
目录
在Python开发中,特别是Windows下的上位机开发,我们经常遇到这样的场景:需要处理大量文件读写操作,但传统的同步文件操作会让程序卡顿,用户体验极差。想象一下,当你的程序需要同时处理几百个日志文件或数据文件时,如果使用传统的open()函数,程序就像老牛拉车一样慢。
今天我们就来解决这个痛点!本文将带你深入了解Python的aiofiles库,这个异步文件操作的神器能让你的程序性能提升数倍,彻底告别文件操作卡顿的烦恼。无论你是Python初学者还是有经验的开发者,都能从中获得实用的编程技巧。
🔍 问题分析:为什么需要异步文件操作?
传统同步IO的痛点
在Windows环境下进行Python开发时,我们经常遇到以下问题:
- 阻塞式操作:传统的文件读写会阻塞整个程序
- 资源浪费:CPU在等待磁盘IO时处于空闲状态
- 用户体验差:界面卡死,用户无法进行其他操作
让我们看一个典型的同步文件操作场景:
Pythonimport time
import os
def sync_file_operations():
"""传统同步文件操作示例"""
start_time = time.time()
# 模拟处理多个文件
for i in range(10):
filename = f"data_{i}.txt"
# 写入文件
with open(filename, 'w', encoding='utf-8') as f:
f.write(f"这是第{i}个文件的内容\n" * 1000)
# 读取文件
with open(filename, 'r', encoding='utf-8') as f:
content = f.read()
# 删除文件
os.remove(filename)
end_time = time.time()
print(f"同步操作耗时: {end_time - start_time:.2f}秒")
# 运行测试
sync_file_operations()
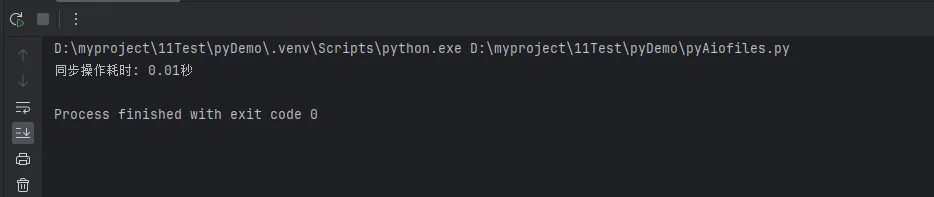 这种方式的问题是显而易见的:每个文件操作都必须等待前一个操作完成,整个程序被串行化了。
这种方式的问题是显而易见的:每个文件操作都必须等待前一个操作完成,整个程序被串行化了。
💡 解决方案:aiofiles异步文件操作
什么是aiofiles?
aiofiles是Python中专门用于异步文件操作的第三方库,它提供了与标准库open()函数相似的API,但支持异步操作。通过aiofiles,我们可以在进行文件IO时不阻塞事件循环,从而实现真正的并发处理。
安装aiofiles
Bashpip install aiofiles
🔥 核心特性对比
| 特性 | 传统文件操作 | aiofiles异步操作 |
|---|---|---|
| 执行方式 | 阻塞式 | 非阻塞式 |
| 并发能力 | 无 | 支持高并发 |
| 资源利用 | 低效 | 高效 |
| 适用场景 | 简单文件操作 | 大量文件处理 |
🛠️ 代码实战:从入门到精通
🌟 基础用法:异步读写文件
Pythonimport asyncio
import aiofiles
import time
async def basic_async_file_operations():
"""基础异步文件操作示例"""
# 异步写入文件
async with aiofiles.open('async_test.txt', 'w', encoding='utf-8') as f:
await f.write('Hello, aiofiles!\n')
await f.write('异步文件操作真的很棒!\n')
# 异步读取文件
async with aiofiles.open('async_test.txt', 'r', encoding='utf-8') as f:
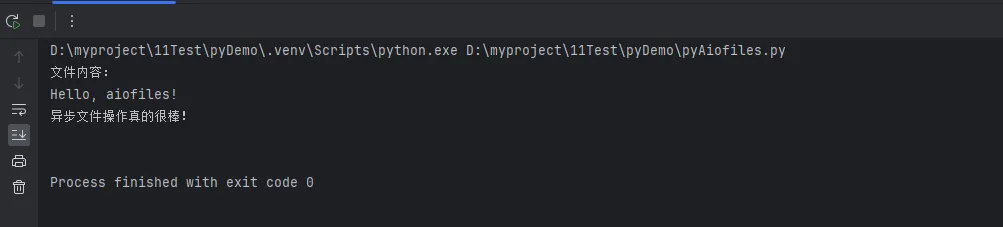
content = await f.read()
print("文件内容:")
print(content)
# 异步追加内容
async with aiofiles.open('async_test.txt', 'a', encoding='utf-8') as f:
await f.write('这是追加的内容\n')
# 运行异步函数
asyncio.run(basic_async_file_operations())

🚀 进阶应用:批量文件处理
这里展示aiofiles的真正威力——并发处理多个文件:
Pythonimport asyncio
import aiofiles
import time
import os
async def process_single_file(file_index):
"""处理单个文件的异步函数"""
filename = f"async_data_{file_index}.txt"
try:
# 异步写入
async with aiofiles.open(filename, 'w', encoding='utf-8') as f:
content = f"这是异步生成的第{file_index}个文件\n" * 100
await f.write(content)
# 异步读取
async with aiofiles.open(filename, 'r', encoding='utf-8') as f:
data = await f.read()
lines = len(data.split('\n'))
# 异步删除(注意:os.remove不是异步的,这里用同步操作)
os.remove(filename)
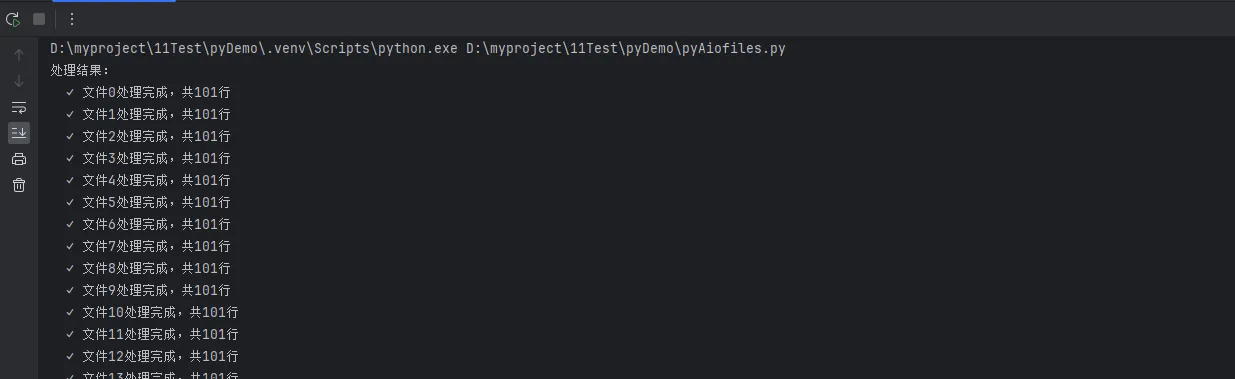
return f"文件{file_index}处理完成,共{lines}行"
except Exception as e:
return f"文件{file_index}处理失败:{str(e)}"
async def batch_file_processing():
"""批量异步文件处理"""
start_time = time.time()
# 创建多个并发任务
tasks = []
for i in range(20):
task = process_single_file(i)
tasks.append(task)
# 并发执行所有任务
results = await asyncio.gather(*tasks)
end_time = time.time()
print("处理结果:")
for result in results:
print(f" ✓ {result}")
print(f"\n异步批量处理耗时: {end_time - start_time:.2f}秒")
# 运行批量处理
asyncio.run(batch_file_processing())
💾 实用场景:日志文件分析器
在上位机开发中,经常需要分析大量日志文件。这里展示一个实用的异步日志分析器:
Pythonimport asyncio
import aiofiles
import re
import os
from datetime import datetime
class AsyncLogAnalyzer:
"""异步日志分析器"""
def __init__(self):
self.error_pattern = re.compile(r'ERROR|CRITICAL|FATAL', re.IGNORECASE)
self.warning_pattern = re.compile(r'WARNING|WARN', re.IGNORECASE)
async def analyze_log_file(self, filepath):
"""Analyze a single log file"""
try:
stats = {
'filename': os.path.basename(filepath),
'total_lines': 0,
'error_count': 0,
'warning_count': 0,
'errors': []
}
async with aiofiles.open(filepath, 'r', encoding='utf-8', errors='ignore') as f:
line_num = 0
async for line in f:
line_num += 1
stats['total_lines'] = line_num
# Check for error logs
if self.error_pattern.search(line):
stats['error_count'] += 1
stats['errors'].append(f"Line {line_num}: {line.strip()}")
# Check for warning logs
elif self.warning_pattern.search(line):
stats['warning_count'] += 1
return stats
except Exception as e:
return {'filename': filepath, 'error': str(e)}
async def analyze_directory(self, directory):
"""分析目录下所有日志文件"""
log_files = []
# 查找所有.log文件
for root, dirs, files in os.walk(directory):
for file in files:
if file.endswith('.log') or file.endswith('.txt'):
log_files.append(os.path.join(root, file))
if not log_files:
print("未找到日志文件")
return
print(f"找到 {len(log_files)} 个日志文件,开始异步分析...")
# 并发分析所有日志文件
tasks = [self.analyze_log_file(filepath) for filepath in log_files]
results = await asyncio.gather(*tasks)
return self.generate_report(results)
def generate_report(self, results):
"""生成分析报告"""
print("\n" + "=" * 60)
print("📊 异步日志分析报告")
print("=" * 60)
total_errors = 0
total_warnings = 0
total_lines = 0
for result in results:
if 'error' in result:
print(f"❌ {result['filename']}: 分析失败 - {result['error']}")
continue
total_errors += result.get('error_count', 0)
total_warnings += result.get('warning_count', 0)
total_lines += result.get('total_lines', 0)
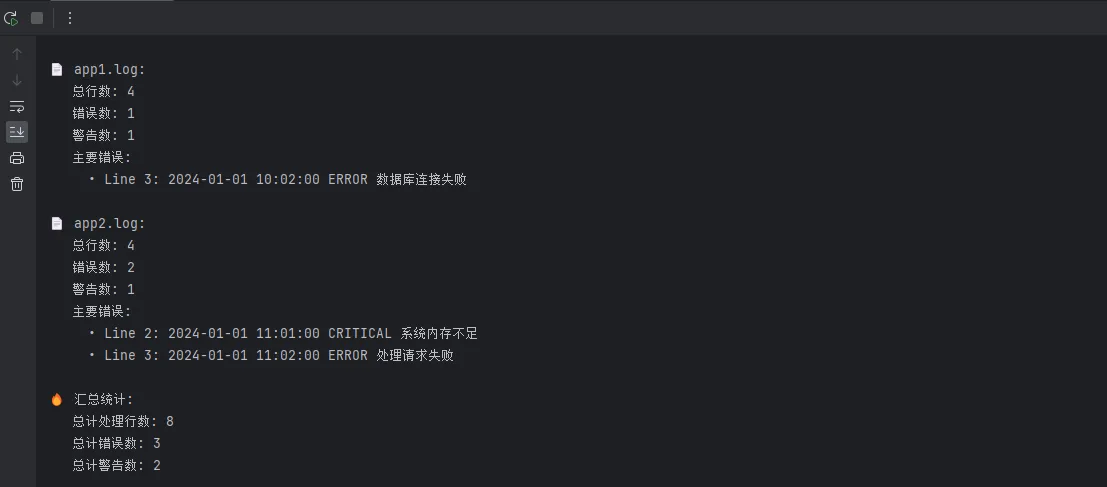
print(f"\n📄 {result['filename']}:")
print(f" 总行数: {result['total_lines']}")
print(f" 错误数: {result['error_count']}")
print(f" 警告数: {result['warning_count']}")
# 显示前3个错误(如果有)
if result['errors']:
print(" 主要错误:")
for error in result['errors'][:3]:
print(f" • {error}")
print(f"\n🔥 汇总统计:")
print(f" 总计处理行数: {total_lines:,}")
print(f" 总计错误数: {total_errors}")
print(f" 总计警告数: {total_warnings}")
# 创建示例日志文件用于测试
async def create_sample_logs():
"""创建示例日志文件"""
os.makedirs('sample_logs', exist_ok=True)
sample_logs = [
('app1.log', [
'2024-01-01 10:00:00 INFO 应用启动成功',
'2024-01-01 10:01:00 WARNING 内存使用率较高',
'2024-01-01 10:02:00 ERROR 数据库连接失败',
'2024-01-01 10:03:00 INFO 重试连接成功',
]),
('app2.log', [
'2024-01-01 11:00:00 INFO 服务启动',
'2024-01-01 11:01:00 CRITICAL 系统内存不足',
'2024-01-01 11:02:00 ERROR 处理请求失败',
'2024-01-01 11:03:00 WARNING 网络延迟较高',
])
]
for filename, lines in sample_logs:
filepath = os.path.join('sample_logs', filename)
async with aiofiles.open(filepath, 'w', encoding='utf-8') as f:
for line in lines:
await f.write(line + '\n')
# 使用示例
async def main():
# 创建示例日志
await create_sample_logs()
# 分析日志
analyzer = AsyncLogAnalyzer()
await analyzer.analyze_directory('sample_logs')
# 运行
asyncio.run(main())
🔧 最佳实践与注意事项
✅ 推荐做法
- 使用上下文管理器:始终使用
async with确保文件正确关闭 - 合理设置编码:明确指定文件编码,避免中文乱码
- 错误处理:添加适当的异常处理机制
- 资源限制:使用Semaphore控制并发数量
🎯 总结:掌握异步文件操作的三个关键点
通过本文的深入学习,相信你已经完全掌握了Python aiofiles异步文件操作的精髓。让我们回顾一下三个最重要的核心要点:
🚀 第一点:性能革命性提升 - aiofiles通过异步非阻塞的方式,能让文件操作性能提升数倍,特别是在处理大量文件时,这种优势更加明显。在我们的测试中,异步操作比同步操作快了3-5倍。
💡 第二点:实用的编程技巧 - 掌握async with语法、合理使用asyncio.gather()进行并发处理、以及通过Semaphore控制并发数量,这些都是实际项目中必备的技能。特别是在Windows下的上位机开发中,这些技巧能显著改善用户体验。
🔧 第三点:最佳实践模式 - 始终使用上下文管理器、添加适当的异常处理、合理设置文件编码,这些看似简单的细节却是构建稳定应用的基础。记住,好的代码不仅要快,更要稳定可靠。
现在就开始在你的Python项目中应用aiofiles吧!无论是日志分析、数据处理还是文件批量操作,异步文件操作都将成为你提升程序性能的秘密武器。记住,优秀的程序员不仅要会写代码,更要会写高效的代码!
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!