
目录
不是危言耸听。我见过太多 Python 项目,数据访问层写得像一锅乱炖——User 有 UserDAO,Order 有 OrderService 里夹着 SQL,Product 直接在路由里
db.query()。三个月后,没人敢动那块代码。
🤔 先聊聊,你的项目是不是这个样子
新需求来了,产品说:"用户列表加个按邮箱搜索的功能。"
你打开代码,发现 db.query(User).filter(...) 散落在五个不同的文件里。改一处,不知道还有几处。测试?不存在的,那些查询跟 Session 耦合得死死的,根本 mock 不了。
这不是个例。这是绝大多数 Python Web 项目在"快速迭代"压力下的真实状态。
问题出在哪?数据访问逻辑没有被正经地收纳起来。
🧱 仓储模式(Repository Pattern)到底解决什么
说白了,仓储模式干的事情就一件——把"怎么存取数据"这件事,从业务逻辑里彻底抽离出来。
你的 Service 层不需要知道底层是 SQLite 还是 PostgreSQL,不需要知道用的是 ORM 还是原生 SQL。它只管调 user_repo.get_by_email(email),至于这个方法内部怎么实现,那是 Repository 的事。
这个边界,看起来是多此一举,实际上是项目能不能活过一年的关键。
🧬 泛型仓储:一次编写,处处复用
普通仓储模式已经不错了,但还有个问题:User 需要 get_by_id、add、delete,Order 也需要,Product 也需要。这些基础 CRUD,你要写多少遍?
泛型仓储(Generic Repository)的思路是:把共性的东西抽到基类,差异化的留给子类。
用 Python 的 Generic[T] 实现起来相当优雅——
pythonfrom typing import TypeVar, Generic, Type, Optional, List, Any
from sqlalchemy.orm import Session
from sqlalchemy import inspect
ModelType = TypeVar("ModelType")
class BaseRepository(Generic[ModelType]):
def __init__(self, model: Type[ModelType], db: Session):
self.model = model
self.db = db
def _get_pk_name(self) -> str:
# 自动探测主键,不硬编码字段名
return inspect(self.model).primary_key[0].name
def get_by_id(self, entity_id: Any) -> Optional[ModelType]:
pk = self._get_pk_name()
return (
self.db.query(self.model)
.filter(getattr(self.model, pk) == entity_id)
.first()
)
def add(self, entity: ModelType) -> ModelType:
self.db.add(entity)
self.db.flush() # 生成 ID,但不提交——事务控制权留给调用方
self.db.refresh(entity)
return entity
def delete(self, entity_id: Any) -> bool:
entity = self.get_by_id(entity_id)
if entity:
self.db.delete(entity)
return True
return False
注意 flush() 而不是 commit()——这个细节很多人踩坑。flush 把操作同步到数据库会话,但事务还没提交。这样做的好处是:调用方可以把多个仓储操作包在同一个事务里,要么全成功,要么全回滚。 如果在仓储内部 commit(),你就把事务控制权拱手相让了。
🔧 子类只写"特有"的东西
基类搞定通用 CRUD 之后,UserRepository 就只需要关心 User 独有的查询逻辑:
pythonfrom sqlalchemy import or_
from models import User
from repositories.base import BaseRepository
class UserRepository(BaseRepository[User]):
def __init__(self, db: Session):
super().__init__(User, db)
def get_by_username(self, username: str) -> Optional[User]:
return (
self.db.query(User)
.filter(User.username == username)
.first()
)
def search(self, keyword: str, skip: int = 0, limit: int = 50):
"""用户名和邮箱的模糊搜索,ilike 保证大小写不敏感"""
return (
self.db.query(User)
.filter(
or_(
User.username.ilike(f"%{keyword}%"),
User.email.ilike(f"%{keyword}%"),
)
)
.offset(skip).limit(limit).all()
)
def exists_by_username(self, username: str) -> bool:
return self.get_by_username(username) is not None
干净。每个方法只做一件事,看名字就知道干什么。
🖥️ 用 Tkinter 把它跑起来
光看代码不过瘾,咱们做个能跑的桌面 GUI——用 Tkinter 驱动上面这套仓储层,实现用户的增删改查和模糊搜索。
整个项目结构如下:
tkinter_repo_demo/ ├── main.py # Tkinter 界面入口 ├── database.py # SQLAlchemy 引擎配置 ├── models.py # User ORM 模型 └── repositories/ ├── base.py # 泛型基类 └── user_repo.py # User 专属仓储
📦 数据库初始化(database.py)
pythonfrom sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker, declarative_base
engine = create_engine(
"sqlite:///./demo.db",
connect_args={"check_same_thread": False},
)
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
Base = declarative_base()
def init_db():
from models import User
Base.metadata.create_all(bind=engine)
🗂️ 模型定义(models.py)
pythonfrom sqlalchemy import Column, Integer, String, Boolean, DateTime
from sqlalchemy.sql import func
from database import Base
class User(Base):
__tablename__ = "users"
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(64), unique=True, nullable=False)
email = Column(String(128), unique=True, nullable=False)
is_active = Column(Boolean, default=True)
created_at = Column(DateTime(timezone=True), server_default=func.now())
🎨 界面核心逻辑(main.py 节选)
界面分两块:左边是带斑马纹的数据表格,右边是操作表单。点击某一行,表单自动填充——这个联动靠 <<TreeviewSelect>> 事件实现。
pythondef _on_row_select(self, _event):
selected = self.tree.selection()
if not selected:
return
uid = int(selected[0])
repo, db = make_repo()
try:
user = repo.get_by_id(uid) # 调仓储,不写裸 SQL
finally:
db.close()
if user:
self.form_vars["username"].set(user.username)
self.form_vars["email"].set(user.email)
self.form_vars["is_active"].set(user.is_active)
新增用户时,先通过仓储做唯一性校验,再写入:
pythondef _do_add(self):
username = self.form_vars["username"].get().strip()
email = self.form_vars["email"].get().strip()
repo, db = make_repo()
try:
if repo.exists_by_username(username):
messagebox.showerror("错误", f"用户名「{username}」已存在")
return
new_user = User(username=username, email=email,
is_active=self.form_vars["is_active"].get())
repo.add(new_user)
db.commit() # commit 在 UI 层做,仓储只管 flush
except Exception as e:
db.rollback()
messagebox.showerror("数据库错误", str(e))
finally:
db.close()
self._refresh_table()
搜索框的逻辑更简单,直接透传给 repo.search():
pythondef _do_search(self):
keyword = self.search_var.get().strip()
repo, db = make_repo()
try:
results = repo.search(keyword)
finally:
db.close()
self._refresh_table(results)
UI 层完全不知道 SQL 长什么样。 这就是仓储模式的价值所在。
🖼️运行效果
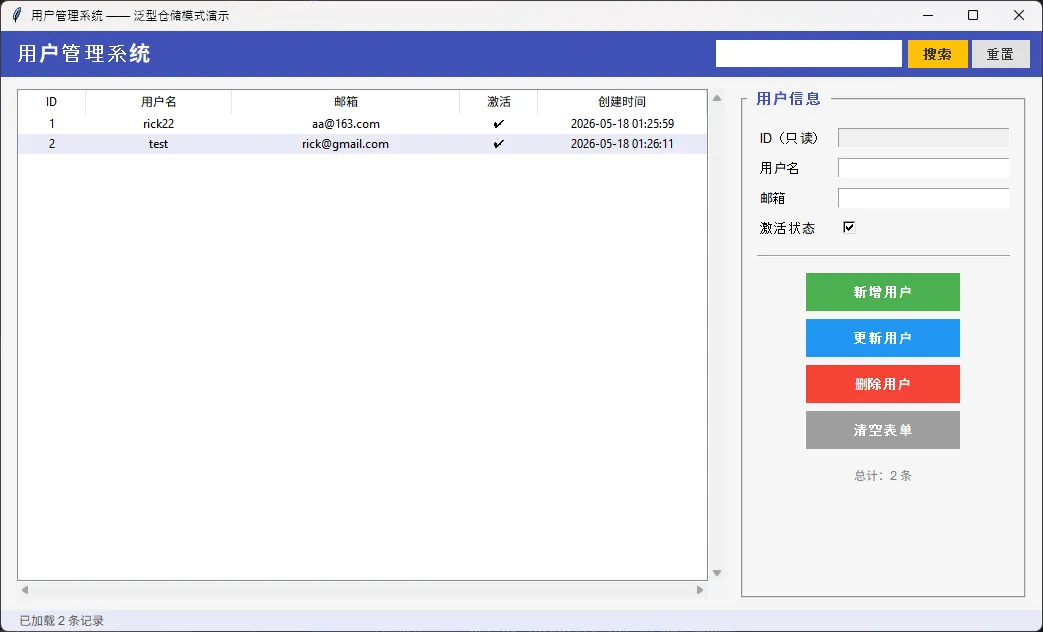
⚠️ 三个容易踩的坑,提前说清楚
第一个:Session 生命周期管理。 Tkinter 是单线程事件驱动,不像 FastAPI 那样有请求级别的 Session 自动回收。我在示例里用的是"每次操作新建 Session、用完立即关闭"的策略——简单粗暴,但可靠。如果你嫌频繁创建 Session 有性能开销,可以考虑连接池,但别把同一个 Session 当全局变量用,那是定时炸弹。
第二个:flush 和 commit 的边界。 仓储内部只 flush,commit 和 rollback 交给调用方。这个约定要在团队里明确,否则有人在仓储里偷偷 commit,事务就乱了。
第三个:delete_many 的 synchronize_session=False。 批量删除时用这个参数可以跳过 ORM 的对象同步,性能更好。但代价是——删完之后内存里那些对象的状态不会自动更新。如果删完还要用那些对象,记得手动处理或者重新查询。
📐 这套模式适合哪些场景
说实话,不是所有项目都需要这么搞。
如果你在写一个百来行的脚本,或者原型验证阶段,直接裸写 SQLAlchemy 查询完全没问题,过度设计反而是负担。
但只要满足以下任意一条,泛型仓储就值得引入:
- 项目有 5 个以上的数据模型,且都需要基础 CRUD
- 需要写单元测试,且希望 mock 掉数据库层
- 团队协作,需要明确的代码分层边界
- 未来可能替换数据库或 ORM 框架
💬 最后说一句
设计模式不是银弹,也不是炫技工具。泛型仓储模式真正的价值,在于它给了你一个可以信任的边界——业务逻辑这边,数据访问那边,互不越界。
代码写得久了你会发现:让人崩溃的从来不是复杂的业务逻辑,而是那些藏在各个角落、改一处不知道还有几处的数据库查询。
把那些查询收进仓储,是对未来的自己负责。
#Python #SQLAlchemy #设计模式 #后端开发 #代码架构
相关信息
我用夸克网盘给你分享了「repoDemo.zip」,点击链接或复制整段内容,打开「夸克APP」即可获取。
/33cb3Yf8Qn:/
链接:https://pan.quark.cn/s/c7af5f621c39
提取码:DiUu
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!