像中了定身咒。这种场景,做过工业上位机的朋友应该不陌生。
我在做一个产线质检系统的时候,第一版就翻了这个车。数据写入一多,界面就抽风,客户那边直接打电话投诉。后来花了两周时间把架构推倒重来,才算真正搞明白这套组合的正确打开方式。
本文总结的七个实践,不是从文档里抄来的——是真实项目里一个坑一个坑踩出来的。读完之后,你能拿到:防界面卡死的线程模型、批量写入的性能提升方案、数据库连接的正确管理姿势,以及几个可以直接拿去用的代码模板。
🧱 实践一:绝对不要在主线程里写数据库
这是最根本的一条,也是最容易被忽视的一条。
Tkinter的事件循环是单线程的。你在按钮回调里直接conn.execute(),哪怕只是一条INSERT,只要磁盘稍微抖一下,主线程就会卡住,界面就会失去响应。用户一看,以为程序崩了,直接关掉重开——你的数据也没了。
正确做法是把数据库操作完全移到独立线程。 主线程只负责界面,数据线程只负责存储,两者通过队列通信。
pythonimport tkinter as tk
import sqlite3
import threading
import queue
import time
class DataStorageWorker(threading.Thread):
"""专职数据库写入的工作线程"""
def __init__(self, db_path: str, task_queue: queue.Queue):
super().__init__(daemon=True) # 守护线程,主程序退出时自动结束
self.db_path = db_path
self.task_queue = task_queue
self._stop_event = threading.Event()
def run(self):
# 注意:连接必须在本线程内创建,不能跨线程共享
conn = sqlite3.connect(self.db_path)
conn.execute("PRAGMA journal_mode=WAL") # WAL模式,读写互不阻塞
conn.execute("PRAGMA synchronous=NORMAL") # 性能与安全的平衡点
try:
while not self._stop_event.is_set():
try:
task = self.task_queue.get(timeout=0.1)
if task is None: # 毒丸信号,优雅退出
break
conn.execute(
"INSERT INTO sensor_data(device_id, value, ts) VALUES(?,?,?)",
task
)
conn.commit()
self.task_queue.task_done()
except queue.Empty:
continue
finally:
conn.close()
def stop(self):
self.task_queue.put(None) # 发送毒丸
self._stop_event.set()
class IndustrialApp(tk.Tk):
def __init__(self):
super().__init__()
self.title("工业数据采集")
self.db_queue = queue.Queue(maxsize=10000)
# 启动工作线程
self.worker = DataStorageWorker("industrial.db", self.db_queue)
self.worker.start()
self._build_ui()
self.protocol("WM_DELETE_WINDOW", self._on_close)
def _build_ui(self):
btn = tk.Button(self, text="采集数据", command=self._collect)
btn.pack(pady=20)
self.label = tk.Label(self, text="等待采集...")
self.label.pack()
def _collect(self):
# 主线程只是把任务扔进队列,立刻返回,绝不等待
task = ("device_001", 98.6, time.time())
try:
self.db_queue.put_nowait(task)
self.label.config(text=f"已入队: {task[1]}")
except queue.Full:
self.label.config(text="⚠️ 队列满,数据丢弃!请检查写入速度")
def _on_close(self):
self.worker.stop()
self.worker.join(timeout=3)
self.destroy()
踩坑预警:sqlite3.Connection对象不能跨线程使用,这是SQLite的硬限制。很多人在主线程创建连接然后传给子线程,结果报ProgrammingError: SQLite objects created in a thread can only be used in that same thread。记住,连接在哪个线程里用,就在哪个线程里建。
📦 实践二:批量提交,而不是逐条提交
单条数据每次commit(),性能差得离谱。我测过:同样写入10000条记录,逐条提交需要约18秒,批量提交(每500条commit一次)只需要0.4秒。差了将近45倍。
原因很简单——每次commit都是一次磁盘同步操作,代价极高。工业场景里数据密集,这个差距会被无限放大。
pythonclass BatchStorageWorker(threading.Thread):
"""支持批量提交的工作线程"""
BATCH_SIZE = 500 # 每批次写入条数
FLUSH_INTERVAL = 2.0 # 最长等待秒数,防止低频数据长时间不落盘
def run(self):
conn = sqlite3.connect(self.db_path)
conn.execute("PRAGMA journal_mode=WAL")
conn.execute("PRAGMA cache_size=-64000") # 64MB缓存
batch = []
last_flush = time.time()
try:
while not self._stop_event.is_set():
try:
task = self.task_queue.get(timeout=0.05)
if task is None:
break
batch.append(task)
except queue.Empty:
pass
# 两个条件触发提交:够量了,或者等太久了
should_flush = (
len(batch) >= self.BATCH_SIZE or
(batch and time.time() - last_flush > self.FLUSH_INTERVAL)
)
if should_flush:
conn.executemany(
"INSERT INTO sensor_data VALUES(?,?,?)", batch
)
conn.commit()
print(f"[批量写入] {len(batch)} 条")
batch.clear()
last_flush = time.time()
# 退出前把剩余数据冲刷掉,不能丢
if batch:
conn.executemany(
"INSERT INTO sensor_data VALUES(?,?,?)", batch
)
conn.commit()
finally:
conn.close()
这里有个细节值得注意:FLUSH_INTERVAL这个兜底计时器很重要。设备偶尔停产、数据稀疏的时候,如果只靠条数触发,数据可能在内存里趴好几分钟都不落盘。突然断电,全没了。
🔄 实践三:用after()轮询替代跨线程直接更新UI
子线程里能不能直接调label.config(text=...)?技术上能跑,但Tkinter的文档明确说了——这是未定义行为,在某些Windows版本上会直接崩溃。
正确方式是用after()定时器在主线程里轮询结果队列。
pythonclass AppWithUIUpdate(tk.Tk):
def __init__(self):
super().__init__()
self.result_queue = queue.Queue() # 工作线程把结果放这里
self.status_label = tk.Label(self, text="就绪")
self.status_label.pack()
# 每100ms检查一次结果队列
self._poll_results()
def _poll_results(self):
"""在主线程里安全地消费结果"""
try:
while True:
msg = self.result_queue.get_nowait()
self.status_label.config(text=msg)
except queue.Empty:
pass
# 循环调度自己,只要窗口存在就一直跑
self.after(100, self._poll_results)
100毫秒的轮询间隔对人眼来说完全感知不到延迟,但CPU占用几乎为零。这玩意儿比回调、比事件绑定都省心,是我目前最喜欢的线程通信方式。
🗄️ 实践四:表结构设计要为查询提前布局
工业数据的查询模式高度固定:按时间范围查、按设备ID查、按时间倒序取最新N条。如果建表的时候不加索引,等数据量上了百万,每次查询都是全表扫描,慢得让人抓狂。
pythondef init_db(db_path: str):
"""建表 + 开启WAL,只在启动时调用一次"""
conn = sqlite3.connect(db_path)
conn.executescript("""
PRAGMA journal_mode=WAL;
PRAGMA synchronous=NORMAL;
CREATE TABLE IF NOT EXISTS sensor_data (
id INTEGER PRIMARY KEY AUTOINCREMENT,
device_id TEXT NOT NULL,
value REAL NOT NULL,
ts REAL NOT NULL
);
CREATE INDEX IF NOT EXISTS idx_ts
ON sensor_data(ts DESC);
""")
conn.commit()
conn.close()
quality字段是我在项目里加的,很多教程都没提。工业传感器会出坏值——断线、超量程、通信故障,这些数据不能直接删,要标记保留,方便后续故障追溯。
🧹完整代码
pythonimport tkinter as tk
import tkinter.ttk as ttk
import sqlite3
import threading
import queue
import time
import random
# ─────────────────────────────────────────────
# 数据库初始化(在主线程启动前执行,不涉及并发)
# ─────────────────────────────────────────────
def init_db(db_path: str):
"""建表 + 开启WAL,只在启动时调用一次"""
conn = sqlite3.connect(db_path)
conn.executescript("""
PRAGMA journal_mode=WAL;
PRAGMA synchronous=NORMAL;
CREATE TABLE IF NOT EXISTS sensor_data (
id INTEGER PRIMARY KEY AUTOINCREMENT,
device_id TEXT NOT NULL,
value REAL NOT NULL,
ts REAL NOT NULL
);
CREATE INDEX IF NOT EXISTS idx_ts
ON sensor_data(ts DESC);
""")
conn.commit()
conn.close()
# ─────────────────────────────────────────────
# 工作线程:专职数据库写入,永远不跑在主线程里
# ─────────────────────────────────────────────
class DataStorageWorker(threading.Thread):
"""
从 task_queue 取数据写入 SQLite。
结果(成功条数 / 错误信息)放入 result_queue,
由主线程的 after() 轮询消费,安全更新 UI。
"""
def __init__(
self,
db_path: str,
task_queue: queue.Queue,
result_queue: queue.Queue,
):
super().__init__(daemon=True)
self.db_path = db_path
self.task_queue = task_queue
self.result_queue = result_queue
self._stop_event = threading.Event()
def run(self):
# 连接必须在本线程内创建——SQLite 的硬性规定
conn = sqlite3.connect(self.db_path)
conn.execute("PRAGMA journal_mode=WAL")
conn.execute("PRAGMA synchronous=NORMAL")
written = 0 # 累计写入计数,定期汇报给 UI
try:
while not self._stop_event.is_set():
try:
task = self.task_queue.get(timeout=0.1)
if task is None: # 收到毒丸,准备退出
self.task_queue.task_done()
break
conn.execute(
"INSERT INTO sensor_data(device_id, value, ts)"
" VALUES(?, ?, ?)",
task,
)
conn.commit()
self.task_queue.task_done()
written += 1
# 每写 1 条就往结果队列推一次进度
# 实际项目可改成每 N 条推一次,降低通信开销
self.result_queue.put(("ok", written))
except queue.Empty:
continue
except sqlite3.Error as e:
# 写入出错:记录错误,继续跑,不崩线程
self.result_queue.put(("err", str(e)))
finally:
conn.close()
# 通知 UI:线程已安全退出
self.result_queue.put(("done", written))
def stop(self):
self.task_queue.put(None) # 毒丸
self._stop_event.set()
# ─────────────────────────────────────────────
# 主窗口
# ─────────────────────────────────────────────
class IndustrialApp(tk.Tk):
DB_PATH = "industrial.db"
def __init__(self):
super().__init__()
self.title("工业数据采集 — 线程安全示例")
self.resizable(False, False)
# 两条队列:任务下行,结果上行
self.db_queue = queue.Queue(maxsize=10_000)
self.result_queue = queue.Queue()
# 初始化数据库(主线程,启动前做一次)
init_db(self.DB_PATH)
# 启动工作线程
self.worker = DataStorageWorker(
self.DB_PATH, self.db_queue, self.result_queue
)
self.worker.start()
self._build_ui()
# 启动 UI 轮询:每 100ms 检查一次结果队列
self._poll_results()
self.protocol("WM_DELETE_WINDOW", self._on_close)
# ── UI 构建 ──────────────────────────────
def _build_ui(self):
pad = {"padx": 16, "pady": 8}
# 标题
tk.Label(
self, text="🏭 工业传感器数据采集",
font=("微软雅黑", 14, "bold")
).grid(row=0, column=0, columnspan=3, pady=(16, 4))
# 设备 ID 输入
tk.Label(self, text="设备 ID:").grid(row=1, column=0, **pad, sticky="e")
self.device_var = tk.StringVar(value="device_001")
tk.Entry(self, textvariable=self.device_var, width=16).grid(
row=1, column=1, **pad, sticky="w"
)
# 操作按钮
btn_frame = tk.Frame(self)
btn_frame.grid(row=2, column=0, columnspan=3, pady=4)
tk.Button(
btn_frame, text="📥 采集单条",
width=14, command=self._collect_one
).pack(side="left", padx=6)
tk.Button(
btn_frame, text="🚀 压测 500 条",
width=14, command=self._stress_test
).pack(side="left", padx=6)
tk.Button(
btn_frame, text="🔄 查询最新 10 条",
width=16, command=self._query_latest
).pack(side="left", padx=6)
# 状态栏
tk.Label(self, text="状态:").grid(row=3, column=0, **pad, sticky="ne")
self.status_var = tk.StringVar(value="就绪,等待操作…")
tk.Label(
self, textvariable=self.status_var,
width=42, anchor="w", fg="#1a6e1a",
font=("微软雅黑", 9)
).grid(row=3, column=1, columnspan=2, **pad, sticky="w")
# 进度条(压测时展示队列消耗进度)
self.progress = ttk.Progressbar(
self, orient="horizontal", length=340, mode="determinate"
)
self.progress.grid(row=4, column=0, columnspan=3, padx=16, pady=4)
# 队列深度指示
tk.Label(self, text="队列积压:").grid(row=5, column=0, **pad, sticky="e")
self.queue_var = tk.StringVar(value="0 条")
tk.Label(
self, textvariable=self.queue_var,
font=("Consolas", 9), fg="#555"
).grid(row=5, column=1, **pad, sticky="w")
# 累计写入计数
tk.Label(self, text="累计写入:").grid(row=6, column=0, **pad, sticky="e")
self.written_var = tk.StringVar(value="0 条")
tk.Label(
self, textvariable=self.written_var,
font=("Consolas", 9), fg="#555"
).grid(row=6, column=1, **pad, sticky="w")
# 查询结果文本框
tk.Label(self, text="查询结果:").grid(row=7, column=0, **pad, sticky="ne")
self.result_text = tk.Text(
self, width=44, height=10,
font=("Consolas", 9), state="disabled",
bg="#f5f5f5", relief="flat", bd=1
)
self.result_text.grid(
row=7, column=1, columnspan=2, padx=16, pady=8
)
# 错误提示
self.err_var = tk.StringVar(value="")
tk.Label(
self, textvariable=self.err_var,
fg="red", font=("微软雅黑", 9)
).grid(row=8, column=0, columnspan=3, pady=(0, 8))
# ── 用户操作 ─────────────────────────────
def _collect_one(self):
"""采集单条数据:把任务扔进队列,立刻返回,绝不阻塞主线程"""
task = (
self.device_var.get().strip() or "device_001",
round(random.uniform(20.0, 120.0), 2),
time.time(),
)
self._enqueue(task)
def _stress_test(self):
"""
压测:在独立线程里快速生产 500 条任务。
注意:生产动作本身也不能放在主线程——
循环 500 次 put() 虽然很快,但阻塞时仍会卡 UI。
"""
self.status_var.set("🚀 压测中,正在写入 500 条…")
self.progress["value"] = 0
self.progress["maximum"] = 500
self._stress_written = 0 # 压测专用计数
def _produce():
device = self.device_var.get().strip() or "device_001"
for _ in range(500):
task = (device, round(random.uniform(20.0, 120.0), 2), time.time())
try:
self.db_queue.put(task, timeout=2)
except queue.Full:
# 队列满了就放弃这条,实际项目可改成告警或持久化缓冲
pass
time.sleep(0.002) # 模拟 2ms 一条的采集频率(约 500Hz)
threading.Thread(target=_produce, daemon=True).start()
def _enqueue(self, task: tuple):
"""安全入队,队列满时给出提示而不是静默丢弃"""
try:
self.db_queue.put_nowait(task)
self.status_var.set(f"✅ 已入队:{task[0]} 值={task[1]}")
self.err_var.set("")
except queue.Full:
self.err_var.set("⚠️ 队列已满!写入速度跟不上,请降低采集频率。")
def _query_latest(self):
"""
查询操作同样不能在主线程里做——
用独立线程查完再把结果扔回 result_queue。
"""
def _do_query():
try:
conn = sqlite3.connect(self.DB_PATH)
conn.row_factory = sqlite3.Row
rows = conn.execute(
"SELECT device_id, value, ts FROM sensor_data"
" ORDER BY ts DESC LIMIT 10"
).fetchall()
conn.close()
self.result_queue.put(("query", rows))
except sqlite3.Error as e:
self.result_queue.put(("err", f"查询失败:{e}"))
threading.Thread(target=_do_query, daemon=True).start()
self.status_var.set("🔄 查询中…")
# ── 结果队列轮询(在主线程里安全更新 UI)────
def _poll_results(self):
"""
每 100ms 在主线程里消费 result_queue。
这是 Tkinter 跨线程更新 UI 的唯一安全方式。
"""
try:
while True:
msg_type, payload = self.result_queue.get_nowait()
if msg_type == "ok":
# payload = 累计写入条数
self.written_var.set(f"{payload} 条")
# 同步更新压测进度条
if hasattr(self, "_stress_written"):
self._stress_written += 1
self.progress["value"] = self._stress_written
if self._stress_written >= 500:
self.status_var.set("✅ 压测完成,500 条已全部写入")
elif msg_type == "err":
self.err_var.set(f"❌ 写入错误:{payload}")
elif msg_type == "done":
self.status_var.set(f"🔒 工作线程已退出,共写入 {payload} 条")
elif msg_type == "query":
self._render_query_result(payload)
self.status_var.set("✅ 查询完成")
except queue.Empty:
pass
# 更新队列积压深度显示
self.queue_var.set(f"{self.db_queue.qsize()} 条")
# 只要窗口还在,就继续调度自己
self.after(100, self._poll_results)
def _render_query_result(self, rows):
"""把查询结果渲染到文本框"""
self.result_text.config(state="normal")
self.result_text.delete("1.0", "end")
if not rows:
self.result_text.insert("end", "(暂无数据)\n")
else:
header = f"{'设备ID':<14}{'数值':>8} {'时间戳'}\n"
self.result_text.insert("end", header)
self.result_text.insert("end", "─" * 44 + "\n")
for row in rows:
ts_str = time.strftime(
"%Y-%m-%d %H:%M:%S", time.localtime(row["ts"])
)
line = f"{row['device_id']:<14}{row['value']:>8.2f} {ts_str}\n"
self.result_text.insert("end", line)
self.result_text.config(state="disabled")
# ── 退出处理 ──────────────────────────────
def _on_close(self):
"""
关窗口时:先通知工作线程退出,等它把队列清空再销毁窗口。
timeout=5 是保底,不让用户等太久。
"""
self.status_var.set("⏳ 正在等待工作线程退出…")
self.update() # 强制刷新一次 UI,让提示显示出来
self.worker.stop()
self.worker.join(timeout=5)
self.destroy()
# ─────────────────────────────────────────────
# 入口
# ─────────────────────────────────────────────
if __name__ == "__main__":
app = IndustrialApp()
app.mainloop()
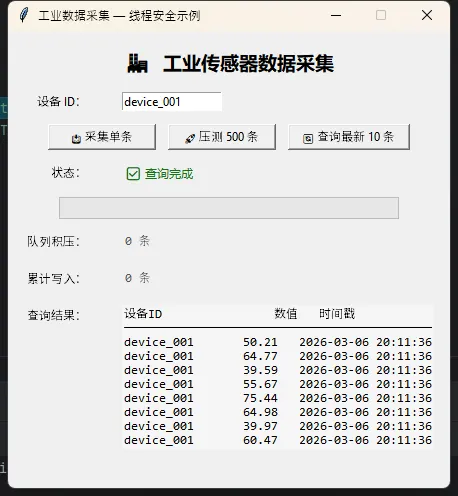
🧹 实践五:定期归档+VACUUM,别让数据库无限膨胀
SQLite删除数据之后,文件大小不会自动缩小。DELETE只是把页面标记为可复用,磁盘空间还占着。工业现场的存储往往是工控机上那块不大的SSD,放任数据库膨胀是要出事的。
python# ─────────────────────────────────────────────
# 归档核心逻辑
# ─────────────────────────────────────────────
def archive_old_data(
db_path: str,
keep_days: int = 30,
result_queue: queue.Queue = None,
) -> dict:
"""
把 keep_days 天之前的数据从主表迁移到归档表,然后删除主表记录。
返回操作摘要字典,同时(可选)把进度推入 result_queue 供 UI 消费。
注意:此函数运行在独立线程,绝对不能直接操作任何 Tkinter 控件。
"""
def _notify(msg_type: str, payload):
if result_queue is not None:
result_queue.put((msg_type, payload))
cutoff = time.time() - keep_days * 86400
cutoff_str = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(cutoff))
summary = {
"archived": 0,
"deleted": 0,
"vacuum_done": False,
"error": None,
"start_ts": time.time(),
"end_ts": None,
}
_notify("progress", f"📦 开始归档:迁移 {cutoff_str} 之前的数据…")
conn = sqlite3.connect(db_path)
try:
# ── 步骤 1:迁移旧数据到归档表 ────────────── # 先查一下要迁移多少条,给用户一个预期
count_row = conn.execute(
"SELECT COUNT(*) FROM sensor_data WHERE ts < ?", (cutoff,)
).fetchone()
to_archive = count_row[0] if count_row else 0
if to_archive == 0:
_notify("progress", f"✅ 没有需要归档的数据(基准时间:{cutoff_str})")
summary["end_ts"] = time.time()
return summary
_notify("progress", f"📋 共找到 {to_archive} 条待归档记录,开始迁移…")
conn.execute("""
INSERT INTO sensor_data_archive (device_id, value, ts) SELECT device_id, value, ts FROM sensor_data WHERE ts < ? """, (cutoff,))
summary["archived"] = to_archive
# ── 步骤 2:从主表删除已迁移的数据 ────────── result = conn.execute(
"DELETE FROM sensor_data WHERE ts < ?", (cutoff,)
)
summary["deleted"] = result.rowcount
conn.commit()
# 写维护日志
conn.execute(
"INSERT INTO maintenance_log(op, detail, exec_ts) VALUES(?,?,?)",
(
"archive",
f"archived={summary['archived']}, deleted={summary['deleted']}, "
f"cutoff={cutoff_str}",
time.time(),
),
)
conn.commit()
_notify(
"progress",
f"✅ 归档完成:迁移 {summary['archived']} 条,"
f"主表删除 {summary['deleted']} 条",
)
# ── 步骤 3:VACUUM 压缩数据库文件 ──────────── # VACUUM 会独占锁库,期间所有其他连接阻塞。
# 必须在维护窗口执行,生产时段禁止调用。
_notify("progress", "🔧 开始 VACUUM,正在压缩数据库文件…")
size_before = os.path.getsize(db_path) / 1024 / 1024 # MB
# VACUUM 不能在事务内执行,需要先确保没有未提交事务
conn.execute("VACUUM")
size_after = os.path.getsize(db_path) / 1024 / 1024
saved = size_before - size_after
summary["vacuum_done"] = True
conn.execute(
"INSERT INTO maintenance_log(op, detail, exec_ts) VALUES(?,?,?)",
(
"vacuum",
f"before={size_before:.2f}MB, after={size_after:.2f}MB, "
f"saved={saved:.2f}MB",
time.time(),
),
)
conn.commit()
_notify(
"progress",
f"✅ VACUUM 完成:{size_before:.2f}MB → {size_after:.2f}MB,"
f"释放 {saved:.2f}MB",
)
except sqlite3.Error as e:
summary["error"] = str(e)
_notify("error", f"❌ 归档出错:{e}")
try:
conn.rollback()
except Exception:
pass
finally:
conn.close()
summary["end_ts"] = time.time()
elapsed = summary["end_ts"] - summary["start_ts"]
_notify("done", f"🏁 维护任务结束,耗时 {elapsed:.1f}s")
return summary
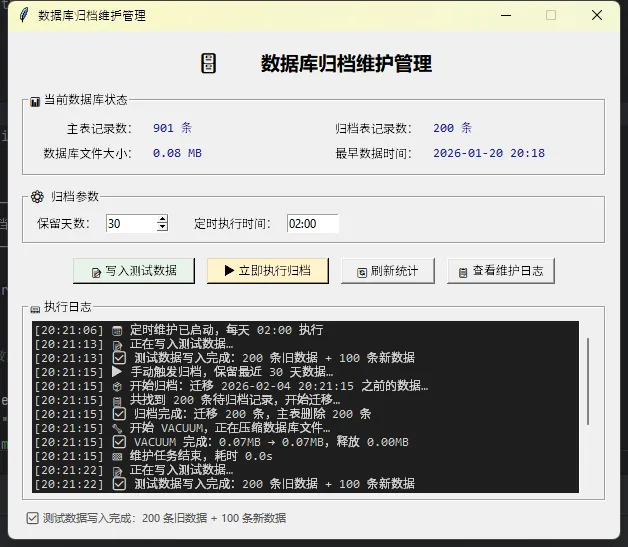
VACUUM这个操作有个大坑:执行期间整个数据库会被独占锁住,其他连接全部阻塞。数据量大的时候可能跑好几分钟。所以必须安排在凌晨维护窗口,绝对不能在白天生产时段跑。
🔒 实践六:连接池管理——多窗口场景的正确姿势
当你的Tkinter应用有多个窗口、多个模块都需要读写数据库时,连接管理就变得复杂了。每个地方都sqlite3.connect(),容易出现连接泄漏;全局共享一个连接,又有线程安全问题。
我的做法是用一个简单的线程本地存储来管理连接:
pythonimport threading
class DatabaseManager:
"""线程安全的数据库连接管理器(单例模式)"""
_instance = None
_lock = threading.Lock()
_local = threading.local() # 每个线程独立的存储空间
def __new__(cls, db_path: str = None):
with cls._lock:
if cls._instance is None:
cls._instance = super().__new__(cls)
cls._instance.db_path = db_path
return cls._instance
def get_connection(self) -> sqlite3.Connection:
"""获取当前线程的专属连接,没有就创建"""
if not hasattr(self._local, 'conn') or self._local.conn is None:
self._local.conn = sqlite3.connect(self.db_path)
self._local.conn.row_factory = sqlite3.Row # 让查询结果支持列名访问
self._local.conn.execute("PRAGMA journal_mode=WAL")
return self._local.conn
def close_connection(self):
"""关闭当前线程的连接"""
if hasattr(self._local, 'conn') and self._local.conn:
self._local.conn.close()
self._local.conn = None
def query(self, sql: str, params: tuple = ()) -> list:
conn = self.get_connection()
cursor = conn.execute(sql, params)
return cursor.fetchall()
def execute(self, sql: str, params: tuple = ()):
conn = self.get_connection()
conn.execute(sql, params)
conn.commit()
# 使用示例
db = DatabaseManager("industrial.db")
# 查询最近100条记录(支持列名访问)
rows = db.query(
"SELECT device_id, value, ts FROM sensor_data ORDER BY ts DESC LIMIT 100"
)
for row in rows:
print(f"设备: {row['device_id']}, 值: {row['value']}")
sqlite3.Row这个row_factory设置很多人不知道。加了之后,查询结果可以用列名访问(row['device_id']),比下标(row[0])可读性强太多,代码维护起来省很多力气。
📊 实践七:实时图表与数据库查询的解耦
最后一个实践,关于数据展示。很多人做实时曲线,喜欢每次刷新都去查一次数据库,然后重绘整个图表。数据量一大,这个操作慢得要命,而且完全没必要。
更好的做法是内存缓存 + 增量更新:
pythonimport tkinter as tk
from tkinter import ttk
from collections import deque
import sqlite3
import threading
import queue
import time
import random
import math
try:
import matplotlib
import matplotlib.pyplot as plt
matplotlib.use("TkAgg")
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # Windows下显示中文
plt.rcParams['axes.unicode_minus'] = False
from matplotlib.figure import Figure
from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg, NavigationToolbar2Tk
import matplotlib.dates as mdates
import datetime
HAS_MPL = True
except ImportError:
HAS_MPL = False
# ─────────────────────────────────────────────
# 数据库初始化
# ─────────────────────────────────────────────
def init_db(db_path: str):
conn = sqlite3.connect(db_path)
conn.executescript("""
PRAGMA journal_mode=WAL;
PRAGMA synchronous=NORMAL;
CREATE TABLE IF NOT EXISTS sensor_data (
id INTEGER PRIMARY KEY AUTOINCREMENT,
device_id TEXT NOT NULL,
value REAL NOT NULL,
ts REAL NOT NULL
);
CREATE INDEX IF NOT EXISTS idx_device_ts
ON sensor_data(device_id, ts DESC);
""")
conn.commit()
conn.close()
# ─────────────────────────────────────────────
# 线程安全的数据库管理器
# ─────────────────────────────────────────────
class DatabaseManager:
"""
每个线程持有独立连接(threading.local)。
查询结果支持列名访问(row_factory=sqlite3.Row)。
"""
_local = threading.local()
def __init__(self, db_path: str):
self.db_path = db_path
def _conn(self) -> sqlite3.Connection:
if not getattr(self._local, "conn", None):
self._local.conn = sqlite3.connect(self.db_path)
self._local.conn.row_factory = sqlite3.Row
self._local.conn.execute("PRAGMA journal_mode=WAL")
return self._local.conn
def query(self, sql: str, params: tuple = ()) -> list:
return self._conn().execute(sql, params).fetchall()
def execute(self, sql: str, params: tuple = ()):
conn = self._conn()
conn.execute(sql, params)
conn.commit()
def executemany(self, sql: str, data: list):
conn = self._conn()
conn.executemany(sql, data)
conn.commit()
# ─────────────────────────────────────────────
# 数据模拟器:在独立线程里持续写入假数据
# ─────────────────────────────────────────────
class DataSimulator(threading.Thread):
"""
模拟多台设备的传感器数据写入。
每台设备的波形不同,方便在图表上区分。
"""
DEVICES = {
"device_001": lambda t: 60 + 20 * math.sin(t / 5) + random.gauss(0, 1),
"device_002": lambda t: 80 + 15 * math.cos(t / 3) + random.gauss(0, 2),
"device_003": lambda t: 40 + 30 * abs(math.sin(t / 8)) + random.gauss(0, 1.5),
}
def __init__(self, db_manager: DatabaseManager, interval: float = 0.5):
super().__init__(daemon=True)
self.db = db_manager
self.interval = interval # 采集间隔(秒)
self._stop = threading.Event()
self._t = 0.0
def run(self):
while not self._stop.is_set():
batch = []
for device_id, fn in self.DEVICES.items():
batch.append((device_id, round(fn(self._t), 3), time.time()))
self.db.executemany(
"INSERT INTO sensor_data(device_id, value, ts) VALUES(?,?,?)",
batch,
)
self._t += self.interval
time.sleep(self.interval)
def stop(self):
self._stop.set()
# ─────────────────────────────────────────────
# 实时图表组件
# ─────────────────────────────────────────────
class RealtimeChart(tk.Frame):
"""
实时数据图表组件。
- 增量查询:只取比上次时间戳更新的数据,不做全表扫描
- deque 滑动窗口:自动丢弃最旧的点,内存占用恒定
- draw_idle():异步重绘,不阻塞 Tkinter 主线程
- 支持暂停/恢复、多设备切换、统计面板
"""
MAX_POINTS = 200 # 图表最多显示的数据点数
REFRESH_MS = 500 # 刷新间隔(毫秒)
# 每台设备对应的曲线颜色
COLORS = {
"device_001": "#2196F3", # 蓝
"device_002": "#F44336", # 红
"device_003": "#4CAF50", # 绿
}
def __init__(
self,
parent,
db_manager: DatabaseManager,
device_id: str,
on_device_change=None,
):
super().__init__(parent)
self.db = db_manager
self.device_id = device_id
self.on_device_change = on_device_change # 切换设备时的外部回调
# 滑动窗口缓冲区
self._ts_buf = deque(maxlen=self.MAX_POINTS)
self._val_buf = deque(maxlen=self.MAX_POINTS)
self._last_ts = 0.0
# 运行状态
self._paused = False
self._job_id = None # after() 返回的任务 ID,用于取消
self._build_toolbar()
if HAS_MPL:
self._build_chart()
else:
tk.Label(
self,
text="缺少 matplotlib,请执行:pip install matplotlib",
fg="red",
).pack(expand=True)
self._build_stats_bar()
self._schedule_refresh()
# ── 顶部工具栏 ───────────────────────────
def _build_toolbar(self):
bar = tk.Frame(self, bg="#f0f0f0", pady=4)
bar.pack(fill="x")
tk.Label(bar, text="设备:", bg="#f0f0f0").pack(side="left", padx=(10, 2))
self._device_var = tk.StringVar(value=self.device_id)
device_cb = ttk.Combobox(
bar,
textvariable=self._device_var,
values=list(DataSimulator.DEVICES.keys()),
width=14,
state="readonly",
)
device_cb.pack(side="left")
device_cb.bind("<<ComboboxSelected>>", self._on_device_selected)
tk.Label(bar, text=" 显示点数:", bg="#f0f0f0").pack(side="left")
self._points_var = tk.IntVar(value=self.MAX_POINTS)
pts_spin = tk.Spinbox(
bar, from_=20, to=500, increment=20,
textvariable=self._points_var, width=6,
command=self._on_points_changed,
)
pts_spin.pack(side="left")
# 暂停 / 恢复 按钮
self._pause_btn = tk.Button(
bar, text="⏸ 暂停",
width=8, bg="#fff3cd",
command=self._toggle_pause,
)
self._pause_btn.pack(side="left", padx=10)
# 清空缓冲区按钮
tk.Button(
bar, text="🗑 清空",
width=8, bg="#fde8e8",
command=self._clear_buffer,
).pack(side="left")
# 右侧:刷新频率提示
self._fps_var = tk.StringVar(value="")
tk.Label(
bar, textvariable=self._fps_var,
bg="#f0f0f0", fg="#888",
font=("Consolas", 8),
).pack(side="right", padx=10)
# ── 图表区域 ─────────────────────────────
def _build_chart(self):
color = self.COLORS.get(self.device_id, "#333")
self._fig = Figure(figsize=(9, 3.5), dpi=96)
self._fig.patch.set_facecolor("#fafafa")
self.ax = self._fig.add_subplot(111)
self.ax.set_facecolor("#f5f8ff")
self.ax.set_title(
f"设备 {self.device_id} — 实时数据",
fontsize=10, pad=6,
)
self.ax.set_xlabel("时间", fontsize=8)
self.ax.set_ylabel("数值", fontsize=8)
self.ax.tick_params(labelsize=7)
self.ax.grid(True, linestyle="--", alpha=0.4)
self.line, = self.ax.plot(
[], [], color=color, linewidth=1.4, label=self.device_id
)
self.dot, = self.ax.plot(
[], [], "o", color=color, markersize=5
)
def _fmt_ts(x, _):
try:
if x <= 0:
return ""
return time.strftime("%H:%M:%S", time.localtime(x))
except OSError:
return ""
self.ax.xaxis.set_major_formatter(
matplotlib.ticker.FuncFormatter(_fmt_ts)
)
for label in self.ax.get_xticklabels():
label.set_rotation(30)
label.set_ha("right")
self._fig.subplots_adjust(bottom=0.18) # 留出旋转后标签的空间
canvas = FigureCanvasTkAgg(self._fig, master=self)
canvas.get_tk_widget().pack(fill=tk.BOTH, expand=True)
self.canvas = canvas
# ── 底部统计栏 ───────────────────────────
def _build_stats_bar(self):
bar = tk.Frame(self, bg="#e8e8e8", pady=3)
bar.pack(fill="x")
self._stat_vars = {}
for key in ["最新值", "最大值", "最小值", "均值", "缓冲点数"]:
tk.Label(bar, text=f" {key}:", bg="#e8e8e8",
font=("微软雅黑", 8)).pack(side="left")
v = tk.StringVar(value="—")
self._stat_vars[key] = v
tk.Label(
bar, textvariable=v, bg="#e8e8e8",
fg="#1a1a8c", font=("Consolas", 8), width=8
).pack(side="left")
# ── 增量查询 ─────────────────────────────
def _fetch_incremental(self) -> bool:
"""
只查 ts > _last_ts 的新数据,最多取 500 条。
返回是否有新数据。
"""
rows = self.db.query(
"""
SELECT value, ts
FROM sensor_data
WHERE device_id = ? AND ts > ?
ORDER BY ts ASC
LIMIT 500
""",
(self.device_id, self._last_ts),
)
if not rows:
return False
for row in rows:
self._val_buf.append(row["value"])
self._ts_buf.append(row["ts"])
# 更新水位线:下次只取比这更新的
self._last_ts = self._ts_buf[-1]
return True
# ── 刷新逻辑 ─────────────────────────────
def _do_refresh(self):
"""真正执行一次刷新:查数据 → 更新图表 → 更新统计"""
t0 = time.perf_counter()
has_new = self._fetch_incremental()
if has_new and HAS_MPL and self._ts_buf:
ts_list = list(self._ts_buf)
val_list = list(self._val_buf)
# 更新曲线
self.line.set_xdata(ts_list)
self.line.set_ydata(val_list)
# 最新值标注点(只画最后一个点)
self.dot.set_xdata([ts_list[-1]])
self.dot.set_ydata([val_list[-1]])
# 自适应坐标范围
self.ax.relim()
self.ax.autoscale_view()
# 异步重绘:把重绘任务交给事件循环,不阻塞主线程
self.canvas.draw_idle()
# 更新统计栏
self._update_stats(val_list)
elapsed_ms = (time.perf_counter() - t0) * 1000
self._fps_var.set(f"耗时 {elapsed_ms:.1f}ms")
def _schedule_refresh(self):
"""用 after() 在主线程里循环调度刷新,暂停时跳过绘图但保持调度"""
if not self._paused:
self._do_refresh()
self._job_id = self.after(self.REFRESH_MS, self._schedule_refresh)
def _update_stats(self, val_list: list):
if not val_list:
return
self._stat_vars["最新值"].set(f"{val_list[-1]:.2f}")
self._stat_vars["最大值"].set(f"{max(val_list):.2f}")
self._stat_vars["最小值"].set(f"{min(val_list):.2f}")
self._stat_vars["均值"].set(f"{sum(val_list)/len(val_list):.2f}")
self._stat_vars["缓冲点数"].set(str(len(val_list)))
# ── 控件事件 ─────────────────────────────
def _toggle_pause(self):
self._paused = not self._paused
if self._paused:
self._pause_btn.config(text="▶ 恢复", bg="#d4edda")
else:
self._pause_btn.config(text="⏸ 暂停", bg="#fff3cd")
def _clear_buffer(self):
"""清空内存缓冲区,图表回到空白状态,但不删数据库数据"""
self._ts_buf.clear()
self._val_buf.clear()
# 重置水位线为当前时间,后续只取新数据
self._last_ts = time.time()
if HAS_MPL:
self.line.set_xdata([])
self.line.set_ydata([])
self.dot.set_xdata([])
self.dot.set_ydata([])
self.canvas.draw_idle()
for v in self._stat_vars.values():
v.set("—")
def _on_device_selected(self, _event=None):
"""切换设备:清空缓冲区,更新图表标题和曲线颜色"""
new_id = self._device_var.get()
if new_id == self.device_id:
return
self.device_id = new_id
self._clear_buffer()
if HAS_MPL:
color = self.COLORS.get(new_id, "#333")
self.line.set_color(color)
self.dot.set_color(color)
self.line.set_label(new_id)
self.ax.set_title(f"设备 {new_id} — 实时数据", fontsize=10, pad=6)
self.canvas.draw_idle()
if self.on_device_change:
self.on_device_change(new_id)
def _on_points_changed(self):
"""调整滑动窗口大小"""
new_max = self._points_var.get()
# deque 不支持直接修改 maxlen,重建一个
self._ts_buf = deque(self._ts_buf, maxlen=new_max)
self._val_buf = deque(self._val_buf, maxlen=new_max)
def destroy(self):
"""销毁前取消 after 任务,避免野指针回调"""
if self._job_id:
self.after_cancel(self._job_id)
super().destroy()
# ─────────────────────────────────────────────
# 主窗口:把图表组件嵌进去
# ─────────────────────────────────────────────
class App(tk.Tk):
DB_PATH = "realtime_demo.db"
def __init__(self):
super().__init__()
self.title("工业传感器实时监控")
self.geometry("960x560")
init_db(self.DB_PATH)
self.db = DatabaseManager(self.DB_PATH)
# 启动数据模拟器(0.5s 一条,模拟三台设备)
self.simulator = DataSimulator(self.db, interval=0.5)
self.simulator.start()
self._build_ui()
self.protocol("WM_DELETE_WINDOW", self._on_close)
def _build_ui(self):
# 顶部标题栏
header = tk.Frame(self, bg="#1565C0", pady=8)
header.pack(fill="x")
tk.Label(
header,
text="🏭 工业传感器实时监控平台",
bg="#1565C0", fg="white",
font=("微软雅黑", 13, "bold"),
).pack(side="left", padx=16)
# 模拟器状态提示
self._sim_var = tk.StringVar(value="● 模拟器运行中(0.5s/条,3台设备)")
tk.Label(
header,
textvariable=self._sim_var,
bg="#1565C0", fg="#90CAF9",
font=("微软雅黑", 8),
).pack(side="right", padx=16)
# 图表区域(Notebook 多标签,每台设备一个标签页)
nb = ttk.Notebook(self)
nb.pack(fill="both", expand=True, padx=8, pady=8)
self.charts = {}
for device_id in DataSimulator.DEVICES:
frame = tk.Frame(nb)
nb.add(frame, text=f" {device_id} ")
chart = RealtimeChart(
frame,
db_manager=self.db,
device_id=device_id,
)
chart.pack(fill="both", expand=True)
self.charts[device_id] = chart
# 底部状态栏
status_bar = tk.Frame(self, bg="#eeeeee", pady=3)
status_bar.pack(fill="x", side="bottom")
tk.Label(
status_bar,
text="提示:切换标签页查看不同设备 | 暂停后图表停止更新,数据继续写入",
bg="#eeeeee", fg="#666",
font=("微软雅黑", 8),
).pack(side="left", padx=10)
def _on_close(self):
self.simulator.stop()
# 销毁所有图表,取消 after 任务
for chart in self.charts.values():
chart.destroy()
self.destroy()
# ─────────────────────────────────────────────
# 入口
# ─────────────────────────────────────────────
if __name__ == "__main__":
if not HAS_MPL:
print("请先安装 matplotlib:pip install matplotlib")
app = App()
app.mainloop()
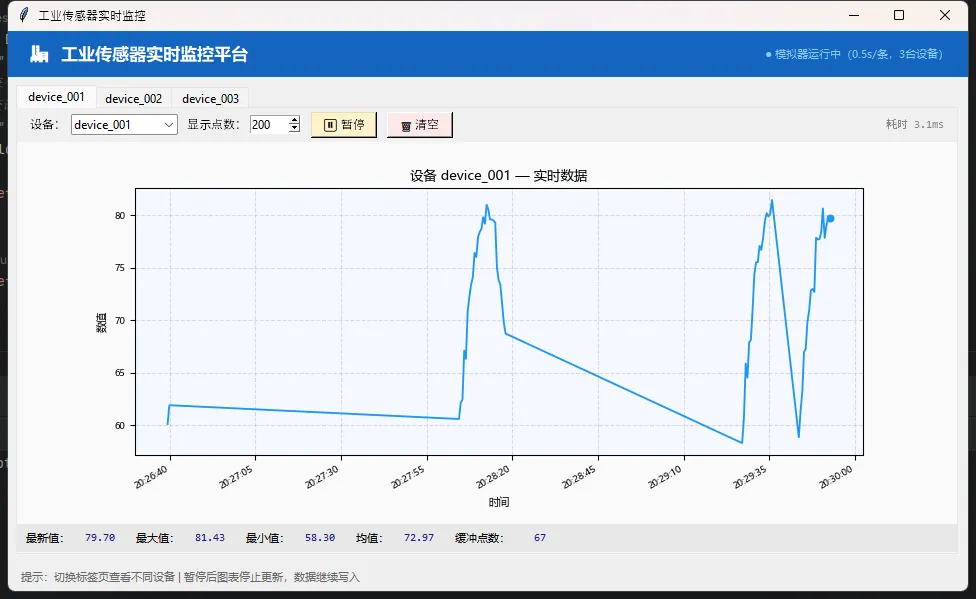
canvas.draw_idle()而不是canvas.draw()——这个细节很关键。draw()是同步的,会阻塞到绘制完成;draw_idle()是异步的,把重绘任务交给事件循环处理,主线程不会卡住。
💬 互动话题
你在做工业上位机或者本地数据存储的时候,遇到过哪些让你印象深刻的坑?欢迎在评论区聊聊——是SQLite锁的问题,还是Tkinter线程安全,还是别的什么?
实战挑战:基于本文的BatchStorageWorker,加入一个"写入失败自动重试"机制,最多重试3次,每次间隔递增。思路不唯一,有兴趣的可以试试。
🎯 三句话总结
线程隔离是根基——主线程管界面,工作线程管数据库,队列做桥梁,这个结构不能乱。
批量提交是杠杆——同样的数据量,批量写入比逐条提交快几十倍,工业场景下这不是优化,是必须。
索引是时间换空间的艺术——建表时想清楚查询模式,提前把索引布好,百万数据查询毫秒级响应不是梦。
📚 延伸学习路线
如果这套架构你已经掌握了,下一步可以往这几个方向走:SQLAlchemy ORM(让数据库操作更优雅)、asyncio + aiosqlite(异步IO方案,适合更高并发场景)、InfluxDB(专为时序数据设计的数据库,工业数据量极大时的替代方案)。Tkinter的话,CustomTkinter值得看看,现代化的UI风格,API和原生Tkinter基本兼容,迁移成本低。
代码模板已经整理好,建议收藏备用——下次接工业上位机项目,直接拿BatchStorageWorker和DatabaseManager当脚手架,能省不少时间。
#Python开发 #Tkinter #SQLite #工业数据 #性能优化
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!