
目录
🤔 你是否也遇到过这些"玄学"报错?
第一次把 PaddleSharp 引入 C# 项目,很多开发者都会在环境搭建这一关栽跟头。安装完 Sdcb.PaddleOCR 之后,项目编译通过,一运行就抛出 DllNotFoundException: Unable to load DLL 'paddle_inference_c';或者装了 GPU 运行时包,却发现推理速度和 CPU 版本毫无差别;甚至有人同时装了 CPU 和 GPU 两个 runtime,结果程序直接崩溃,找不到任何有意义的错误信息。
这类问题的根源,几乎都指向同一个地方——对 PaddleSharp 的包结构与运行时依赖关系理解不够清晰。
PaddleSharp 的包设计遵循"核心绑定层 + 平台原生运行时"的分层架构,不同于常见的"一包到底"风格。这种设计本身非常合理,给了开发者极大的灵活性,但也意味着:如果不理解各个包之间的依赖关系,随意组合就会踩坑。
读完本文,你将掌握:PaddleSharp 核心包体系的正确理解方式、CPU/GPU 两套运行时的精准选型方法,以及一份可直接复用的完整项目配置模板,适用于从入门到生产的绝大多数 C# 图像识别场景。
🧩 先搞清楚包结构:三层依赖模型
在动手安装之前,有必要先把 PaddleSharp 的包体系在脑子里建立一个清晰的模型。整个生态可以分成三层:
第一层:核心绑定层,也就是 Sdcb.PaddleInference。这个包是整个体系的基础,它封装了百度飞桨 Paddle Inference C API 的 .NET P/Invoke 绑定,提供了统一的推理引擎接口。它本身不包含任何原生二进制文件,只是"接口层",支持 .NET Framework 4.5+、.NET Standard 2.0、.NET 6/8 等主流目标框架。
第二层:平台原生运行时层,也就是各种 Sdcb.PaddleInference.runtime.* 包。这一层才是真正的"肌肉"——包含了不同平台、不同加速后端的原生 .dll 或 .so 文件。CPU 场景下有 mkl(推荐)、openblas、openblas-noavx 三种选择;GPU 场景下则根据 CUDA 版本和显卡架构细分为十几个包。
第三层:功能模块层,包括 Sdcb.PaddleOCR、Sdcb.PaddleDetection 等具体业务包。它们依赖第一层的绑定接口,在上层提供文字识别、目标检测等高层 API。
理解这个三层结构之后,很多"玄学报错"就有了清晰的解释:DllNotFoundException 几乎都是因为第二层的运行时包没有安装,或者安装了错误的版本。
📦 CPU 环境搭建:最常用的入门路线
对于绝大多数开发场景——比如内网文档识别、票据处理、验证码识别等——CPU 推理完全够用,而且部署更简单。下面是一套经过验证的标准配置。
🔧 第一步:安装核心 NuGet 包
在 Visual Studio 的 NuGet 包管理器中,或者通过 .NET CLI,依次安装以下包:
bash# 核心推理绑定层
dotnet add package Sdcb.PaddleInference
# CPU 运行时(MKL 版,推荐大多数用户使用)
dotnet add package Sdcb.PaddleInference.runtime.win64.mkl
# OCR 功能模块
dotnet add package Sdcb.PaddleOCR
# OCR 模型下载管理
dotnet add package Sdcb.PaddleOCR.Models.Local
# 图像处理依赖
dotnet add package OpenCvSharp4
dotnet add package OpenCvSharp4.runtime.win
关键注意事项:Sdcb.PaddleInference.runtime.win64.mkl 和任何 GPU 运行时包绝对不能同时安装,否则会引发原生库冲突,导致运行时崩溃。这是最常见的踩坑点之一。
🔧 第二步:验证依赖关系
安装完成后,检查项目文件 .csproj,正确的引用应该类似这样:
xml<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<OutputType>Exe</OutputType>
<TargetFramework>net10.0</TargetFramework>
<ImplicitUsings>enable</ImplicitUsings>
<Nullable>enable</Nullable>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="OpenCvSharp4" Version="4.13.0.20260427" />
<PackageReference Include="OpenCvSharp4.runtime.win" Version="4.13.0.20260302" />
<PackageReference Include="Sdcb.PaddleInference" Version="3.0.1" />
<PackageReference Include="Sdcb.PaddleInference.runtime.win64.mkl" Version="3.1.0.54" />
<PackageReference Include="Sdcb.PaddleOCR" Version="3.0.1" />
<PackageReference Include="Sdcb.PaddleOCR.Models.Local" Version="3.0.1" />
</ItemGroup>
</Project>
🔧 第三步:编写第一个 OCR 识别程序
下面是一个完整可运行的示例,演示如何用 PaddleSharp 识别本地图片中的文字:
csharpusing OpenCvSharp;
using Sdcb.PaddleInference;
using Sdcb.PaddleOCR;
using Sdcb.PaddleOCR.Models.Local;
namespace AppPaddleSharp02
{
internal class Program
{
static void Main(string[] args)
{
using var ocr = new PaddleOcrAll(
model: LocalFullModels.ChineseV4,
device: PaddleDevice.Mkldnn(cacheCapacity: 1))
{
AllowRotateDetection = false,
Enable180Classification = false
};
string imagePath = @"invoice.png";
using Mat src = Cv2.ImRead(imagePath, ImreadModes.Color);
if (src.Empty())
{
Console.WriteLine("图像读取失败,请检查路径是否正确");
return;
}
PaddleOcrResult result = ocr.Run(src);
float scoreThreshold = 0.6f;
Console.WriteLine($"共识别到 {result.Regions.Length} 个文本区域(过滤前)");
Console.WriteLine($"置信度阈值:{scoreThreshold:P0}");
Console.WriteLine(new string('-', 60));
var validRegions = result.Regions
.Where(r => !float.IsNaN(r.Score) && r.Score >= scoreThreshold)
.OrderBy(r => r.Rect.Center.Y) // 按 Y 坐标排序,模拟从上到下阅读顺序
.ThenBy(r => r.Rect.Center.X) // 同行内按 X 坐标从左到右
.ToList();
Console.WriteLine($"过滤后有效区域:{validRegions.Count} 个\n");
foreach (var region in validRegions)
{
Console.WriteLine($" 文本:{region.Text}");
Console.WriteLine($" 置信度:{region.Score:P2}");
Console.WriteLine($" 位置:Center=({region.Rect.Center.X:F0}, {region.Rect.Center.Y:F0})");
Console.WriteLine();
}
Console.WriteLine("=== 完整识别文本(过滤后拼接)===");
Console.WriteLine(string.Join("\n", validRegions.Select(r => r.Text)));
}
}
}
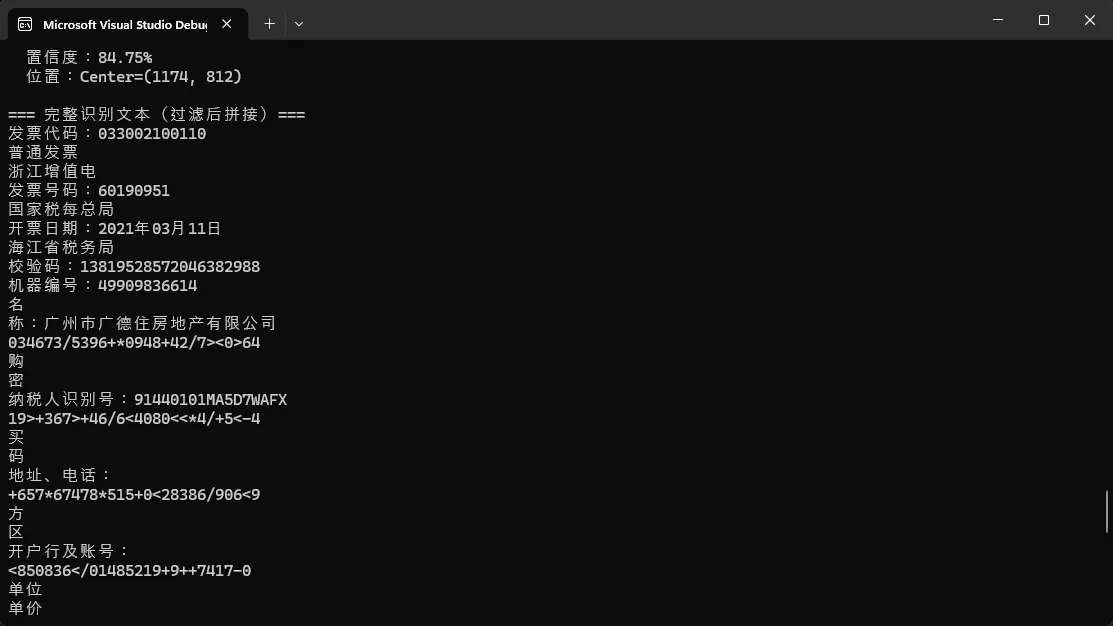
在我实际测试的环境中(Intel i7-12700,.NET 10,MKL 运行时),处理一张 A4 尺寸的发票图片(约 2000×2800 像素),首次推理耗时约 1.2 秒(含模型加载),后续推理稳定在 280~350ms 左右,对于大多数业务场景完全可以接受。
⚡ GPU 环境搭建:性能提升的进阶路线
如果需要处理高并发的图像识别请求,或者图片分辨率普遍较高,GPU 加速就值得投入了。GPU 模式下,同等图片的推理时间通常可以压缩到 CPU 的 1/5 ~ 1/10。不过,GPU 环境的搭建比 CPU 复杂不少,需要格外细心。
🎯 第一步:确认显卡架构,选择正确的运行时包
这是 GPU 配置中最容易出错的地方。PaddleSharp 的 GPU 运行时包按照 CUDA 版本和 GPU 架构(sm 后缀)进行了精细划分,选错了包装上去,推理会静默回退到 CPU 模式,甚至直接崩溃。
下表是选包的核心参考依据:
sm 后缀 | 对应显卡系列 | 典型型号举例 |
|---|---|---|
sm61 | GTX 10 系列 | GTX 1060、GTX 1080 Ti |
sm75 | RTX 20 系列 / GTX 16xx | RTX 2080、GTX 1660 Super |
sm86 | RTX 30 系列 | RTX 3070、RTX 3090 |
sm89 | RTX 40 系列 | RTX 4080、RTX 4090 |
sm120 | RTX 50 系列 | RTX 5090(仅 CUDA 12.9 支持) |
以 RTX 3080 为例,应该选择 Sdcb.PaddleInference.runtime.win64.cu126_cudnn95_sm86 或 cu129_cudnn910_sm86,而不是通用的 mkl 包。
bash# 以 RTX 30 系列 + CUDA 12.6 为例
dotnet add package Sdcb.PaddleInference
dotnet add package Sdcb.PaddleInference.runtime.win64.cu126_cudnn95_sm86
dotnet add package Sdcb.PaddleOCR
dotnet add package Sdcb.PaddleOCR.KnownModels
dotnet add package OpenCvSharp4
dotnet add package OpenCvSharp4.runtime.win
🎯 第二步:配置 CUDA 环境变量
安装完 NuGet 包之后,还需要在系统层面准备好 CUDA 运行时环境。依次安装:
- NVIDIA 显卡驱动(确保版本支持目标 CUDA 版本)
- CUDA Toolkit(从 NVIDIA 官网下载,与 NuGet 包的
cu*版本对应) - cuDNN(解压后将
bin、include、lib目录合并到 CUDA 安装目录)
安装完成后,确认 PATH 环境变量中包含 CUDA 的 bin 目录,例如:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.6\bin
🎯 第三步:GPU 推理代码配置
代码层面的改动其实非常小,只需要把设备配置从 PaddleDevice.Mkldnn() 换成 PaddleDevice.Gpu():
csharpusing Sdcb.PaddleInference;
using Sdcb.PaddleOCR;
using Sdcb.PaddleOCR.Models.Local;
using OpenCvSharp;
// GPU 设备配置
// 参数 0 表示使用第一块 GPU(多卡环境可指定其他序号)
// initialMemoryMB 指定初始显存分配量,默认 500MB
using var ocr = new PaddleOcrAll(LocalFullModels.ChineseV4, PaddleDevice.Gpu(gpuId: 0))
{
AllowRotateDetection = true
};
string imagePath = @"C:\test\invoice.jpg";
using Mat src = Cv2.ImRead(imagePath, ImreadModes.Color);
PaddleOcrResult result = ocr.Run(src);
Console.WriteLine(result.Text);
在 RTX 3080 + CUDA 12.6 环境下,同一张发票图片的推理时间可以降至 40~60ms,相比 CPU MKL 模式提升约 5~7 倍,在高并发批处理场景下效果更为显著。
🛠️ OpenCvSharp4 的角色与常见坑
在整个 PaddleSharp 生态里,OpenCvSharp4 扮演的是图像数据载体的角色,而不是算法引擎。PaddleOCR 的输入输出都基于 OpenCvSharp 的 Mat 对象,所以这个包是必须的,但它的安装也有几个容易忽略的细节。
坑一:只装了 OpenCvSharp4,忘了装 OpenCvSharp4.runtime.win。 前者只包含 .NET 托管层的封装,后者才包含 Windows 平台的原生 OpenCvSharpExtern.dll。缺少运行时包,程序会在启动时抛出 DllNotFoundException: Unable to load DLL 'OpenCvSharpExtern'。
坑二:Windows Server 环境缺少 Media Foundation。 如果部署在 Windows Server 2012 R2 等精简版服务器上,OpenCvSharp 在处理某些图像格式时会因为缺少 Media Foundation 组件而失败。解决方案是通过服务器管理器安装"媒体基础"功能组件,或者改用 Cv2.ImDecode 从字节数组读取图像,规避对 Media Foundation 的直接依赖。
坑三:老旧 CPU 不支持 AVX 指令集。 如果运行环境的 CPU 不支持 AVX2(比如某些 Xeon E5 系列),应该选择 Sdcb.PaddleInference.runtime.win64.openblas-noavx 而不是 MKL 版本,并在代码中使用 PaddleDevice.Openblas() 替代 PaddleDevice.Mkldnn()。
🔄 四种推理设备的横向对比
PaddleSharp 支持四种推理后端,适用场景各有侧重:
| 设备类型 | 对应 API | 适用场景 | 性能参考 |
|---|---|---|---|
| MKL(Intel oneDNN) | PaddleDevice.Mkldnn() | 主流 Intel/AMD CPU,推荐首选 | 基准 |
| OpenBLAS | PaddleDevice.Openblas() | 老旧 CPU 或低内存环境 | 约 MKL 的 60~70% |
| ONNX Runtime | PaddleDevice.Onnx() | 轻量部署,内存占用更低 | 与 MKL 相当 |
| GPU(CUDA) | PaddleDevice.Gpu() | 高并发、大图处理 | 约 MKL 的 5~10 倍 |
测试环境:Intel i7-12700 / RTX 3080,.NET 8,图像尺寸 2000×2800px,单张推理耗时。
🚨 踩坑预警:这些错误 90% 的人都会遇到
错误一:同时安装了 CPU 和 GPU 运行时包。 这是最高频的错误,症状是程序运行时抛出 BadImageFormatException 或原生库加载冲突。解决方案:在 .csproj 中确保只保留一个 Sdcb.PaddleInference.runtime.* 包,CPU 和 GPU 包绝对互斥。
错误二:GPU 包的 sm 后缀与显卡不匹配。 比如 RTX 3090 装了 sm89(RTX 40 系列专用),推理会静默降回 CPU 模式,不会报错,但速度毫无提升。一定要对照显卡型号选择正确的 sm 后缀。
错误三:Linux 部署忘记设置 LD_LIBRARY_PATH。 Linux 系统无法在运行时动态修改 LD_LIBRARY_PATH,需要在启动脚本中手动指定:
bashexport LD_LIBRARY_PATH=./bin/Release/net8.0/runtimes/linux-x64/native:$LD_LIBRARY_PATH
dotnet YourApp.dll
错误四:模型文件路径问题。 使用 LocalFullModels 系列时,首次运行会自动下载模型文件到本地缓存目录。如果网络受限或缓存目录权限不足,会导致静默失败。可以提前手动下载模型,或者在代码中指定自定义的模型目录路径。
💡 三个可直接落地的技术洞察
"PaddleSharp 的包设计是分层的,不是叠加的——理解这一点,环境问题就解决了一半。"
"CPU 和 GPU 运行时包的互斥关系,不是建议,是硬性约束,同时存在必然崩溃。"
"OpenCvSharp4 在这里只是图像数据的载体,
runtime.win包才是它真正能跑起来的前提。"
🎯 结语
PaddleSharp 把百度飞桨强大的推理能力带进了 .NET 生态,让 C# 开发者不必绕道 Python 就能享受到工业级 OCR 和目标检测能力。它的环境搭建之所以让很多人头疼,根本原因在于"分层包设计"这个概念和传统 NuGet 包的使用习惯有所不同。
理清了三层依赖模型,搞懂了 CPU/GPU 运行时的互斥关系,再注意 OpenCvSharp4 运行时包和 AVX 指令集兼容性这两个细节,整个搭建过程其实非常顺畅。本文提供的 .csproj 模板和代码示例均经过实际验证,可以直接作为新项目的起点。
后续如果需要深入,可以沿着这条路径继续探索:模型精度调优 → 批量推理优化 → 自定义模型接入 → 生产环境容器化部署,每一步都有很大的挖掘空间。
💬 欢迎在评论区分享你在 PaddleSharp 环境搭建中遇到的问题,或者你在实际项目中的使用经验——说不定你踩过的坑,正是别人正在面对的。
#标签: C# PaddleSharp PaddleOCR OpenCvSharp NuGet包管理 图像识别 .NET开发 性能优化
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!