
Tkinter 视觉效果优化:扁平化与美观主题实战指南
🎨 说在前面:那个"土"字,扎心了
做过 Tkinter 项目的人,多少都听过这句话——"这界面怎么这么土?"
不冤枉。默认的 Tkinter 界面,灰底灰按钮,控件边框带着浮雕感,字体是系统默认的宋体,整体风格停留在 Windows XP 时代。拿去给客户演示,对方第一反应往往是:"这是正式版吗?"
问题不在于 Tkinter 本身能力不行,而在于大多数教程只教你怎么"摆控件",从来不讲怎么让它好看。底层的 ttk 主题引擎、Style 配置系统、Canvas 自绘机制,这些才是让界面脱胎换骨的关键,却鲜有人系统讲过。
这篇文章就干这件事。从原理到代码,从快速美化到深度定制,给你一套在 Windows 下把 Tkinter 界面做到"现代感"的完整方案。所有代码在 Python 3.10 + Windows 11 环境下验证可运行。
🔍 先搞清楚:Tkinter 的视觉体系是怎么运作的
很多人不知道,Tkinter 其实有两套控件体系并存——tkinter(经典控件)和 tkinter.ttk(主题控件)。
经典控件,比如 tk.Button、tk.Label,样式完全靠属性硬写,bg、fg、relief,每个控件单独配,改起来费劲,统一性也差。ttk 控件则不同,它引入了主题(Theme)机制,通过 ttk.Style 统一管理所有控件的外观,一处改,全局生效。
pythonimport tkinter.ttk as ttk
style = ttk.Style()
print(style.theme_names())
# ('winnative', 'clam', 'alt', 'default', 'classic', 'vista', 'xpnative')
Windows 下内置了 vista、winnative、xpnative 等主题,但说实话,这几个主题的审美水准……和"现代"二字还差得远。clam 主题相对简洁,是自定义改造的最佳基底——后面咱们会重点用它。
核心结论:做视觉优化,优先用 ttk 控件 + ttk.Style 定制,而不是给每个 tk 控件单独设属性。
🚀 方案一:基于 ttkbootstrap 的快速现代化
如果项目工期紧,想最快速度出效果,ttkbootstrap 是目前最成熟的选择。它是对 ttk 的封装,内置了十几套 Bootstrap 风格主题,引入成本极低,做过web前端的一看就知道怎么个玩意了。
bashpip install ttkbootstrap
直接看效果对比——原始代码:
python# 原始 Tkinter 界面(灰色时代)
import tkinter as tk
root = tk.Tk()
root.title("原始界面")
tk.Label(root, text="用户名").pack()
tk.Entry(root).pack()
tk.Button(root, text="登录").pack()
root.mainloop()
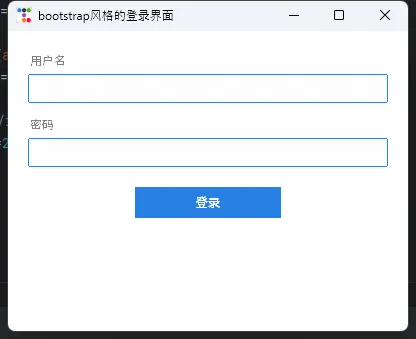
换成 ttkbootstrap 之后:
pythonimport ttkbootstrap as ttk
from ttkbootstrap.constants import *
# 一行代码切换主题
root = ttk.Window(themename="cosmo") # 可选: flatly, darkly, superhero, journal...
root.title("bootstrap风格的登录界面")
root.geometry("400x300")
frame = ttk.Frame(root, padding=20)
frame.pack(fill="both", expand=True)
ttk.Label(frame, text="用户名", bootstyle="secondary").pack(anchor="w")
ttk.Entry(frame, bootstyle="primary").pack(fill="x", pady=(4, 12))
ttk.Label(frame, text="密码", bootstyle="secondary").pack(anchor="w")
ttk.Entry(frame, show="*", bootstyle="primary").pack(fill="x", pady=(4, 20))
# bootstyle 参数控制颜色语义:primary/success/danger/warning/info
ttk.Button(frame, text="登录", bootstyle="primary", width=20).pack()
root.mainloop()
🧩 先说说这事儿的来龙去脉
做过桌面工具的朋友,多少都踩过这个坑——程序跑着跑着出了问题,你打开一看,日志?没有。数据库记录?空的。只剩一个报错弹窗,连个回溯的线索都没给你留。
这不是代码写得烂,是架构设计漏了一环。
日志和数据库,本质上是两种不同维度的记录手段。 文件日志是时序流水账,适合排查"什么时间发生了什么";数据库则是结构化存档,适合做统计、筛选、分析。两者不是竞争关系,而是互补的——就像监控录像和案件档案,缺一不可。
今天咱们就用 Tkinter 搭一个真实可用的桌面应用,把这两套机制整合进去,做成一个操作行为双轨记录系统。用户在界面上的每一步操作,既写进 .log 文件,也存进 SQLite 数据库,随时可查、可导出、可分析。
文章涵盖:
logging模块的进阶配置(不只是basicConfig)- SQLite 与 Tkinter 的整合方式
- 多线程写入的安全性处理
- 日志查询界面的实现
代码全部可运行,Windows 环境验证过。
🏗️ 整体架构先捋一遍
别急着写代码。先把脑子里的结构理清楚,后面写起来才不会乱。
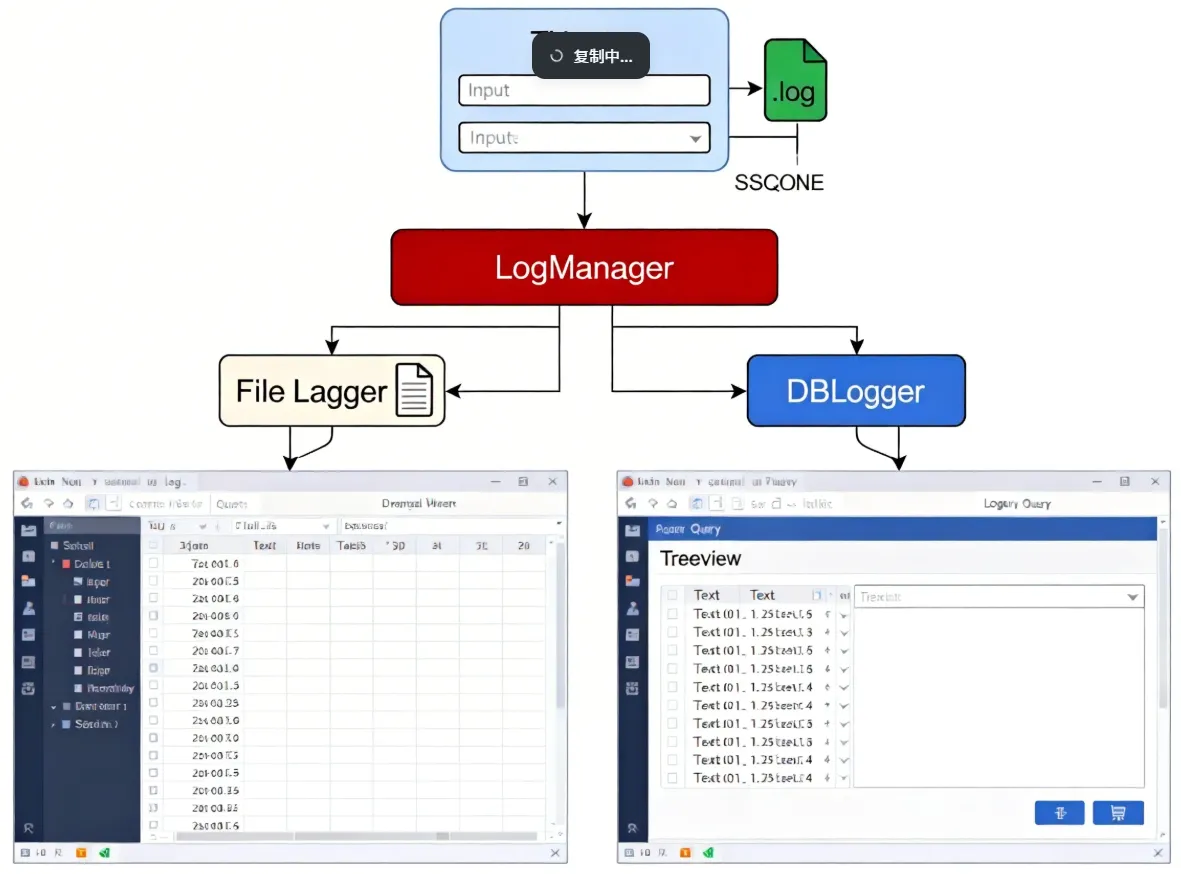
三层结构:界面层触发事件,核心层双写,展示层读取查询。干净,职责清晰,改哪层不影响另外两层。
🔧 环境准备
Python 标准库全家桶,不需要额外安装第三方包:
python# 用到的模块清单
import tkinter as tk
from tkinter import ttk, messagebox, filedialog
import logging
import sqlite3
import threading
import os
import csv
from datetime import datetime
SQLite 是 Python 内置的,logging 也是,Tkinter 在 Windows 下随 Python 一起装好了。零依赖,拿来就能跑。
你是否曾经好奇,当你在C#中使用dynamic关键字时,编译器是如何在运行时决定调用哪个方法的?或者想知道为什么动态调用比静态调用慢那么多?今天我们就来揭开C# RuntimeBinder的神秘面纱,探索动态编程背后的技术原理。
很多C#开发者对dynamic关键字既爱又恨——它提供了强大的灵活性,但性能开销和调试难度也让人头疼。本文将带你深入理解RuntimeBinder的工作机制,掌握动态编程的精髓,让你在需要时能够游刃有余地运用这项技术。
🎯 问题分析:动态调用的痛点
性能困扰
许多开发者在使用dynamic时都遇到过性能问题:
- 动态调用比静态调用慢10-100倍
- 大量动态操作导致应用响应缓慢
- 不理解缓存机制导致重复的绑定开销
调试难题;
- 编译时无法发现错误,只能在运行时抛出异常
- 调用栈信息不够清晰
- IntelliSense无法提供代码提示
理解误区
- 认为
dynamic就是"弱类型"编程 - 不了解绑定器的缓存策略
- 混淆反射与动态调用的区别
💡 解决方案:掌握RuntimeBinder的4个核心概念
🔧 1. 理解绑定器工厂模式
RuntimeBinder采用工厂模式创建不同类型的绑定器,每种操作都有对应的绑定器:
c#using Microsoft.CSharp.RuntimeBinder;
using System;
using System.Dynamic;
using System.Runtime.CompilerServices;
namespace AppRuntimeBinderEx
{
// 模拟动态成员访问的实现原理
public static class DynamicHelper
{
public static object GetMemberValue(object target, string memberName)
{
// 这就是dynamic关键字背后做的事情
var binder = Binder.GetMember(
CSharpBinderFlags.None,
memberName,
target.GetType(),
new[] { CSharpArgumentInfo.Create(CSharpArgumentInfoFlags.None, null) }
);
var site = CallSite<Func<CallSite, object, object>>.Create(binder);
return site.Target(site, target);
}
}
internal class Program
{
static void Main(string[] args)
{
var person = new { Name = "张三", Age = 25 };
// 使用dynamic(推荐方式)
dynamic dynamicPerson = person;
Console.WriteLine(dynamicPerson.Name); // 编译器会生成类似上面的代码
// 手动使用绑定器(了解原理)
var name = DynamicHelper.GetMemberValue(person, "Name");
Console.WriteLine(name);
}
}
}
🤔 先聊聊,为什么不用 GDI+?
说真的,刚接到这个需求的时候,我第一反应是——WinForms 嘛,Graphics.DrawImage 不就完了?
然后我就被打脸了。
项目里需要同屏渲染 300+ 个 Sprite,每个都有旋转、缩放、透明度变化。用 GDI+ 跑起来,帧率直接掉到个位数。那一刻我盯着任务管理器,CPU 占用 80%,GPU 占用 3%——这反差,看得我心里一紧。
问题很明显:GDI+ 是纯软件光栅化,它根本不走 GPU。而 SkiaSharp 底层是 Google 的 Skia 图形引擎,配合 SKGLControl 可以直接走 OpenGL 硬件加速。同样的 300 个 Sprite,换了渲染后端,帧率从 8fps 飙到 60fps 稳定不掉。
这就是今天这篇文章的起点。
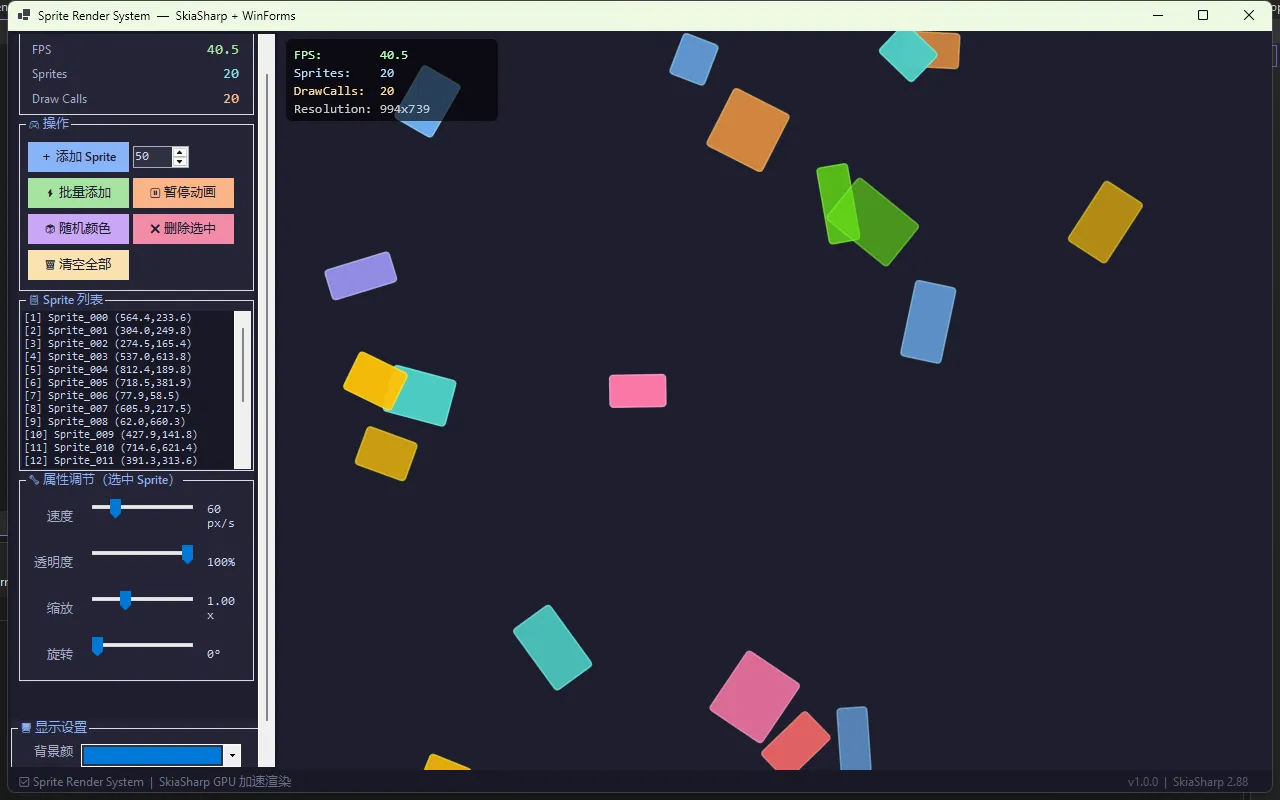
👩💻 先看一下效果
🏗 整体架构,先想清楚再动手
很多人上来就写代码,写着写着发现结构乱了,再重构就很痛苦。我吃过这个亏,所以现在养成了一个习惯——先把模块边界画清楚。
这套系统拆成四个核心类:
Sprite → 数据模型,描述"一个精灵是什么" SpriteSheet → 图集管理,解决"纹理从哪来" SpriteBatch → 批量渲染,解决"怎么画得快" SpriteRenderer → 游戏循环,解决"什么时候画"
这四层的关系,有点像餐厅运营:Sprite 是菜单上的每道菜,SpriteSheet 是食材仓库,SpriteBatch 是厨房的出餐流水线,SpriteRenderer 是那个掐着表控制出餐节奏的主厨。
分层之后,每个模块的职责非常单一,改一处不会牵连其他地方。这在后期加功能的时候,省了我大量时间。
🏭 你的工厂软件,真的需要那么重吗?
车间里那台老电脑,跑着一个动辄几百MB的工单客户端,启动要等两分钟,数据库连不上还报一堆英文错——这场景,干过工控或制造业项目的朋友应该不陌生。
我在给一家中型注塑厂做系统改造的时候,客户第一句话就是:"能不能别用那种装起来麻烦的东西?"说真的,这个需求戳到我了。大多数中小型制造企业,并不需要SAP那个级别的庞然大物,他们要的是快、稳、好维护。
后来我用 Tkinter + SQLite 搭了一套轻量级MES的数据层原型,部署包才8MB,冷启动不到3秒,车间主任自己都能在本地跑起来。这篇文章,就把这套思路完整拆给你看——从数据库设计、到界面绑定、再到性能优化,每一步都有可以直接跑的代码。
🔍 问题根源:为什么"轻量"这么难做到?
很多人一上来就选型错了。SQLite 被当成"玩具数据库",Tkinter 被嫌弃"界面丑"——这两个偏见,直接把一条好路给堵死了。
实际情况是这样的: SQLite 在单机并发写入场景下,每秒可以处理 35,000 次以上的写操作(官方测试数据,SSD环境)。对于一个班次产量不超过10万条记录的车间,这个性能绰绰有余。Tkinter 虽然不如 PyQt 漂亮,但它是 Python 标准库自带的,零依赖、零安装,这在工厂环境里是真金白银的优势。
常见的错误做法有三种:
- 用
fetchall()一次性把几万条工单数据全拉进内存,然后抱怨"卡死了" - 每次界面刷新都重新建立数据库连接,连接开销累积成性能瓶颈
- 没有做任何索引,随着数据量增长,查询时间从毫秒级退化到秒级
这些坑,我都踩过。下面的方案,就是从这些教训里提炼出来的。
🏗️ 数据库设计:MES的骨架
一个最小可用的MES数据层,至少需要这几张表:工单表、工序表、生产记录表、设备状态表。设计的时候有个原则我一直在用——够用就好,别过度设计。
sql-- mes_core.sql
CREATE TABLE IF NOT EXISTS work_orders (
id INTEGER PRIMARY KEY AUTOINCREMENT,
order_no TEXT NOT NULL UNIQUE, -- 工单号,业务唯一键
product TEXT NOT NULL, -- 产品名称
planned_qty INTEGER DEFAULT 0, -- 计划数量
status TEXT DEFAULT 'pending', -- pending/running/done
created_at TEXT DEFAULT (datetime('now','localtime'))
);
CREATE TABLE IF NOT EXISTS production_logs (
id INTEGER PRIMARY KEY AUTOINCREMENT,
order_id INTEGER NOT NULL,
operator TEXT,
actual_qty INTEGER DEFAULT 0,
defect_qty INTEGER DEFAULT 0,
machine_id TEXT,
log_time TEXT DEFAULT (datetime('now','localtime')),
FOREIGN KEY (order_id) REFERENCES work_orders(id)
);
-- 关键索引,别省这一步
CREATE INDEX IF NOT EXISTS idx_logs_order ON production_logs(order_id);
CREATE INDEX IF NOT EXISTS idx_logs_time ON production_logs(log_time);
CREATE INDEX IF NOT EXISTS idx_orders_status ON work_orders(status);
索引这件事,很多新手觉得"以后数据多了再加"。错。索引要在建表的时候就规划好,事后加索引在数据量大的时候本身就是一次痛苦的操作。
