
工业场景下的数据可视化跟普通图表完全不是一回事儿。你得考虑大数据量下的流畅度、实时更新的响应速度、多曲线对比的清晰度,还有各种工业协议的数据适配。如果技术选型没做好,后期优化会让你焦头烂额。
读完这篇文章,你将掌握:
- ScottPlot 5.0 在 WPF 中的快速集成方法
- 3 种不同复杂度的折线图实现方案(从基础到工业级)
- 实时数据更新的性能优化技巧(含真实对比数据)
- 多曲线管理与交互设计的最佳实践
咱们直接进入正题,先聊聊为啥工业图表这么难搞。
💔 问题深度剖析:工业图表的三大痛点
痛点一:性能瓶颈
在实际项目中,遇到最多的问题就是数据量爆炸。工业设备每秒采集 10-100 个数据点很正常,24 小时运行下来就是几百万数据。很多开发者会直接把所有数据都绘制出来,结果内存占用飙升到几个 GB,UI 线程直接卡死。
痛点二:交互体验差
工业场景对交互有特殊要求:
- 工程师需要精确读取某个时间点的数值(鼠标悬停显示坐标)
- 要能快速缩放到某个时间段(鼠标滚轮 + 拖拽)
- 多曲线对比时需要独立控制显示/隐藏
- 异常数据要能一眼看出来(高亮 + 标注)
这些功能如果自己实现,代码量轻松破千行,而且性能优化是个大坑。
痛点三:数据适配复杂
工业数据源五花八门:OPC UA、Modbus、数据库历史数据、实时流数据... 每种数据源的时间戳格式、数据类型、采样频率都不一样。如何设计一套通用的数据适配层,既能复用代码又能保证性能,是个技术活儿。
💡 核心要点:为什么选择 ScottPlot 5.0?
在尝试过几种图表库后(OxyPlot、LiveCharts、SciChart 等),我最终选择了 ScottPlot 5.0,原因有三个:
⚡ 性能强悍
ScottPlot 底层使用 SkiaSharp 进行硬件加速渲染,对大数据量做了专门优化:
- 百万级数据点的渲染时间在 50ms 以内
- 内存占用比传统 WPF 控件低 60%
- 支持数据抽稀算法,自动根据屏幕分辨率减少渲染点数
- 开源免费!!!
🎨 API 设计友好
csharp// 添加一条折线,就这么简单
var signal = myPlot.Add.Signal(yValues);
signal.Color = Colors.Blue;
myPlot. Refresh();
对比 OxyPlot 需要创建 Model → Series → Points 的繁琐流程,ScottPlot 的链式调用简直不要太爽。
🛠️ 工业级功能齐全
- 内置十几种曲线类型(Signal、Scatter、Step、Bar 等)
- 坐标轴支持时间戳、对数、自定义格式
- 交互式图例、鼠标追踪、缩放平移开箱即用
- 关键是完全免费开源,商业项目也能放心用
🚀 解决方案:从入门到工业级的三个阶段
📌 方案一:5 分钟快速入门(静态折线图)
适用场景
适合展示历史数据分析,数据量在万级以内,不需要频繁更新。比如:
- 生产日报的温度曲线
- 设备巡检记录的振动趋势
- 质量检测的测量值分布
完整代码实现
csharppublic partial class MainWindow : Window
{
public MainWindow()
{
InitializeComponent();
LoadBasicLineChart();
}
private void LoadBasicLineChart()
{
wpfPlot1.Plot.Font.Set("Microsoft YaHei");
wpfPlot1.Plot.Axes.Bottom.Label.FontName = "Microsoft YaHei";
wpfPlot1.Plot.Axes.Left.Label.FontName = "Microsoft YaHei";
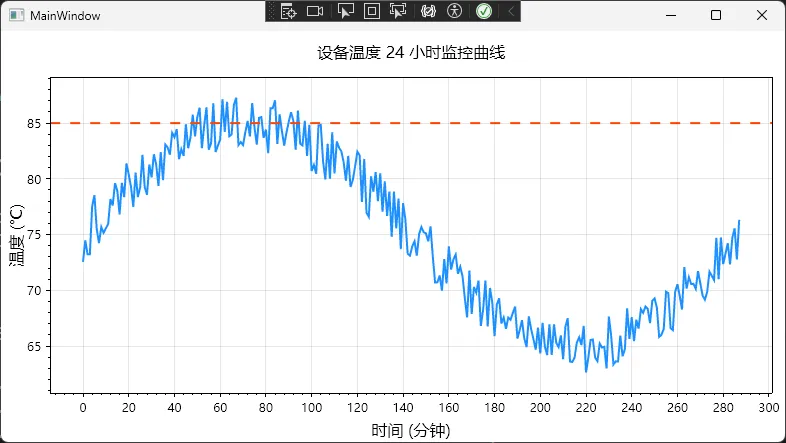
// 1. 模拟工业数据:某设备 24 小时的温度记录
double[] temperatures = GenerateTemperatureData(288); // 每 5 分钟一个点
double[] timePoints = Generate.Consecutive(288);
// 2. 创建折线图
var linePlot = wpfPlot1.Plot.Add.Scatter(timePoints, temperatures);
linePlot.LineWidth = 2;
linePlot.Color = ScottPlot.Color.FromHex("#1E90FF");
linePlot.MarkerSize = 0; // 不显示数据点标记
// 3. 配置坐标轴
wpfPlot1.Plot.Axes.Bottom.Label.Text = "时间 (分钟)";
wpfPlot1.Plot.Axes.Left.Label.Text = "温度 (℃)";
wpfPlot1.Plot.Title("设备温度 24 小时监控曲线");
// 4. 添加警戒线(工业场景常用)
var warningLine = wpfPlot1.Plot.Add.HorizontalLine(85);
warningLine.LineWidth = 2;
warningLine.Color = ScottPlot.Color.FromHex("#FF4500");
warningLine.LinePattern = LinePattern.Dashed;
// 5. 自动调整视图范围
wpfPlot1.Plot.Axes.AutoScale();
wpfPlot1.Refresh();
}
// 模拟真实温度波动(基准值 + 随机噪声 + 周期性变化)
private double[] GenerateTemperatureData(int count)
{
double[] data = new double[count];
Random rand = new Random();
for (int i = 0; i < count; i++)
{
double baseline = 75; // 基准温度
double noise = rand.NextDouble() * 5 - 2.5; // ±2.5℃ 随机波动
double cycle = 10 * Math.Sin(2 * Math.PI * i / 288); // 周期性变化
data[i] = baseline + noise + cycle;
}
return data;
}
}
XAML 配置
xml<Window x:Class="AppScottPlot1.MainWindow"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:d="http://schemas.microsoft.com/expression/blend/2008"
xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006"
xmlns:local="clr-namespace:AppScottPlot1"
mc:Ignorable="d"
xmlns:ScottPlot="clr-namespace:ScottPlot.WPF;assembly=ScottPlot.WPF"
Title="MainWindow" Height="450" Width="800">
<Grid>
<ScottPlot:WpfPlot Name="wpfPlot1" />
</Grid>
</Window>
在工业4.0浪潮下,你是否还在为每个新项目重复编写Modbus通信代码而头疼?是否因为硬编码的寄存器配置而在客户现场手忙脚乱地修改代码?
作为一名在工业自动化领域摸爬滚打多年的C#开发者,我深知这些痛点。今天分享一套配置驱动的Modbus插件系统,让你彻底告别重复造轮子,通过JSON配置文件即可适配不同设备,真正做到"一次开发,处处复用"!
🎯 痛点分析:为什么需要插件化Modbus系统
传统开发的三大痛点
痛点1:硬编码灾难
c#// 传统写法 - 每个项目都要重写
var temperature = master.ReadHoldingRegisters(1, 40001, 2);
float temp = ConvertToFloat(temperature); // 又要写转换逻辑
痛点2:设备适配困难
- 客户A的温度传感器地址是40001,16位整数,需要除以10
- 客户B的温度传感器地址是30005,32位浮点数,大端字节序
- 每次都要修改源码,测试,打包,部署...
痛点3:维护成本高昂
- 一个工厂几十台设备,每台配置都不同
- 现场调试时发现地址配错,程序员要连夜改代码
- 代码与配置耦合,难以复用
💡 解决方案:JSON配置 + 自动功能码映射
核心设计理念
- 配置驱动:所有设备参数通过JSON配置,无需修改代码
- 智能映射:读功能码自动映射为对应写功能码
- 类型安全:支持多种数据类型和字节序转换
- 事件驱动:实时数据变化通知
🔧 代码实战:搭建完整插件系统
第一步:定义数据模型
c#using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Newtonsoft.Json;
namespace AppModbusPlugin.Models
{
public class ModbusConfiguration
{
[JsonProperty("modbusConfig")]
public ModbusConfig ModbusConfig { get; set; }
}
public class ModbusConfig
{
[JsonProperty("connectionSettings")]
public ConnectionSettings ConnectionSettings { get; set; }
[JsonProperty("registers")]
public List<ModbusRegister> Registers { get; set; } = new List<ModbusRegister>();
}
public class ConnectionSettings
{
[JsonProperty("type")]
public string Type { get; set; } // TCP, RTU, ASCII
[JsonProperty("host")]
public string Host { get; set; }
[JsonProperty("port")]
public int Port { get; set; } = 502;
[JsonProperty("slaveId")]
public byte SlaveId { get; set; } = 1;
[JsonProperty("timeout")]
public int Timeout { get; set; } = 3000;
[JsonProperty("retries")]
public int Retries { get; set; } = 3;
[JsonProperty("serialPort")]
public string SerialPort { get; set; }
[JsonProperty("baudRate")]
public int BaudRate { get; set; } = 9600;
[JsonProperty("parity")]
public string Parity { get; set; } = "None";
[JsonProperty("dataBits")]
public int DataBits { get; set; } = 8;
[JsonProperty("stopBits")]
public int StopBits { get; set; } = 1;
}
public class ModbusRegister
{
[JsonProperty("name")]
public string Name { get; set; }
[JsonProperty("address")]
public int Address { get; set; }
[JsonProperty("functionCode")]
public int FunctionCode { get; set; }
[JsonProperty("dataType")]
public string DataType { get; set; }
[JsonProperty("byteOrder")]
public string ByteOrder { get; set; } = "AB";
[JsonProperty("length")]
public int Length { get; set; } = 1;
[JsonProperty("scale")]
public double Scale { get; set; } = 1.0;
[JsonProperty("offset")]
public double Offset { get; set; } = 0.0;
[JsonProperty("unit")]
public string Unit { get; set; }
[JsonProperty("readOnly")]
public bool ReadOnly { get; set; } = true;
[JsonProperty("description")]
public string Description { get; set; }
}
}
你是否曾经为开发复杂的工业自动化界面而头疼?传统的WinForms控件在面对实时动画、物理模拟和复杂图形渲染时显得力不从心。想要实现流畅的传送带动画、精确的机械臂控制,还要保证系统的响应性和稳定性,这些挑战让许多C#开发者望而却步。
本文将通过一个完整的工业自动化模拟系统案例,手把手教你使用SkiaSharp + WinForms构建高性能的2D动画引擎。你将学会如何优雅地处理实时渲染、状态管理、物理模拟等核心技术问题,最终掌握工业级界面开发的核心技能,当然这就是一个简单的仿真。
🎯 核心技术架构分析
📊 系统架构设计
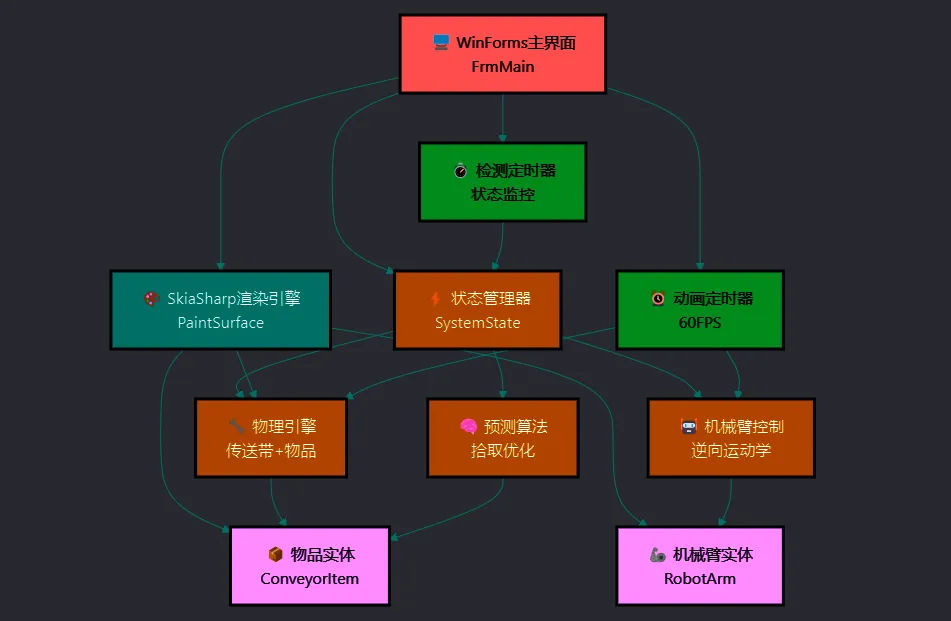
现代工业界面开发面临三大核心挑战:性能瓶颈、状态复杂性和渲染效率。传统的控件绘制方式无法满足实时动画的需求,我们需要一套全新的解决方案。
c#// 🔥 核心渲染引擎设计
public partial class FrmMain : Form
{
// 分离关注点:状态管理
private SystemState currentState = SystemState.Idle;
private LightStatus currentLight = LightStatus.Gray;
// 物理引擎:传送带系统
private float conveyorSpeed = 20.0f;
private float conveyorAcceleration = 10.0f;
private float currentSpeed = 0.0f;
// 实体管理:对象池模式
private List<ConveyorItem> items = new List<ConveyorItem>();
// 智能控制:预测算法
private readonly float PICKUP_TIME_ESTIMATE = 2.0f;
private readonly float DETECTION_TO_PICKUP_DISTANCE = 120.0f;
}
作为一名C#开发者,你是否还在为WinForms的绘制性能和过时的API而烦恼?当你尝试使用最新版SkiaSharp时,是否遇到了DrawText方法过期的警告?别担心,今天我将手把手教你如何用现代化的SkiaSharp API构建一个完整的2D游戏精灵引擎,不仅解决API过期问题,还能完美支持中文显示!
这不仅仅是一次API升级,更是一次性能革命。我们将从零开始构建一个包含碰撞检测、动画系统和精灵管理的完整游戏引擎,让你的WinForms应用焕发新生。
🔥 痛点分析:老旧API的困扰
常见问题清单
在使用SkiaSharp进行WinForms开发时,开发者经常遇到这些问题:
- API过期警告:
SKCanvas.DrawText(string, float, float, SKPaint)方法被标记为过期 - 中文显示异常:默认字体无法正确渲染中文字符
- 性能瓶颈:频繁的对象创建导致GC压力
- 资源泄漏:SkiaSharp对象未正确释放
核心问题
最大的痛点在于:新版SkiaSharp要求使用SKFont对象,而不是直接在SKPaint中设置字体属性。
🚩 整体架构
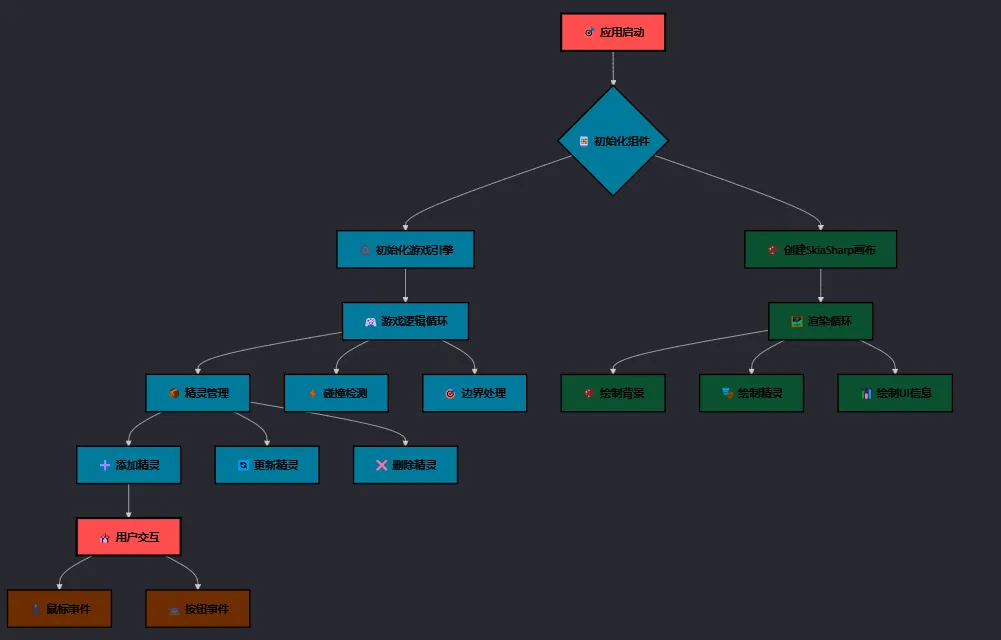
💡 现代化解决方案
🎯 新API使用模式
c#// ❌ 过期写法
canvas.DrawText("Hello World", 10, 30, paint);
// ✅ 现代写法
var font = new SKFont(typeface, 16);
canvas.DrawText("Hello World", 10, 30, SKTextAlign.Left, font, paint);
过期的方法不少。。。
🚀 完整的字体管理方案
c#private void InitializeFontsAndPaints()
{
// 创建支持中文的字体 - 多层备用方案
var typeface = SKTypeface.FromFamilyName("Microsoft YaHei",
SKFontStyleWeight.Normal, SKFontStyleWidth.Normal, SKFontStyleSlant.Upright)
?? SKTypeface.FromFamilyName("SimHei")
?? SKTypeface.FromFamilyName("Arial Unicode MS")
?? SKTypeface.Default;
infoFont = new SKFont(typeface, 16);
infoPaint = new SKPaint
{
Color = SKColors.White,
IsAntialias = true,
FilterQuality = SKFilterQuality.High // 高质量渲染
};
}
兄弟们,做工控上位机(HMI),最怕的不是逻辑复杂,而是“乱”。
很多刚转行做工控的 C# 兄弟,还在用写 WinForms 小工具的思维:拖一个 Button,双击,在 Click 事件里写 PLC 通讯、写数据库、写界面刷新。几千行代码塞在一个 Form.cs 里,这种“面条代码”维护起来简直是火葬场级别的难度。
读完这篇文章,你能带走什么?
- 彻底搞懂为什么你的界面会卡顿(以及怎么治)。
- 学会一套“能抗事儿”**的分层架构,让你的代码像德系机床一样精密。
- 拿到一份可落地的异步通信代码模板,直接提升采集性能。
💡 一、 为什么你的 HMI 项目总是“烂尾”?
咱们剖析一下,为什么很多上位机项目做着做着就没法维护了?
1. 致命的“UI 线程依赖症”
在 Button_Click 里直接调用 PLC.Read()?这是新手最爱犯的错。PLC 通讯是 I/O 操作,网络稍微抖一下,超时个 500ms,你的界面就得假死半秒。由于工控现场电磁环境复杂,通讯超时是家常便饭,界面卡顿也就成了常态。
2. 逻辑与界面的“连体婴”
我在很多项目里看到,业务逻辑直接操作 textBox1.Text。
如果有一天,客户说:“老李,这个文本框太丑了,换成仪表盘控件。”
完了,你得去业务逻辑代码里,把所有 textBox1.Text = ... 改成 gauge1.Value = ...。这种紧耦合,是维护成本爆炸的根源。
3. 缺乏“工程化”思维
没有日志分级、没有全局异常捕获、配置参数写死在代码里。这种软件在开发机上跑得飞起,一到现场,面对 24x7 的高强度运行,立马现原形。
🔑 二、 核心要点:给代码立规矩
想翻身,得讲究战术。在 C# 开发 HMI 时,有三个铁律必须遵守:
- UI 只是“皮囊”,数据才是“灵魂”:无论你用 WinForms 还是 WPF,界面只负责显示数据。数据变了,界面跟着变;而不是界面去驱动数据。
- 通信必须异步:PLC 采集、数据库读写,必须扔到后台线程去干。UI 线程只负责貌美如花。
- 万物皆对象:把 PLC 看作一个对象,把产线上的一个工位看作一个对象。不要面向过程写代码。
🛠️ 三、 解决方案:从架构到落地的三板斧
接下来,咱们上干货。针对上面提到的痛点,我给出一套我在多个千万级项目中验证过的解决方案。
方案 1:解耦神器 —— 简易版 MVVM(适配 WinForms/WPF)
虽然 MVVM 是 WPF 的标配,但其核心思想在 WinForms 里照样好使。我们要做的,是把界面(View)和逻辑(ViewModel)彻底分开。
实际上WPF这块优势明显,Winform这块实现麻烦一些。