
Press Ctrl+ and K to search
目录
在当今的Python开发中,JSON数据处理几乎是每个开发者都会遇到的核心技能。无论你是在开发Web API、处理配置文件,还是进行数据分析,JSON都扮演着数据交换的重要角色。本文将从实战角度出发,带你掌握Python中JSON数据处理的各种技巧和最佳实践,让你在面对复杂的JSON数据时游刃有余。
🔍 问题分析:为什么JSON处理如此重要?
现实场景中的JSON应用
在实际的Python开发项目中,我们经常会遇到这些场景:
- API接口调用:从第三方服务获取JSON格式的响应数据
- 配置文件管理:应用程序的配置信息存储
- 数据库交互:NoSQL数据库的文档存储
- 日志处理:结构化日志的解析和分析
常见的JSON处理难点
- 数据类型转换:Python对象与JSON格式的相互转换
- 异常处理:处理格式错误或数据缺失的情况
- 性能优化:大量JSON数据的高效处理
- 中文编码:Windows环境下的编码问题
💡 解决方案:Python JSON处理核心技术
🛠️ 基础工具介绍
Python内置的json模块提供了完整的JSON处理功能:
Pythonimport json
# 四个核心方法
# json.dumps() - Python对象转JSON字符串
# json.loads() - JSON字符串转Python对象
# json.dump() - Python对象写入文件
# json.load() - 从文件读取JSON数据
🏗️ 数据结构映射关系
| Python类型 | JSON类型 | 注意事项 |
|---|---|---|
| dict | object | 键必须是字符串 |
| list, tuple | array | tuple会转为array |
| str | string | 自动处理Unicode |
| int, float | number | 精度问题需注意 |
| True/False | true/false | 布尔值转换 |
| None | null | 空值处理 |
💻 代码实战:从基础到进阶
🔥 基础操作:序列化与反序列化
Pythonimport json
# 1. 基本的序列化操作
data = {
"name": "张三",
"age": 25,
"skills": ["Python", "JavaScript", "SQL"],
"is_active": True,
"address": None
}
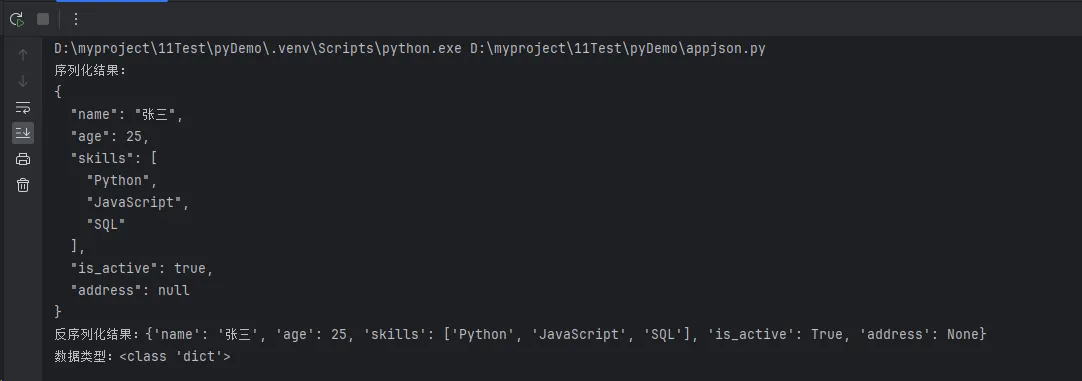
# Python对象转JSON字符串
json_str = json.dumps(data, ensure_ascii=False, indent=2)
print("序列化结果:")
print(json_str)
# JSON字符串转Python对象
parsed_data = json.loads(json_str)
print(f"反序列化结果:{parsed_data}")
print(f"数据类型:{type(parsed_data)}")
关键参数解析:
ensure_ascii=False:支持中文字符输出indent=2:格式化输出,便于阅读
🚀 文件操作:读写JSON文件
Pythonimport json
import os
# 示例数据
user_config = {
"database": {
"host": "localhost",
"port": 3306,
"username": "admin",
"password": "123456"
},
"cache": {
"redis_host": "127.0.0.1",
"redis_port": 6379
},
"log_level": "INFO"
}
# 写入JSON文件
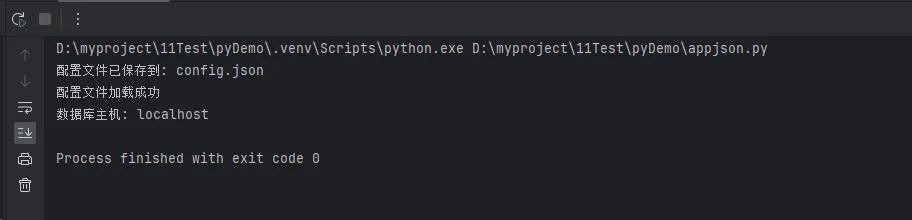
def save_config(config_data, filename="config.json"):
try:
with open(filename, 'w', encoding='utf-8') as f:
json.dump(config_data, f, ensure_ascii=False, indent=4)
print(f"配置文件已保存到: {filename}")
except Exception as e:
print(f"保存配置文件失败: {e}")
# 读取JSON文件
def load_config(filename="config.json"):
try:
if not os.path.exists(filename):
print(f"配置文件 {filename} 不存在")
return None
with open(filename, 'r', encoding='utf-8') as f:
config = json.load(f)
print("配置文件加载成功")
return config
except json.JSONDecodeError as e:
print(f"JSON格式错误: {e}")
return None
except Exception as e:
print(f"读取配置文件失败: {e}")
return None
# 使用示例
save_config(user_config)
loaded_config = load_config()
if loaded_config:
print(f"数据库主机: {loaded_config['database']['host']}")
🎯 高级技巧:自定义序列化
Pythonimport json
from datetime import datetime, date
from decimal import Decimal
class CustomJSONEncoder(json.JSONEncoder):
"""自定义JSON编码器,处理特殊数据类型"""
def default(self, obj):
if isinstance(obj, datetime):
return obj.strftime('%Y-%m-%d %H:%M:%S')
elif isinstance(obj, date):
return obj.strftime('%Y-%m-%d')
elif isinstance(obj, Decimal):
return float(obj)
elif hasattr(obj, '__dict__'):
# 处理自定义对象
return obj.__dict__
return super().default(obj)
# 示例:处理复杂数据类型
class User:
def __init__(self, name, email, created_at):
self.name = name
self.email = email
self.created_at = created_at
self.balance = Decimal('1000.50')
# 创建测试数据
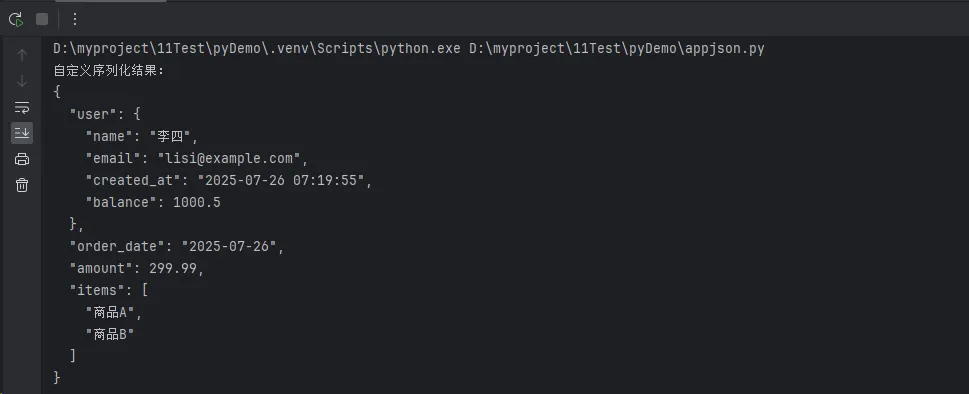
user = User("李四", "lisi@example.com", datetime.now())
order_data = {
"user": user,
"order_date": date.today(),
"amount": Decimal('299.99'),
"items": ["商品A", "商品B"]
}
# 使用自定义编码器
json_result = json.dumps(order_data, cls=CustomJSONEncoder,
ensure_ascii=False, indent=2)
print("自定义序列化结果:")
print(json_result)
🛡️ 异常处理与数据验证
Pythonimport json
from typing import Dict, Any, Optional
class JSONProcessor:
"""JSON数据处理器,包含完整的异常处理"""
@staticmethod
def safe_loads(json_str: str) -> Optional[Dict[Any, Any]]:
"""安全的JSON解析,包含异常处理"""
try:
if not json_str or not json_str.strip():
print("警告: JSON字符串为空")
return None
result = json.loads(json_str)
return result
except json.JSONDecodeError as e:
print(f"JSON格式错误: {e}")
print(f"错误位置: 行{e.lineno}, 列{e.colno}")
return None
except Exception as e:
print(f"解析过程中发生未知错误: {e}")
return None
@staticmethod
def validate_required_fields(data: dict, required_fields: list) -> bool:
"""验证必需字段是否存在"""
missing_fields = []
for field in required_fields:
if field not in data or data[field] is None:
missing_fields.append(field)
if missing_fields:
print(f"缺少必需字段: {missing_fields}")
return False
return True
@staticmethod
def extract_nested_value(data: dict, path: str, default=None):
"""安全提取嵌套字典中的值"""
keys = path.split('.')
current = data
try:
for key in keys:
if isinstance(current, dict) and key in current:
current = current[key]
else:
return default
return current
except Exception:
return default
# 使用示例
processor = JSONProcessor()
# 测试数据
test_json = '''
{
"user": {
"profile": {
"name": "王五",
"email": "wangwu@example.com"
},
"settings": {
"theme": "dark",
"language": "zh-CN"
}
},
"timestamp": "2024-07-25 10:30:00"
}
'''
# 安全解析
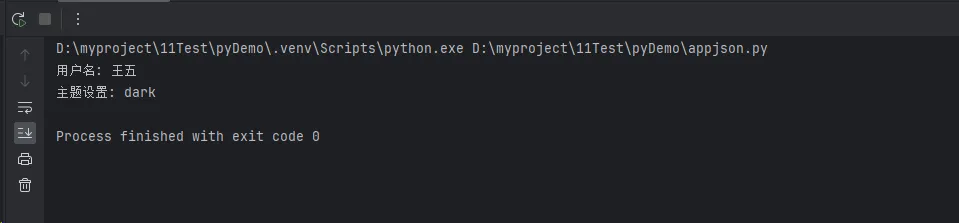
data = processor.safe_loads(test_json)
if data:
# 验证必需字段
if processor.validate_required_fields(data, ['user', 'timestamp']):
# 安全提取嵌套值
user_name = processor.extract_nested_value(data, 'user.profile.name', '未知用户')
theme = processor.extract_nested_value(data, 'user.settings.theme', 'light')
print(f"用户名: {user_name}")
print(f"主题设置: {theme}")
🔧 性能优化:处理大型JSON数据
Pythonimport json
import time
from typing import Generator, Dict, Any
class PerformantJSONHandler:
"""高性能JSON处理器"""
@staticmethod
def stream_json_array(file_path: str) -> Generator[Dict[Any, Any], None, None]:
"""流式处理大型JSON数组,避免内存溢出"""
with open(file_path, 'r', encoding='utf-8') as f:
# 跳过开头的 '['
f.read(1)
buffer = ""
bracket_count = 0
in_string = False
escape_next = False
for char in f.read():
if char == '"' and not escape_next:
in_string = not in_string
elif not in_string:
if char == '{':
bracket_count += 1
elif char == '}':
bracket_count -= 1
escape_next = (char == '\\' and not escape_next)
if char != ',' or bracket_count > 0 or in_string:
buffer += char
# 当找到完整的JSON对象时
if bracket_count == 0 and buffer.strip() and not in_string:
try:
obj = json.loads(buffer.strip().rstrip(','))
yield obj
buffer = ""
except json.JSONDecodeError:
continue
@staticmethod
def batch_process_json(data_list: list, batch_size: int = 1000):
"""批量处理JSON数据"""
for i in range(0, len(data_list), batch_size):
batch = data_list[i:i + batch_size]
yield batch
@staticmethod
def benchmark_json_operations():
"""JSON操作性能测试"""
# 生成测试数据
test_data = [
{"id": i, "name": f"用户{i}", "score": i * 10}
for i in range(10000)
]
# 测试序列化性能
start_time = time.time()
json_str = json.dumps(test_data, ensure_ascii=False)
serialize_time = time.time() - start_time
# 测试反序列化性能
start_time = time.time()
parsed_data = json.loads(json_str)
deserialize_time = time.time() - start_time
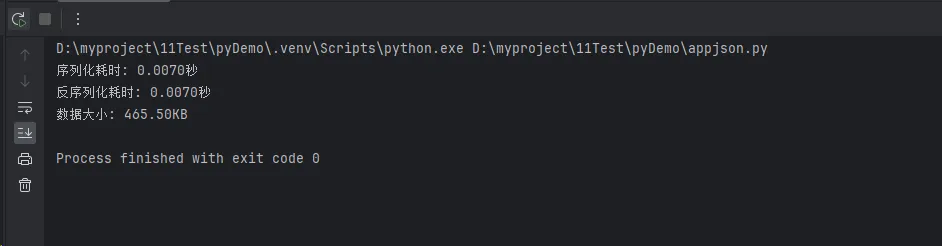
print(f"序列化耗时: {serialize_time:.4f}秒")
print(f"反序列化耗时: {deserialize_time:.4f}秒")
print(f"数据大小: {len(json_str) / 1024:.2f}KB")
# 性能测试
handler = PerformantJSONHandler()
handler.benchmark_json_operations()
🎨 实用工具函数
Pythonimport json
from pathlib import Path
from typing import Union, Any, Dict
class JSONUtils:
"""JSON处理实用工具集"""
@staticmethod
def pretty_print(data: Union[dict, list, str], indent: int = 2):
"""美化打印JSON数据"""
if isinstance(data, str):
try:
data = json.loads(data)
except json.JSONDecodeError:
print("无效的JSON字符串")
return
print(json.dumps(data, ensure_ascii=False, indent=indent))
@staticmethod
def compare_json(json1: dict, json2: dict) -> Dict[str, Any]:
"""比较两个JSON对象的差异"""
def _compare_recursive(obj1, obj2, path=""):
differences = []
if type(obj1) != type(obj2):
differences.append({
"path": path,
"type": "type_mismatch",
"value1": type(obj1).__name__,
"value2": type(obj2).__name__
})
return differences
if isinstance(obj1, dict):
all_keys = set(obj1.keys()) | set(obj2.keys())
for key in all_keys:
current_path = f"{path}.{key}" if path else key
if key not in obj1:
differences.append({
"path": current_path,
"type": "missing_in_first",
"value": obj2[key]
})
elif key not in obj2:
differences.append({
"path": current_path,
"type": "missing_in_second",
"value": obj1[key]
})
else:
differences.extend(_compare_recursive(
obj1[key], obj2[key], current_path
))
elif isinstance(obj1, list):
if len(obj1) != len(obj2):
differences.append({
"path": path,
"type": "length_mismatch",
"value1": len(obj1),
"value2": len(obj2)
})
for i, (item1, item2) in enumerate(zip(obj1, obj2)):
differences.extend(_compare_recursive(
item1, item2, f"{path}[{i}]"
))
elif obj1 != obj2:
differences.append({
"path": path,
"type": "value_mismatch",
"value1": obj1,
"value2": obj2
})
return differences
return {
"differences": _compare_recursive(json1, json2),
"identical": len(_compare_recursive(json1, json2)) == 0
}
@staticmethod
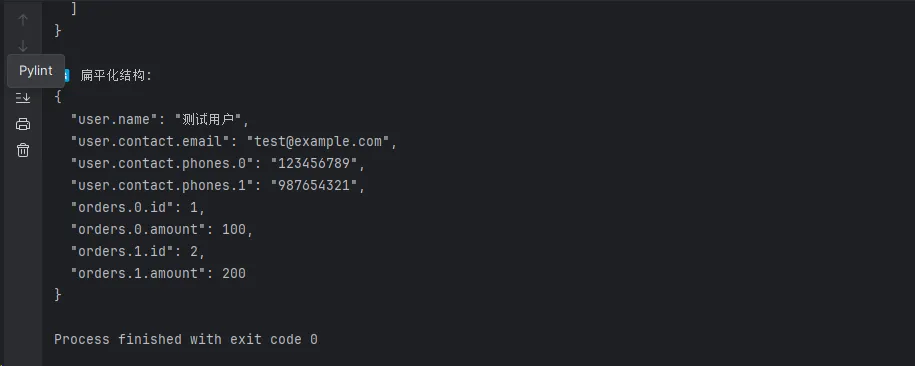
def flatten_json(data: dict, separator: str = '.') -> dict:
"""将嵌套的JSON结构扁平化"""
def _flatten(obj, parent_key=''):
items = []
if isinstance(obj, dict):
for k, v in obj.items():
new_key = f"{parent_key}{separator}{k}" if parent_key else k
items.extend(_flatten(v, new_key).items())
elif isinstance(obj, list):
for i, v in enumerate(obj):
new_key = f"{parent_key}{separator}{i}" if parent_key else str(i)
items.extend(_flatten(v, new_key).items())
else:
return {parent_key: obj}
return dict(items)
return _flatten(data)
# 工具函数使用示例
utils = JSONUtils()
# 示例数据
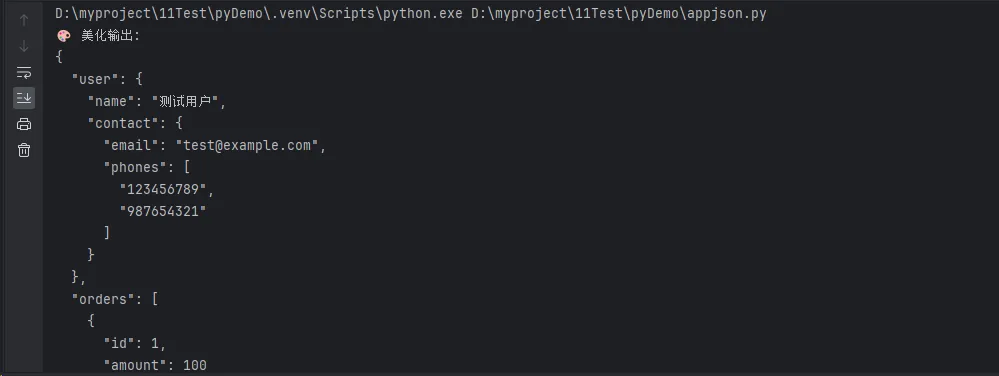
sample_data = {
"user": {
"name": "测试用户",
"contact": {
"email": "test@example.com",
"phones": ["123456789", "987654321"]
}
},
"orders": [
{"id": 1, "amount": 100},
{"id": 2, "amount": 200}
]
}
print("🎨 美化输出:")
utils.pretty_print(sample_data)
print("\n🔄 扁平化结构:")
flattened = utils.flatten_json(sample_data)
utils.pretty_print(flattened)
🎯 总结:掌握JSON处理的三个关键要点
通过本文的深入讲解和实战演练,相信你已经对Python JSON数据处理有了全面的认识。让我们来总结一下核心要点:
1. 基础扎实是关键 - 熟练掌握json模块的四个核心方法,理解Python数据类型与JSON格式的映射关系,这是所有高级应用的基础。
2. 异常处理不可少 - 在实际项目中,JSON数据来源复杂多样,完善的异常处理机制能让你的代码更加稳定可靠,避免因数据问题导致程序崩溃。
3. 性能优化要重视 - 面对大量JSON数据时,合理的处理策略和性能优化技巧能显著提升程序效率,这在企业级应用中尤为重要。
在Python开发的道路上,JSON数据处理能力将伴随你处理各种复杂的业务场景。建议你将本文的代码示例保存下来,在实际项目中反复实践,相信你很快就能成为JSON数据处理的专家!
💡 延伸学习建议:深入了解Python的ujson库可以获得更好的性能表现,学习jsonschema库可以进行JSON数据验证,这些都是提升Python开发技能的重要补充。
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录