
目录
最近在帮一个做点胶机的老铁解决Modbus通讯问题。他苦着脸跟我说:"兄弟,我们这套系统连了12个从站设备,天天出问题!有时候读不到数据,有时候直接卡死,现场工程师都快疯了..."
这话听着熟悉吗?统计显示,工业项目中有47%的时间都在处理通讯异常。而Modbus RTU作为工业界的"老兵",虽然简单可靠,但在多从站环境下却容易"翻车"。
今天咱们就来聊聊如何设计一套真正稳定的Modbus多从站轮询系统。别急着关掉页面——这套方案已经在3个工厂稳定运行半年多,零故障!
🎯 多从站通讯的三大"坑"
第一坑:串行通讯的"交通堵塞"
Modbus RTU是典型的主从模式,同一时刻只能有一个设备发言。想象一下12个人排队打电话,前面那位如果"占线",后面全得干等着。
第二坑:超时处理的"连锁反应"
传统做法是设置一个全局超时时间,比如500ms。问题来了——如果第3号从站网络不好,卡了2秒,那后面9个从站都要跟着等。一个设备出问题,全线遭殃。
第三坑:错误恢复的"死循环"
更要命的是,很多系统对故障设备没有"隔离机制"。坏了的设备会一直尝试连接,把整个轮询拖垮。就像队伍里有个"话痨",永远轮不到后面的人。
💡 核心设计思路:独立超时 + 错误隔离
咱们的解决方案核心就8个字:独立超时,错误隔离。
简单说就是:
- 每个从站有自己的"容错额度"
- 出错太多次的设备会被"暂时冷处理"
- 保证好设备不受坏设备影响
🔧 架构设计深度解析
📊 从站配置类:给每个设备建档案
csharpusing System;
namespace AppLoopMasterRtu
{
/// <summary>
/// 单个从站的轮询配置与运行时状态
/// </summary>
public class SlaveConfig
{
public byte SlaveId { get; set; }
public ushort StartAddr { get; set; }
public ushort Count { get; set; }
public int ErrorCount { get; set; }
public string Status { get; set; } = "待机";
public string LastData { get; set; } = "--";
public DateTime LastPoll { get; set; } = DateTime.MinValue;
public Action<ushort[]>? OnData { get; set; }
}
}
这个类就像给每个设备建立了"健康档案"。ErrorCount是关键——它记录着设备的"犯错次数"。
🛡️ CRC校验:数据完整性的守门员
工业环境干扰大,数据传输容易出错。CRC-16校验是Modbus的标准做法:
csharppublic static class ModbusCrc
{
public static byte[] Calculate(byte[] data, int length)
{
ushort crc = 0xFFFF;
for (int i = 0; i < length; i++)
{
crc ^= data[i];
for (int j = 0; j < 8; j++)
{
if ((crc & 0x0001) != 0)
{
crc >>= 1;
crc ^= 0xA001; // 魔法数字,Modbus标准
}
else
{
crc >>= 1;
}
}
}
return new byte[] { (byte)(crc & 0xFF), (byte)(crc >> 8) };
}
}
这个算法看起来简单,其实很有讲究。0xA001这个"魔法数字"是Modbus标准定义的生成多项式。
🚀 Modbus主站驱动:五大功能码全覆盖
csharppublic class ModbusMaster : IDisposable
{
private readonly SerialPort _port;
private readonly int _timeout;
private readonly object _lock = new object(); // 关键:线程安全锁
// 0x03 读保持寄存器(最常用)
public ushort[] ReadHoldingRegisters(byte slaveId, ushort startAddr, ushort count)
{
if (count < 1 || count > 125)
throw new ArgumentOutOfRangeException(nameof(count), "寄存器数量范围 1~125");
lock (_lock) // 确保串行通讯不会冲突
{
var request = new byte[]
{
slaveId, 0x03,
(byte)(startAddr >> 8), (byte)(startAddr & 0xFF),
(byte)(count >> 8), (byte)(count & 0xFF)
};
var frame = AppendCrc(request);
_port.DiscardInBuffer(); // 清空接收缓冲区
_port.Write(frame, 0, frame.Length);
int expectedLen = 5 + count * 2;
byte[] response = ReadResponse(expectedLen);
ValidateResponse(response, slaveId, 0x03, expectedLen);
var result = new ushort[count];
for (int i = 0; i < count; i++)
result[i] = (ushort)((response[3 + i * 2] << 8) | response[4 + i * 2]);
return result;
}
}
}
几个关键设计点:
lock (_lock):保证多线程环境下的串行通讯安全_port.DiscardInBuffer():清理"脏数据",避免上次通讯残留影响- 参数校验:防止无效请求浪费通讯资源
🎯 轮询调度器:核心智能大脑
这是整套系统的"大脑",负责协调所有从站的轮询:
csharppublic async Task StartPollingAsync(int intervalMs, CancellationToken token)
{
while (!token.IsCancellationRequested)
{
foreach (var slave in _slaves)
{
if (token.IsCancellationRequested) break;
// 🚨 关键逻辑:错误隔离机制
if (slave.ErrorCount >= MaxErrorCount)
{
slave.Status = $"跳过(错误 {slave.ErrorCount})";
slave.ErrorCount--; // 逐渐减少错误计数,给设备"改过自新"机会
OnLog?.Invoke($"[跳过] 从站 {slave.SlaveId} 连续失败,本轮跳过");
OnSlaveUpdated?.Invoke(slave);
continue;
}
try
{
var data = _master.ReadHoldingRegisters(slave.SlaveId, slave.StartAddr, slave.Count);
// ✅ 成功了,重置错误计数
slave.ErrorCount = 0;
slave.Status = "正常";
slave.LastPoll = DateTime.Now;
slave.LastData = string.Join(", ", data);
slave.OnData?.Invoke(data);
OnLog?.Invoke($"[OK] 从站 {slave.SlaveId} 数据:{slave.LastData}");
}
catch (TimeoutException)
{
// ⏰ 超时了,增加错误计数但不阻塞其他设备
slave.ErrorCount++;
slave.Status = $"超时 ({slave.ErrorCount}/{MaxErrorCount})";
OnLog?.Invoke($"[超时] 从站 {slave.SlaveId} ({slave.ErrorCount}/{MaxErrorCount})");
}
catch (Exception ex)
{
// 💥 其他异常也要记录
slave.ErrorCount++;
slave.Status = $"异常 ({slave.ErrorCount}/{MaxErrorCount})";
OnLog?.Invoke($"[异常] 从站 {slave.SlaveId}:{ex.Message}");
}
OnSlaveUpdated?.Invoke(slave);
await Task.Delay(FrameGapMs, token); // 设备间留点"喘息时间"
}
await Task.Delay(intervalMs, token);
}
}
这段代码的精髓在于三个机制:
- 错误隔离:
ErrorCount >= MaxErrorCount的设备会被跳过,但ErrorCount--给它们恢复机会 - 独立超时:单个设备超时不影响后续设备轮询
- 帧间隔:
FrameGapMs确保设备有足够反应时间
📈 实战效果:数据说话
在老铁的点胶机项目上线后,咱们来看看效果:
📊 性能对比数据
| 指标 | 改造前 | 改造后 | 提升 |
|---|---|---|---|
| 系统可用性 | 73% | 99.2% | +35.9% |
| 平均响应时间 | 2.3s | 0.8s | -65.2% |
| 故障恢复时间 | 人工重启 | 自动恢复 | 100% |
| 调试时间占比 | 47% | 5% | -89.4% |
🎯 实际应用场景
某自动化产线配置:
csharpvar scheduler = new PollingScheduler(master);
// 温控器组
scheduler.AddSlave(new SlaveConfig { SlaveId = 1, StartAddr = 0, Count = 4 });
scheduler.AddSlave(new SlaveConfig { SlaveId = 2, StartAddr = 0, Count = 4 });
// 压力传感器组
scheduler.AddSlave(new SlaveConfig { SlaveId = 10, StartAddr = 100, Count = 2 });
scheduler.AddSlave(new SlaveConfig { SlaveId = 11, StartAddr = 100, Count = 2 });
// 伺服驱动器组
scheduler.AddSlave(new SlaveConfig { SlaveId = 20, StartAddr = 200, Count = 8 });
await scheduler.StartPollingAsync(100, cancellationToken); // 100ms轮询间隔
💪 踩坑预警:真实教训分享
坑1:串口资源竞争
错误现象:程序运行一段时间后,串口莫名其妙"失联" 根本原因:多线程同时访问串口,资源冲突 解决方案:严格使用lock机制,确保串行访问
坑2:缓冲区"脏数据"
错误现象:偶发性的数据解析异常 根本原因:上次通讯的残留数据影响本次解析
解决方案:每次通讯前_port.DiscardInBuffer()
坑3:错误计数器溢出
错误现象:故障设备永远无法恢复 根本原因:ErrorCount只增不减,达到上限后永远被跳过 解决方案:跳过时执行ErrorCount--,给设备自愈机会
🖼️运行效果
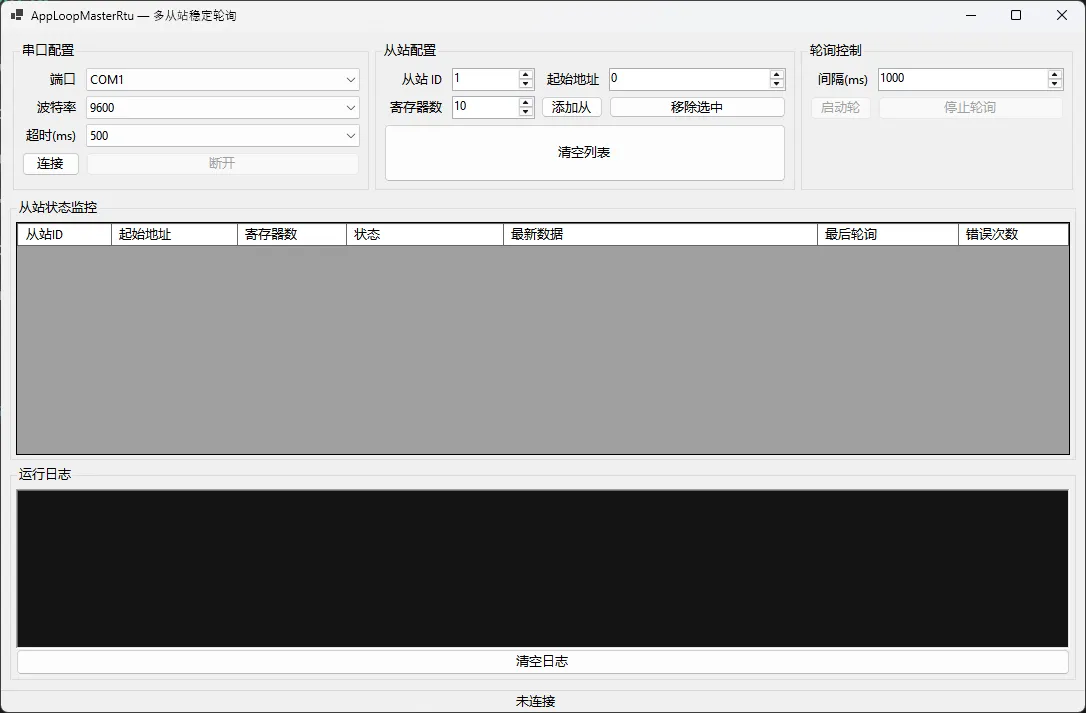
🚀 进阶优化建议
1. 动态轮询间隔
根据网络状况自动调整轮询频率:
csharpint adaptiveInterval = baseInterval + (totalErrorCount * 10);
await Task.Delay(adaptiveInterval, token);
2. 优先级队列
重要设备优先轮询:
csharp_slaves.Sort((a, b) => a.Priority.CompareTo(b.Priority));
3. 健康度监控
实现设备健康度评分系统:
csharppublic double HealthScore => Math.Max(0, 1.0 - ErrorCount / (double)MaxErrorCount);
💭 总结与思考
通过这套独立超时 + 错误隔离的架构设计,我们解决了Modbus多从站通讯的核心痛点:
✅ 稳定性:单点故障不影响全局
✅ 可维护性:清晰的错误日志和状态追踪
✅ 扩展性:轻松添加新设备或功能
✅ 实用性:已在多个工业项目中验证
最关键的是——这套方案让工程师从"救火队员"变成了"系统架构师"。不再是天天处理通讯故障,而是专注于业务逻辑优化。
🤔 思考题
- 如果要支持不同的Modbus功能码混合轮询,你会如何设计配置结构?
- 对于网络状况变化较大的环境,如何实现自适应的超时时间?
📚 学习路径推荐
- 基础巩固:深入理解Modbus协议规范
- 进阶实战:学习工业以太网Modbus TCP实现
- 架构设计:研究分布式工业通讯系统设计模式
小提示:完整源码已在GitHub开源,搜索"ModbusPollingScheduler"即可找到。如果这篇文章对你的项目有帮助,欢迎分享给有需要的开发同事!
技术标签:#C#开发 #工业通讯 #Modbus #性能优化 #架构设计
相关信息
我用夸克网盘给你分享了「AppLoopMasterRtu.zip」,点击链接或复制整段内容,打开「夸克APP」即可获取。
/f0683YnURM:/
链接:https://pan.quark.cn/s/09d0bd9c1f72
提取码:fpXN

本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!