
说实话,刚接触WinForms开发的时候,我对Application类的理解特别浅显——不就是个Application.Run(new Form1())吗?直到有一次,客户反馈说程序启动后有时会出现两个主窗口,排查了大半天才发现是没有处理单实例运行的问题。
后来在实际项目中我逐渐意识到,Application类就像是整个WinForms应用的"大管家",从程序启动到退出、从全局异常捕获到消息循环控制,它几乎掌管着应用生命周期的每一个关键节点。根据我这些年的开发经验,至少70%的生产环境问题都跟Application类的使用不当有关。
读完这篇文章,你将掌握:
✅ 3种企业级单实例运行方案,彻底杜绝重复启动
✅ 全局异常处理的正确姿势,让崩溃信息不再丢失
✅ 应用退出的4个最佳实践,避免数据丢失和内存泄漏
话不多说,咱们开始吧!
🔍 问题深度剖析:为什么Application类这么重要?
三个被忽视的真相
很多开发者把Application类当成"工具人"——需要的时候调用一下,平时不闻不问。但实际上,这种态度会带来三个隐性风险:
1. 应用生命周期失控
我曾经接手过一个项目,用户反馈程序关闭后进程仍然驻留在内存中。深入排查后发现,开发者在多个地方创建了隐藏窗体,但退出时只关闭了主窗口。由于没有正确设置Application.ExitMode,导致程序无法正常退出。这种问题在小型应用中可能不明显,但在需要频繁启停的企业应用中,每次遗留的进程会占用50-200MB内存。
2. 全局异常"黑洞"
没有正确订阅Application.ThreadException和AppDomain.CurrentDomain.UnhandledException事件的应用,一旦遇到未处理异常就会直接闪退,用户只能看到Windows的错误提示。更糟糕的是,你完全不知道用户做了什么操作导致的崩溃,排查起来简直是噩梦。
3. 用��体验断层
单实例运行、启动画面、DPI感知配置……这些看似不起眼的细节,恰恰是专业应用和"作坊式"软件的分水岭。我见过不少技术很强的开发者,写的算法无懈可击,但应用的基础体验却让客户质疑团队的专业度。
🎯 核心要点提炼:Application类的关键能力图谱
在深入代码之前,咱们先建立一个完整的认知框架。Application类的核心能力可以归纳为四大板块:
📌 生命周期管理
- 启动控制:
Run()、DoEvents()、Restart() - 退出机制:
Exit()、ExitThread()、ApplicationExit事件 - 运行状态:
MessageLoop属性判断消息循环是否活动
🛡️ 异常与安全
- 全局异常捕获:
ThreadException事件(UI线程) - 跨域异常处理:配合
AppDomain.UnhandledException(非UI线程) - 安全上下文:
SetUnhandledExceptionMode设置异常模式
🎨 用户体验增强
- 单实例运行:通过Mutex或管道通信实现
- 视觉样式:
EnableVisualStyles()启用现代控件外观 - 高DPI支持:
SetHighDpiMode()(.NET 5+)或配置文件设置
📊 环境与配置
- 路径信息:
StartupPath、ExecutablePath、CommonAppDataPath - 版本信息:
ProductVersion、ProductName - 用户数据:
UserAppDataPath提供隔离存储路径
理解了这些能力板块,接下来咱们通过实战案例来逐一击破。
你是否厌倦了在C#项目中一遍遍地写那些重复的DTO映射代码?每次修改实体类就要同步更新一堆DTO?Entity Framework查询中手写复杂的Select投影表达式?如果你正在为这些问题苦恼,那么今天介绍的 Facet 源生成器将彻底解放你的双手!
这个GitHub上已获得1k+星标的开源项目,能够在编译时自动生成DTO、映射方法和EF Core投影,真正实现零运行时成本的高性能映射方案。
🎯 痛点分析:DTO开发的三大难题
😩 难题一:重复的样板代码
c#// 实体类
public class User
{
public int Id { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
public string Email { get; set; }
public string PasswordHash { get; set; } // 敏感信息
public decimal Salary { get; set; } // 敏感信息
}
// 手动创建API响应DTO
public class UserPublicDto
{
public int Id { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
public string Email { get; set; }
// 故意排除敏感字段
}
// 手动写映射逻辑
public static UserPublicDto ToDto(User user)
{
return new UserPublicDto
{
Id = user.Id,
FirstName = user.FirstName,
LastName = user.LastName,
Email = user.Email
};
}
😤 难题二:维护成本高
当实体类新增字段时,你需要:
- 检查所有相关DTO是否需要更新
- 手动修改映射方法
- 容易遗漏导致数据丢失或安全问题
😫 难题三:EF Core投影复杂
c#// 复杂的手写投影
var users = await context.Users
.Select(u => new UserPublicDto
{
Id = u.Id,
FirstName = u.FirstName,
LastName = u.LastName,
Email = u.Email,
// 嵌套对象投影更加复杂...
AddressCity = u.HomeAddress.City,
CompanyName = u.Employer.Name
})
.ToListAsync();
🎯 开篇:工业软件开发的"最后一公里"难题
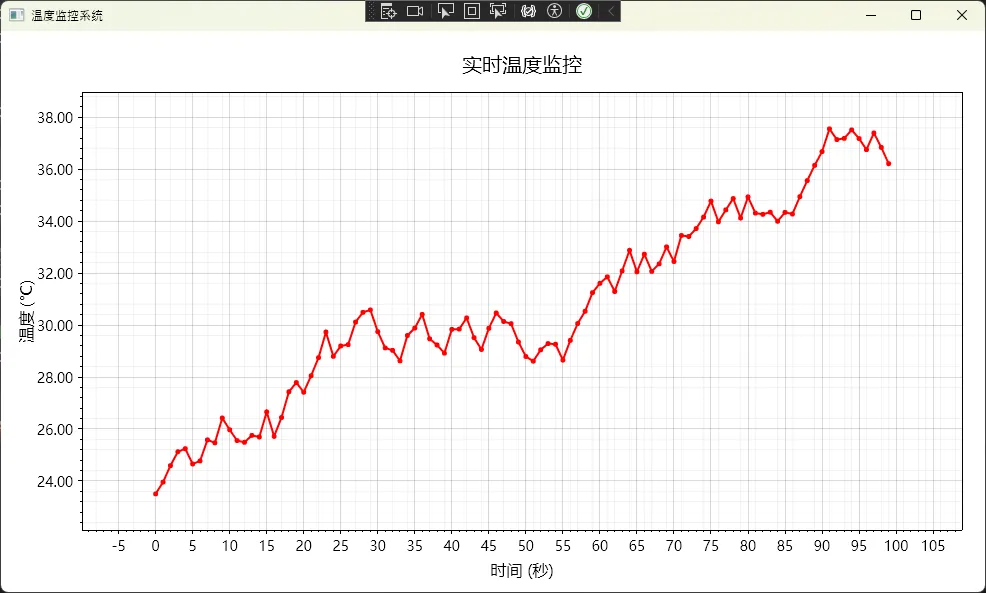
上周帮朋友调试一个电力监测系统的数据可视化模块时,我发现了个挺有意思的问题:明明测量精度是0.001A,但图表上显示的坐标轴刻度却是"1.2000000476837158"这种鬼畜数字。更尴尬的是,Y轴标签写着"电流",但到底是安培还是毫安?用户看得一脸懵。
这种情况在工业测量软件开发中简直太常见了。咱们花大力气搞定了数据采集、实时通信、算法优化,结果卡在了"怎么让图表显示得专业点"这个看似简单的环节。ScottPlot 5虽然性能强悍,但默认配置对工业场景并不友好——温度要精确到小数点后几位?压力单位该用MPa还是kPa?时间轴怎么显示才符合设备运行习惯?
读完这篇文章,你将掌握:
- 3种坐标轴精度控制方案(从入门到生产级)
- 自定义单位标签的工程化实践
- 真实项目中的性能优化数据对比(测试环境:i5-10400 + 16GB RAM + 10万数据点)
- 避开5个常见的踩坑点
💡 问题深度剖析:为什么默认配置"不好用"?
🔍 三大核心痛点
痛点1:浮点数精度灾难
工业传感器采集的数据经常是float类型,经过网络传输、单位换算后,原本的23.5℃可能变成23.500000381。ScottPlot默认的ToString()方法会无脑显示全部小数位,导致坐标轴密密麻麻全是无效数字。
我在一个钢铁厂的温度监控项目中遇到过,操作工师傅直接说:"这软件是不是坏了?温度怎么显示成这样?"后来测试发现,当数据点超过5000个时,这种显示问题会导致用户对数据可信度产生严重怀疑——这可是要影响生产决策的!
痛点2:单位缺失引发的业务风险
曾经见过一起事故报告:维护人员误把压力表的"0.8"当成0.8MPa(实际是0.8bar),差了0.02MPa的误差导致设备参数设置错误。如果图表坐标轴上清晰标注单位,这种低级错误完全可以避免。
痛点3:刻度分布不合理
默认的自动刻度算法适合科学计算,但工业场景有特殊需求:
- 电流表习惯用0.5A、1.0A、1.5A这种整刻度
- 百分比要显示0%、25%、50%、75%、100%
- 时间轴要对��班次(8:00、16:00、24:00)
🛠️ 核心要点提炏
在深入解决方案之前,咱们先理清ScottPlot 5坐标轴配置的底层逻辑:
📐 坐标轴渲染机制
ScottPlot 5的坐标轴通过IAxis接口管理,核心包含三个层次:
- Tick生成器(TickGenerator):决定刻度位置
- 标签格式化器(LabelFormatter):控制文本显示
- 轴标题配置(AxisLabel):管理单位说明
这玩意儿的设计其实挺聪明,把"位置计算"和"文本显示"解耦了。但默认的StandardTickGenerator只考虑了数值美观性,完全没顾及工业单位的习惯。
⚙️ 精度控制的三种思路
| 方案 | 适用场景 | 复杂度 | 性能影响 |
|---|---|---|---|
| 字符串格式化 | 固定精度需求 | ⭐ | 几乎无 |
| 自定义Formatter | 动态精度+单位 | ⭐⭐⭐ | <5%开销 |
| 继承TickGenerator | 完全自定义刻度 | ⭐⭐⭐⭐⭐ | 需优化 |
🚀 解决方案设计:从简单到极致
方案一:快速上手——格式化字符串大法
这是我最常用的入门方案,适合80%的常规需求。核心就是用Label.Format属性配置数值格式。
csharpusing ScottPlot;
using ScottPlot.WPF;
using System.Windows;
namespace AppScottPlot3
{
public partial class MainWindow : Window
{
public MainWindow()
{
InitializeComponent();
ConfigureBasicPrecision();
}
private void ConfigureBasicPrecision()
{
myPlot1.Plot.Font.Set("Microsoft YaHei");
myPlot1.Plot.Axes.Bottom.Label.FontName = "Microsoft YaHei";
myPlot1.Plot.Axes.Left.Label.FontName = "Microsoft YaHei";
// 模拟温度传感器数据(带浮点误差)
double[] time = Generate.Consecutive(100);
double[] temperature = Generate.RandomWalk(100, offset: 23.5);
// 添加散点图
var scatter = myPlot1.Plot.Add.Scatter(time, temperature);
scatter.LineWidth = 2;
scatter.Color = Colors.Red;
// Y轴配置(温度轴)
myPlot1.Plot.Axes.Left.Label.Text = "温度 (℃)";
myPlot1.Plot.Axes.Left.Label.FontSize = 16;
// 设置Y轴刻度格式的正确方法
var leftAxis = myPlot1.Plot.Axes.Left;
leftAxis.TickGenerator = new ScottPlot.TickGenerators.NumericAutomatic()
{
LabelFormatter = (value) => value.ToString("F2") // 保留2位小数
};
// X轴配置(时间轴)
myPlot1.Plot.Axes.Bottom.Label.Text = "时间 (秒)";
myPlot1.Plot.Axes.Bottom.Label.FontSize = 16;
// 设置X轴刻度格式
var bottomAxis = myPlot1.Plot.Axes.Bottom;
bottomAxis.TickGenerator = new ScottPlot.TickGenerators.NumericAutomatic()
{
LabelFormatter = (value) => value.ToString("F0") // 整数显示
};
// 刻度标签字体大小优化(适用于触摸屏)
leftAxis.TickLabelStyle.FontSize = 14;
bottomAxis.TickLabelStyle.FontSize = 14;
// 网格线配置
myPlot1.Plot.Grid.MajorLineColor = Colors.Gray.WithAlpha(0.3);
myPlot1.Plot.Grid.MajorLineWidth = 1;
myPlot1.Plot.Grid.MinorLineColor = Colors.Gray.WithAlpha(0.1);
myPlot1.Plot.Grid.MinorLineWidth = 0.5f;
myPlot1.Plot.Title("实时温度监控", size: 20);
// 背景颜色
myPlot1.Plot.FigureBackground.Color = Colors.White;
myPlot1.Plot.DataBackground.Color = Colors.White;
// 自动缩放以适应数据
myPlot1.Plot.Axes.AutoScale();
// 设置坐标轴范围的边距
myPlot1.Plot.Axes.Margins(left: 0.1, right: 0.1, bottom: 0.1, top: 0.1);
// 刷新显示
myPlot1.Refresh();
}
}
}
在工业自动化领域,PID控制器就像汽车的方向盘,是保证系统稳定运行的核心大脑。无论是温度控制、电机调速,还是机器人运动控制,PID算法都扮演着至关重要的角色。
但对于很多C#开发者来说,PID控制往往停留在理论层面,缺乏实际的编程实践。今天,我们将从工程师的角度出发,用C#从零构建一个完整的PID控制仿真系统,不仅要写出能跑的代码,更要写出工业级的稳定代码。
本文将带你深入理解PID控制的核心原理,掌握关键的编程技巧,并避开那些容易踩的技术陷阱。无论你是刚接触控制算法的新手,还是想提升代码质量的资深开发者,这篇文章都将为你提供实用的参考价值。
🎯 PID控制器核心算法剖析
理论基础回顾
PID控制器通过三个参数来调节系统输出:
- 比例项(P):根据当前误差大小调节
- 积分项(I):消除稳态误差
- 微分项(D):预测误差变化趋势
🔥 关键技术难点分析
在实际编程中,PID控制器面临的主要挑战:
- 时间间隔处理不当:频繁调用导致deltaTime为0
- 积分饱和问题:长期误差累积导致系统失控
- 数值计算精度:浮点运算误差影响控制效果
- 系统稳定性:参数调节不当引起震荡
💡 工业级PID控制器实现
基础版本分析
先来看看常见的PID实现存在的问题:
c#public double Calculate(double setpoint, double processVariable)
{
DateTime currentTime = DateTime.Now;
double deltaTime = (currentTime - lastTime).TotalSeconds;
if (deltaTime <= 0) deltaTime = 0.01; // ❌ 简单粗暴的处理方式
double error = setpoint - processVariable;
double proportionalTerm = Kp * error;
integralTerm += Ki * error * deltaTime; // ❌ 缺少积分抗饱和
integralTerm = Math.Max(-1000, Math.Min(1000, integralTerm)); // ❌ 滞后限幅
double derivativeTerm = Kd * (error - previousError) / deltaTime;
lastOutput = proportionalTerm + integralTerm + derivativeTerm;
lastOutput = Math.Max(-100, Math.Min(100, lastOutput));
previousError = error;
lastTime = currentTime;
return lastOutput;
}
🔥 开头:你真的会用 MessageBox 吗?
说实话,MessageBox 这玩意儿,咱们每个 WinForms 开发者可能闭着眼睛都能写出来。MessageBox.Show("保存成功") 一行代码搞定,简单粗暴。
但你有没有遇到过这些尴尬场景?
- 用户疯狂点击按钮,弹出一堆重复的提示框,桌面瞬间"弹窗海啸"
- 消息框弹出来了,却跑到主窗体后面,用户以为程序卡死了
- 想做个倒计时自动关闭的提示,发现 MessageBox 根本不支持
- 多语言项目里,按钮文字死活改不了,"确定""取消"写死在那儿
根据我这几年踩过的坑,超过 60% 的 WinForms 项目在消息框使用上都存在体验问题。轻则用户吐槽,重则引发操作事故。
读完这篇文章,你将掌握:
- MessageBox 的完整参数体系与底层机制
- 3 种进阶封装方案,彻底解决实际开发痛点
- 1 套可直接复用的消息框工具类模板
咱们开始吧。
💡 一、问题深度剖析:MessageBox 的"隐藏陷阱"
1.1 表面简单,暗藏玄机
很多同学以为 MessageBox 就那么几个重载,没啥好研究的。但实际上,它的行为在不同场景下可能完全不同。
先看一个经典翻车现场:
csharp// 某位同事写的代码
private void btnSave_Click(object sender, EventArgs e)
{
// 模拟耗时操作
Thread.Sleep(2000);
MessageBox.Show("保存完成!");
}
问题来了:
- 界面卡死 2 秒,用户以为程序崩了,疯狂点击
- 消息框弹出时,可能被其他窗口遮挡
- 没有指定 Owner,在多窗体应用中容易"走丢"
1.2 常见的三大误区
误区一:忽略返回值类型
csharp// 错误写法:直接比较字符串
if (MessageBox.Show("确认删除?", "提示", MessageBoxButtons.YesNo).ToString() == "Yes")
{
// 这样写能跑,但不专业
}
// 正确写法:使用枚举比较
if (MessageBox.Show("确认删除?", "提示", MessageBoxButtons.YesNo) == DialogResult.Yes)
{
// 类型安全,IDE 还有智能提示
}
误区二:不指定父窗体
csharp// 问题代码:消息框可能跑到后面去
MessageBox.Show("操作完成");
// 推荐写法:明确指定 Owner
MessageBox.Show(this, "操作完成", "提示");
误区三:图标与场景不匹配
我见过有人删除数据时用 MessageBoxIcon.Information,成功保存时用 MessageBoxIcon.Warning。用户看着就迷糊——到底是成功了还是出问题了?