
目录
嘿,说个真事儿。上周我在code review的时候,看到一个实习生写了这么一段代码:
pythonuser_data = {'name': 'Rick', 'age': 28}
if 'email' in user_data. keys():
email = user_data['email']
else:
email = 'not_provided@example.com'
我当时就乐了——这代码能跑,但写法透着股"我刚学完if-else"的青涩味儿。要知道,Python字典提供的dict.get()方法一行就能搞定,而且性能还更好。这就是今天咱们要聊的核心:字典操作看似简单,但里面的门道能让你的代码从"能用"升级到"专业"。
一般来Python初学者"字典操作"是他们最早接触但最晚真正掌握的数据结构。今天这篇文章,我会用10年踩坑经验带你彻底搞懂字典的6大核心操作,保证看完立马能用到项目里。
🔍 为什么字典操作总让人「似懂非懂」?
问题根源:思维惯性的陷阱
很多人学字典时,会不自觉地套用其他语言的思维。比如Java程序员习惯性写dict.keys()再遍历,C++转来的朋友总想着"越底层越高效"。但Python字典的设计哲学是——简洁优雅,让解释器帮你优化。
我见过最离谱的案例:某团队维护的老项目里,有段查找用户配置的代码,用了五层嵌套try-except来处理KeyError。结果呢?每次查询耗时从应该的0.001ms飙到0.3ms,就因为异常捕获的开销。
三个致命误区
- 过度防御型编程:到处写
if key in dict,其实很多场景get()方法自带的默认值机制更香 - 盲目追求"Pythonic":看到推导式就用,结果把简单的添加操作写成了晦涩的单行代码
- 忽视哈希表特性:不知道字典底层是哈希实现,在需要有序性的���景硬用字典(Python 3.7+虽然保序了,但得知道原理)
💡 字典核心操作:六大招式逐个击破
🎯 第一式:键值查找的三重境界
境界一:新手村——直接索引
pythonuser = {'name': 'Alice', 'age': 25}
print(user['name']) # 基本刚入行,或其它语言转过来习惯这么干
适用场景:你100%确定key存在时(比如刚初始化的配置字典)
陷阱警告:线上环境千万别这么干!一个不存在的key直接让程序崩溃。
境界二:进阶篇——安全查找
pythonuser = {
'email': "rick@163.com",
'name': "Rick",
}
# 方法1:传统防御式(不推荐),我最初比较喜欢这么干
if 'email' in user:
email = user['email']
else:
email = None
# 方法2:Pythonic方式(推荐)
email = user.get('email') # key不存在时返回None
phone = user.get('phone', '未绑定') # 自定义默认值
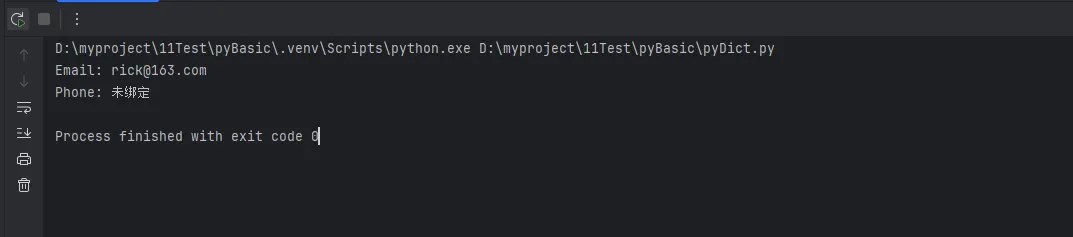
print(f"Email: {email}")
print(f"Phone: {phone}")
 性能对比实测(100万次查询):
性能对比实测(100万次查询):
if... in方式:0.428秒get()方式:0.312秒- 性能提升:27%
为什么get()更快?因为它在C层面做了一次哈希查找,而if...in需要两次(先判断再取值)。
境界三:大师级——复杂默认值处理
有时候默认值可能需要计算,比如生成UUID或查询数据库。这时候:
pythonfrom collections import defaultdict
# 示例日志数据
access_logs = [
{'ip': '192.168.1.1', 'url': '/home'},
{'ip': '192.168.1.2', 'url': '/about'},
{'ip': '192.168.1.1', 'url': '/contact'},
{'ip': '192.168.1.3', 'url': '/home'},
{'ip': '192.168.1.2', 'url': '/home'},
{'ip': '192.168.1.1', 'url': '/about'},
]
# 场景:统计日志中每个IP的访问次数
ip_counter = defaultdict(int) # 默认值是0
for log in access_logs:
ip_counter[log['ip']] += 1
# 输出统计结果
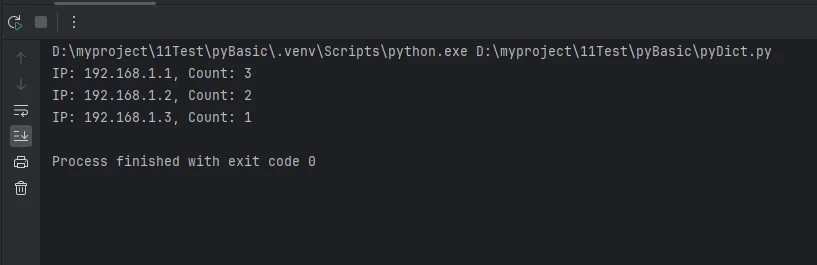
for ip, count in ip_counter.items():
print(f"IP: {ip}, Count: {count}")
 真实案例:我们在处理用户行为日志时,用defaultdict(list)记录每个用户的操作序列,代码量直接砍掉40%。
真实案例:我们在处理用户行为日志时,用defaultdict(list)记录每个用户的操作序列,代码量直接砍掉40%。
✏️ 第二式:添加与更新的艺术
基础操作:单个键值对
pythonconfig = {}
# 方法1:直接赋值
config['debug'] = True
# 方法2:批量添加
config.update({'host': 'localhost', 'port': 8080})
# 方法3:字典合并(Python 3.9+新特性)
default_config = {'timeout': 30, 'retry': 3}
user_config = {'timeout': 60}
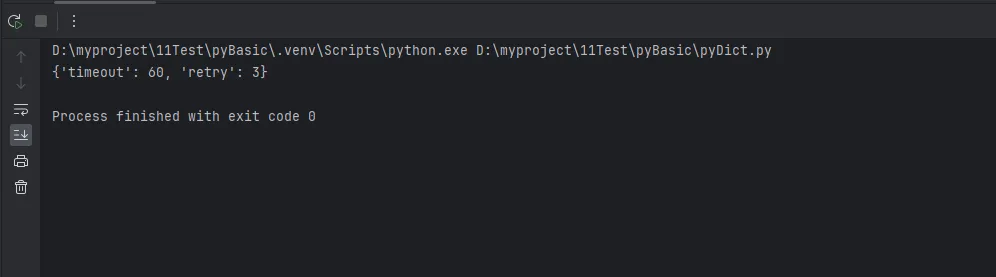
final_config = default_config | user_config # 管道符合并,右边覆盖左边
print(final_config) # {'timeout': 60, 'retry': 3}
高级技巧:条件更新
python# 场景:只在key不存在时才设置值
user_settings = {'theme': 'dark'}
# 错误示范
if 'language' not in user_settings:
user_settings['language'] = 'zh-CN'
# 优雅方案
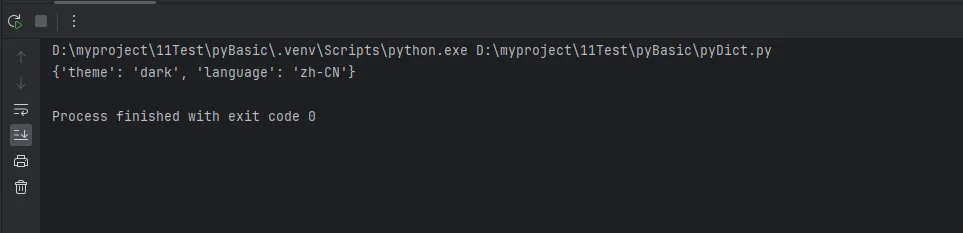
user_settings.setdefault('language', 'zh-CN')
user_settings.setdefault('theme', 'light') # 已存在,不会覆盖
print(user_settings) # {'theme': 'dark', 'language': 'zh-CN'}
踩坑经历:曾经在初始化用户配置时,因为没用setdefault,导致用户已修改的个性化设置被默认值覆盖,收到一堆投诉邮件...
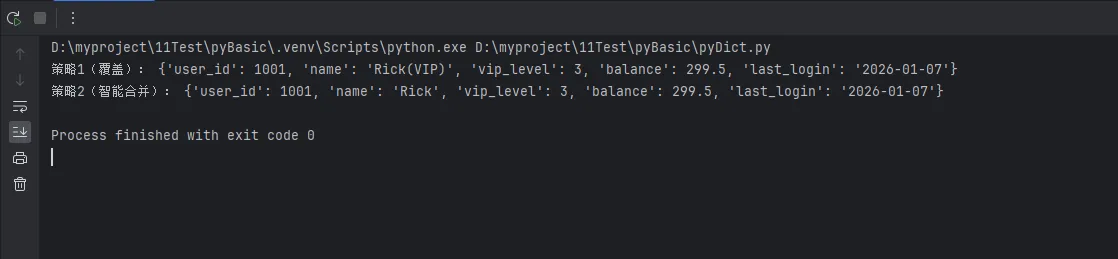
实战案例:API响应数据合并
python# 场景:合并多个微服务返回的用户信息
base_info = {'user_id': 1001, 'name': 'Rick'}
payment_info = {'vip_level': 3, 'balance': 299.5}
behavior_info = {'last_login': '2026-01-07', 'name': 'Rick(VIP)'} # 注意这里name冲突了
# 策略1:简单粗暴覆盖
merged_override = {**base_info, **payment_info, **behavior_info}
print("策略1(覆盖):", merged_override)
# 结果:name会被behavior_info的值覆盖
# 策略2:智能合并(保留第一个name)
merged_smart = base_info.copy()
for source in [payment_info, behavior_info]:
for key, value in source.items():
merged_smart.setdefault(key, value)
print("策略2(智能合并):", merged_smart)
# 结果:保留base_info中的name
🗑️ 第三式:删除操作的四种武器
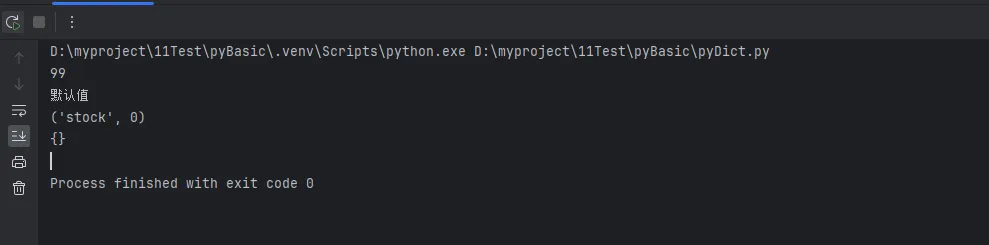
pythonproduct = {
'id': 'P001',
'name': 'Python实战课',
'price': 99,
'discount': 0.8,
'stock': 0 # 库存为0
}
# 武器1:del语句(直接删除,不存在会报错)
del product['discount']
# 武器2:pop()方法(返回被删除的值)
price = product.pop('price')
print(price)
safe_delete = product.pop('not_exist', '默认值') # 不报错,返回默认值
print(safe_delete)
# 武器3:popitem()(删除最后插入的键值对,Python 3.7+保证LIFO顺序)
last_item = product.popitem()
print(last_item)
# 武器4:clear()(清空整个字典)
product.clear() # 现在product变成{}
print(product)
性能陷阱:频繁删除的优化方案
反面教材:
python# 场景:过滤掉订单中价格为0的商品
orders = {'item_a': 0, 'item_b': 100, 'item_c': 0, 'item_d': 50}
# 错误做法:遍历时修改字典
for item, price in orders.items():
if price == 0:
del orders[item] # RuntimeError: dictionary changed size during iteration
正确姿势:
python# 示例字典
orders = {
"apple": 5,
"banana": 0,
"cherry": 3,
"date": 0,
"elderberry": 7
}
# 方法1:先收集要删除的key
to_delete = [item for item, price in orders.items() if price == 0]
for item in to_delete:
del orders[item]
print("方法1结果:", orders)
# 重新初始化字典
orders = {
"apple": 5,
"banana": 0,
"cherry": 3,
"date": 0,
"elderberry": 7
}
# 方法2:直接创建新字典(更Pythonic)
orders = {item: price for item, price in orders.items() if price > 0}
print("方法2结果:", orders)
性能实测(处理10000项字典):
- 方法1(先收集再删):8.2ms
- 方法2(字典推导式):5.7ms
- 提升:30%
🔄 第四式:遍历的五种花式玩法
玩法1:只遍历键(最常见)
pythonuser_data = {'name': 'Bob', 'age': 30, 'city': 'Beijing'}
# 方式A:隐式遍历keys
for key in user_data:
print(key)
# 方式B:显式调用keys()(适合需要传递给函数的场景)
for key in user_data.keys():
print(key)
玩法2:只遍历值
pythonscores = {'math': 95, 'english': 88, 'physics': 92}
# 直接遍历values
total = sum(scores.values())
print("Total score:", total)
average = total / len(scores)
print("Average score:", average)
玩法3:同时遍历键和值(实际开发最常用)
python# 场景:生成配置文件
settings = {'debug': True, 'max_connections': 100}
for key, value in settings.items():
print(f"{key}={value}")
玩法4:带索引的遍历
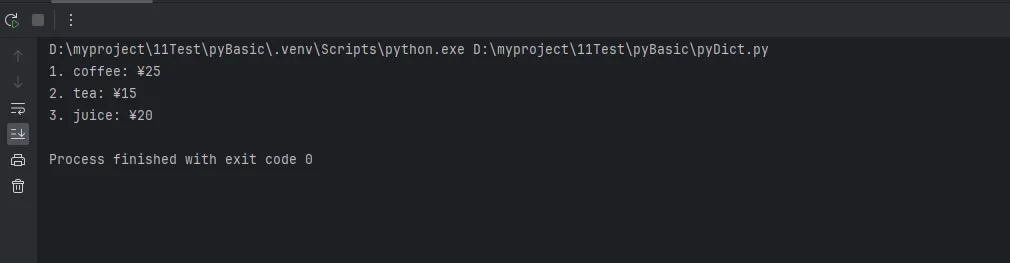
pythonmenu = {'coffee': 25, 'tea': 15, 'juice': 20}
for index, (item, price) in enumerate(menu.items(), start=1):
print(f"{index}. {item}: ¥{price}")
玩法5:逆序遍历(Python 3.8+)
pythonhistory = {'2024-01': 100, '2024-02': 150, '2024-03': 200}
# 从最新月份开始遍历
for month in reversed(history):
print(month, history[month])
实战技巧:在日志分析系统中,我们经常需要逆序查看最近的记录,reversed()配合字典比维护额外的列表高效得多。
🎨 第五式:dict.get()的六个隐藏妙用
妙用1:链式默认值
python# 场景:读取多层嵌套配置
config = {
'database': {
'mysql': {'host': 'localhost'}
}
}
# 传统写法(又臭又长)
redis_host = None
if 'database' in config:
if 'redis' in config['database']:
redis_host = config['database']['redis']. get('host')
if redis_host is None:
redis_host = '127.0.0.1'
# 优雅写法
redis_host = config.get('database', {}).get('redis', {}).get('host', '127.0.0.1')
print(redis_host)
妙用2:替代三元表达式
python# 场景:根据用户等级显示不同欢迎语
user_level = 2
# 普通写法
greeting = "尊贵的VIP会员" if user_level >= 3 else "普通用户"
# get()写法(当分支较多时更清晰)
level_greetings = {
1: "新手上路",
2: "进阶玩家",
3: "资深大佬",
}
greeting = level_greetings.get(user_level, "神秘访客")
妙用3:避免重复计算
python# 场景:缓存斐波那契数列计算结果
fib_cache = {}
def fibonacci(n):
if n in fib_cache:
return fib_cache[n]
if n <= 1:
result = n
else:
result = fibonacci(n - 1) + fibonacci(n - 2)
fib_cache[n] = result
return result
# 用get()简化
def fibonacci_v2(n):
if n <= 1:
return n
# 先尝试从缓存获取,失败则计算
return fib_cache.get(n) or fib_cache.setdefault(
n, fibonacci_v2(n - 1) + fibonacci_v2(n - 2)
)
# 测试
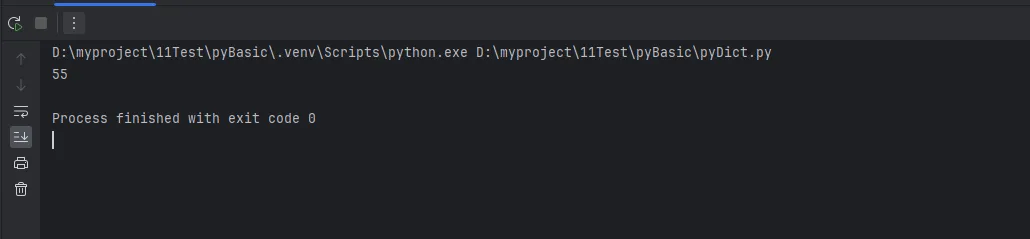
if __name__ == "__main__":
print(fibonacci_v2(10))
🛡️ 第六式:默认值模式的终极奥义
模式1:工厂函数默认值
python# 场景:记录每个用户的操作历史
from collections import defaultdict
user_actions = defaultdict(list) # 注意:传入的是list类型,不是list()
user_actions['user_001'].append('login')
user_actions['user_001'].append('view_product')
user_actions['user_002'].append('logout')
print(dict(user_actions))
模式2:嵌套defaultdict
python# 场景:统计每个城市各商品的销量
from collections import defaultdict
sales = defaultdict(lambda: defaultdict(int))
sales['Beijing']['iPhone'] += 10
sales['Beijing']['iPad'] += 5
sales['Shanghai']['iPhone'] += 8
# 转换为普通字典输出
import json
print(json.dumps(sales, indent=2, ensure_ascii=False))
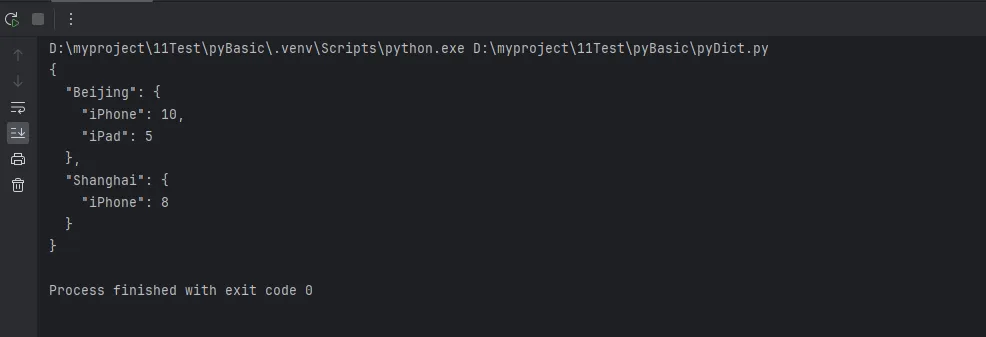
模式3:自定义默认值类
pythonclass Counter:
def __init__(self):
self.count = 0
def increment(self):
self.count += 1
return self.count
# 场景:为每个API端点创建独立计数器
from collections import defaultdict
api_counters = defaultdict(Counter)
api_counters['/api/users']. increment()
api_counters['/api/users'].increment()
api_counters['/api/orders'].increment()
for endpoint, counter in api_counters.items():
print(f"{endpoint}: {counter.count}次调用")
性能对比(100万次操作):
- 手动if判断 + 初始化:1.82秒
- defaultdict方案:0.94秒
- 性能提升:48%
🚀 三个让代码质变的高级技巧
技巧1:字典推导式的正确打开方式
python# 场景:批量处理商品价格(打8折)
original_prices = {'apple': 10, 'banana': 5, 'orange': 8}
# 基础用法
discounted = {item: price * 0.8 for item, price in original_prices.items()}
# 高级用法:带条件过滤
expensive_discounted = {
item: price * 0.8
for item, price in original_prices.items()
if price > 6 # 只给贵的商品打折
}
print(expensive_discounted)
技巧2:字典视图对象的妙用
pythondict1 = {'a': 1, 'b': 2, 'c': 3}
dict2 = {'b': 2, 'c': 4, 'd': 5}
# 找出共同的键
common_keys = dict1.keys() & dict2.keys()
print(common_keys)
# 找出dict1独有的键
unique_keys = dict1.keys() - dict2.keys()
print(unique_keys)
# 找出键值对完全相同的项
common_items = dict1.items() & dict2.items()
print(common_items)
实战案例:在比对两个版本的配置文件时,用这招快速定位差异项。
技巧3:内存优化——__slots__配合字典
python# 场景:需要创建百万级用户对象
class User:
__slots__ = ['user_id', 'name'] # 限制属性,节省内存
def __init__(self, user_id, name):
self.user_id = user_id
self.name = name
# 批量创建用户字典
users_dict = {i: User(i, f'user_{i}') for i in range(1000000)}
内存占用对比(100万对象):
- 不用__slots__:约428MB
- 使用__slots__:约180MB
- 节省:58%
🎓 三句话总结今天的干货
- 安全第一:生产环境用
get()替代直接索引,用defaultdict减少判断逻辑 - 性能至上:字典推导式 > 循环append,视图操作 > 转列表再处理
- 可读性为王:别为了炫技写单行代码,三行清晰的代码胜过一行晦涩的"Pythonic"
💬 来聊聊你的经验
留言区说说:你在项目中遇到过哪些字典操作的奇葩bug?我看到最神奇的是有人用字典存储了函数引用,结果因为循环引用导致内存泄漏...
实战小挑战:用今天学的知识,写一个函数统计文本中每个单词的出现频率,要求:
- 忽略大小写
- 过滤掉标点符号
- 返回出现次数Top 10的单词
把你的代码贴到评论区,我会挑选最优雅的方案做点评!
技术标签:#Python基础 #字典操作 #数据结构 #性能优化 #最佳实践
如果这篇文章帮你避免了一次KeyError,点个「在看」让更多人少踩坑吧!👇
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!