
目录
在日常的Python开发工作中,数据库操作是绕不开的话题。特别是在Windows环境下进行上位机开发时,我们经常需要与MySQL数据库打交道,进行数据的增删改查操作。很多初学者在面对数据库查询时总是感到头疼:连接配置复杂、SQL语句容易出错、数据处理繁琐...
今天这篇文章将彻底解决这些问题! 我将用最简洁的方式,带你掌握Python操作MySQL的核心技巧,让数据查询变得像写Hello World一样简单。无论你是Python新手还是有一定基础的开发者,都能从中获得实用的编程技巧和最佳实践。
🔍 问题分析:数据查询的常见痛点
在实际项目中,我们经常遇到以下几个问题:
1. 连接配置繁琐
每次都要手动配置数据库连接参数,代码重复度高,容易出错。
2. SQL注入风险
直接拼接SQL语句存在安全隐患,特别是在处理用户输入时。
3. 数据处理复杂
查询结果的格式转换、异常处理等操作让代码变得臃肿。
4. 连接资源管理
忘记关闭数据库连接导致资源泄露,影响应用性能。
💡 解决方案:构建高效查询框架
针对以上问题,我们来构建一个简洁高效的MySQL查询解决方案。
🛠️ 环境准备
首先安装必要的依赖包:
Bashpip install pymysql pandas
🚀 代码实战:从基础到进阶
📦 基础连接类设计
让我们先创建一个通用的数据库连接类:
Pythonimport pymysql
import pandas as pd
from contextlib import contextmanager
import logging
class MySQLHelper:
"""MySQL数据库操作助手类"""
def __init__(self, host='localhost', port=3306, user='root',
password='', database='', charset='utf8mb4'):
"""
初始化数据库连接参数
Args:
host: 数据库主机地址
port: 端口号
user: 用户名
password: 密码
database: 数据库名
charset: 字符编码
"""
self.config = {
'host': host,
'port': port,
'user': user,
'password': password,
'database': database,
'charset': charset,
'autocommit': True
}
@contextmanager
def get_connection(self):
"""
获取数据库连接的上下文管理器
自动处理连接的打开和关闭
"""
conn = None
try:
conn = pymysql.connect(**self.config)
yield conn
except Exception as e:
if conn:
conn.rollback()
logging.error(f"数据库操作异常: {e}")
raise
finally:
if conn:
conn.close()
🔥 核心查询方法实现
Pythondef query_to_dict(self, sql, params=None):
"""
执行查询并返回字典列表格式
Args:
sql: SQL查询语句
params: 参数元组,用于防止SQL注入
Returns:
list: 查询结果的字典列表
"""
with self.get_connection() as conn:
cursor = conn.cursor(pymysql.cursors.DictCursor)
cursor.execute(sql, params)
return cursor.fetchall()
def query_to_dataframe(self, sql, params=None):
"""
执行查询并返回pandas DataFrame
Args:
sql: SQL查询语句
params: 参数元组
Returns:
pandas.DataFrame: 查询结果
"""
with self.get_connection() as conn:
return pd.read_sql(sql, conn, params=params)
def query_single_value(self, sql, params=None):
"""
查询单个值(如COUNT、SUM等聚合函数结果)
Args:
sql: SQL查询语句
params: 参数元组
Returns:
单个值或None
"""
with self.get_connection() as conn:
cursor = conn.cursor()
cursor.execute(sql, params)
result = cursor.fetchone()
return result[0] if result else None
def execute_sql(self, sql, params=None):
"""
执行增删改操作
Args:
sql: SQL语句
params: 参数元组
Returns:
int: 受影响的行数
"""
with self.get_connection() as conn:
cursor = conn.cursor()
affected_rows = cursor.execute(sql, params)
conn.commit()
return affected_rows
⭐ 高级查询功能
Pythondef batch_insert(self, table, data_list, ignore_duplicate=False):
"""
批量插入数据
Args:
table: 表名
data_list: 数据列表,每个元素为字典
ignore_duplicate: 是否忽略重复数据
Returns:
int: 成功插入的行数
"""
if not data_list:
return 0
# 获取列名
columns = list(data_list[0].keys())
placeholders = ', '.join(['%s'] * len(columns))
columns_str = ', '.join([f'`{col}`' for col in columns])
# 构建SQL语句
ignore_clause = 'IGNORE' if ignore_duplicate else ''
sql = f"INSERT {ignore_clause} INTO `{table}` ({columns_str}) VALUES ({placeholders})"
# 准备数据
values = [[item.get(col) for col in columns] for item in data_list]
with self.get_connection() as conn:
cursor = conn.cursor()
affected_rows = cursor.executemany(sql, values)
conn.commit()
return affected_rows
def paginate_query(self, sql, page=1, page_size=20, params=None):
"""
分页查询
Args:
sql: 基础SQL查询语句(不包含LIMIT)
page: 页码(从1开始)
page_size: 每页记录数
params: 查询参数
Returns:
dict: 包含数据和分页信息的字典
"""
# 计算总记录数
count_sql = f"SELECT COUNT(*) as total FROM ({sql}) as temp_table"
total = self.query_single_value(count_sql, params)
# 计算分页参数
offset = (page - 1) * page_size
paginated_sql = f"{sql} LIMIT {offset}, {page_size}"
# 获取当前页数据
data = self.query_to_dict(paginated_sql, params)
return {
'data': data,
'pagination': {
'current_page': page,
'page_size': page_size,
'total_records': total,
'total_pages': (total + page_size - 1) // page_size
}
}
🎯 实际应用示例
Python# 使用示例
def main():
# 初始化数据库连接
db = MySQLHelper(
host='localhost',
user='root',
password='xxxxx',
database='testdb'
)
# 示例1:基础查询
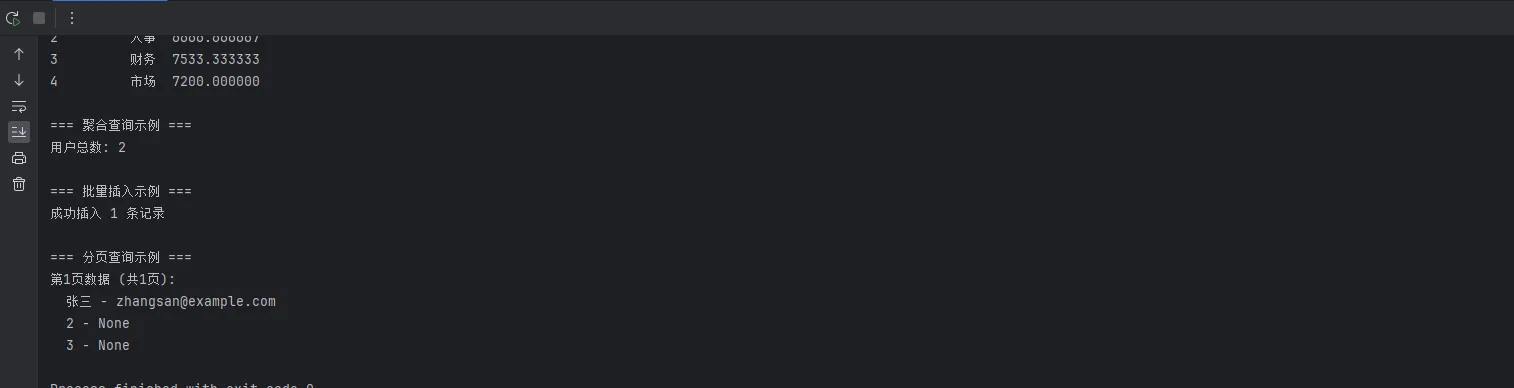
print("=== 基础查询示例 ===")
users = db.query_to_dict("SELECT * FROM users WHERE age > %s", (25,))
for user in users:
print(f"用户: {user['name']}, 年龄: {user['age']}")
# 示例2:使用pandas处理数据
print("\n=== 数据分析示例 ===")
df = db.query_to_dataframe("SELECT department, AVG(salary) as avg_salary FROM employees GROUP BY department")
print("各部门平均薪资:")
print(df)
# 示例3:聚合查询
print("\n=== 聚合查询示例 ===")
total_users = db.query_single_value("SELECT COUNT(*) FROM users")
print(f"用户总数: {total_users}")
# 示例4:批量插入
print("\n=== 批量插入示例 ===")
new_users = [
{'name': '张三', 'age': 28, 'email': 'zhangsan@example.com'},
{'name': '李四', 'age': 32, 'email': 'lisi@example.com'},
{'name': '王五', 'age': 26, 'email': 'wangwu@example.com'}
]
inserted_count = db.batch_insert('users', new_users, ignore_duplicate=True)
print(f"成功插入 {inserted_count} 条记录")
# 示例5:分页查询
print("\n=== 分页查询示例 ===")
result = db.paginate_query("SELECT * FROM users ORDER BY id", page=1, page_size=5)
print(f"第1页数据 (共{result['pagination']['total_pages']}页):")
for user in result['data']:
print(f" {user['name']} - {user['email']}")
if __name__ == "__main__":
main()
📊 性能监控装饰器
Pythonimport time
from functools import wraps
def query_timer(func):
"""查询性能监控装饰器"""
@wraps(func)
def wrapper(self, *args, **kwargs):
start_time = time.time()
result = func(self, *args, **kwargs)
execution_time = time.time() - start_time
# 记录慢查询(超过1秒)
if execution_time > 1.0:
logging.warning(f"慢查询警告: {func.__name__} 执行时间: {execution_time:.2f}秒")
return result
return wrapper
# 在查询方法上应用装饰器
class OptimizedMySQLHelper(AdvancedMySQLHelper):
@query_timer
def query_to_dict(self, sql, params=None):
return super().query_to_dict(sql, params)
@query_timer
def query_to_dataframe(self, sql, params=None):
return super().query_to_dataframe(sql, params)
🎯 最佳实践总结
通过本文的详细讲解,我们完成了从基础到进阶的Python MySQL查询完整方案。让我总结三个核心要点:
🔹 安全第一原则:始终使用参数化查询,避免SQL注入风险。我们的解决方案通过参数绑定和特殊字符转义,确保了数据库操作的安全性。
🔹 资源管理自动化:利用Python的上下文管理器特性,实现了数据库连接的自动管理。无论查询成功还是异常,都能确保连接资源得到正确释放,这对于生产环境的稳定运行至关重要。
🔹 功能模块化设计:通过类的继承和混入模式,我们构建了可扩展的查询框架。从基础查询到高级功能,再到性能优化,每个模块都可以独立使用和扩展。
这套解决方案不仅适用于日常的数据查询需求,更为复杂的上位机开发项目提供了坚实的数据层基础。在实际应用中,你可以根据项目需求选择合适的功能组合,让Python开发变得更加高效和优雅!
如果这篇文章对你的Python开发有帮助,欢迎分享给更多的编程同伴。在数据驱动的时代,掌握高效的数据库操作技巧,就是掌握了开发的核心竞争力!
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!