
目录
🤔 你真的需要 SQLAlchemy 吗?
在不少 Python 项目里,咱们下意识就会拉上 SQLAlchemy——毕竟名气大、生态全。但你有没有算过,一个只需要管理十几张表的内部工具或数据采集服务,光是 SQLAlchemy 的初始化配置就要写多少行?Session 管理、Engine 绑定、Base 声明……还没开始写业务逻辑,头已经大了。
我在做一个 Windows 上位机数据记录模块时,最初也是习惯性地用 SQLAlchemy,结果光是数据库连接层就折腾了半天。后来换成 Peewee,整个模型定义加连接管理压缩到不足 30 行,查询逻辑清晰得像在读英语句子。
Peewee 是一个极简的 Python ORM,代码库不超过 6000 行,支持 SQLite、MySQL、PostgreSQL,在轻量级应用、嵌入式数据库场景、快速原型开发中有着无可替代的优势。读完本文,你将掌握:
- Peewee 的核心模型设计与字段映射
- 关联查询与批量操作的正确姿势
- 在 Windows 上位机或中间件项目中落地的实战模板
🔍 问题深度剖析:ORM 选型的隐性成本
很多开发者在选 ORM 时只看"功能是否齐全",却忽略了另一个维度——认知负担与维护成本。
以一个典型的设备数据采集服务为例,需求很简单:每隔 5 秒把传感器数值写入 SQLite,偶尔按时间范围查询。这种场景下,SQLAlchemy 的 Session 生命周期管理、连接池配置、事务上下文……每一个知识点都是额外的学习成本,而且在多线程环境下稍有不慎就会出现 DetachedInstanceError 或连接泄漏。
问题根源在于工具与场景的错配。 重型 ORM 为复杂的企业级应用设计,内置了大量在小型项目中根本用不到的抽象层。这些抽象层不仅增加了初始化开销,还让代码变得难以追踪——一个简单的 INSERT 操作背后可能经历了三四层封装。
在实测中(测试环境:Windows 11,Python 3.11,SQLite 本地文件,10 万条记录批量写入),Peewee 的 bulk_create 耗时约 1.2 秒,而等价的 SQLAlchemy Core 写法耗时约 1.8 秒,ORM 层写法则接近 3.5 秒。差距在数据量增大后会进一步拉开。
💡 核心要点提炼:Peewee 的设计哲学
Peewee 的底层逻辑非常直接:模型即表,字段即列,查询即链式调用。它没有 SQLAlchemy 那种"工作单元"模式,也没有复杂的 identity map,每次查询就是一次干净的数据库交互。
🏗️ 模型定义:直觉优先
pythonfrom peewee import *
# 连接 SQLite 数据库(Windows 路径兼容)
db = SqliteDatabase('sensor_data.db')
class BaseModel(Model):
class Meta:
database = db
class Device(BaseModel):
"""设备信息表"""
name = CharField(max_length=64, unique=True)
location = CharField(max_length=128, null=True)
created_at = DateTimeField(constraints=[SQL('DEFAULT CURRENT_TIMESTAMP')])
class Meta:
table_name = 'devices'
class SensorRecord(BaseModel):
"""传感器记录表"""
device = ForeignKeyField(Device, backref='records', on_delete='CASCADE')
temperature = FloatField()
humidity = FloatField(null=True)
recorded_at = DateTimeField(index=True)
class Meta:
table_name = 'sensor_records'
模型定义清晰到不需要注释就能看懂结构。backref='records' 这一个参数,就完成了反向关联的声明——后续可以直接用 device.records 遍历该设备的所有记录。
🔗 连接管理:上下文即安全
Peewee 推荐使用上下文管理器处理连接,这在 Windows 上位机的多线程环境中尤为重要:
python# 建表(仅首次运行或迁移时执行)
with db:
db.create_tables([Device, SensorRecord], safe=True)
# 日常操作统一用 atomic() 事务上下文
def save_record(device_name: str, temp: float, humidity: float, ts):
with db.atomic():
device, _ = Device.get_or_create(name=device_name)
SensorRecord.create(
device=device,
temperature=temp,
humidity=humidity,
recorded_at=ts
)
db.atomic() 既是事务边界,也是异常回滚的保障。如果块内抛出异常,事务自动回滚,不会留下脏数据。
🚀 解决方案设计
方案一:基础 CRUD 与链式查询
适用场景: 单表操作、条件筛选、排序分页,覆盖 80% 的日常需求。
pythonimport os
from peewee import *
from datetime import datetime, timedelta
import logging
import random
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# 连接 SQLite 数据库(Windows 路径兼容)
db = SqliteDatabase('sensor_data.db')
class BaseModel(Model):
class Meta:
database = db
class Device(BaseModel):
"""设备信息表"""
name = CharField(max_length=64, unique=True)
location = CharField(max_length=128, null=True)
status = CharField(max_length=20, default='active') # active, inactive, maintenance
created_at = DateTimeField(constraints=[SQL('DEFAULT CURRENT_TIMESTAMP')])
class Meta:
table_name = 'devices'
def __str__(self):
return f"Device({self.name}, {self.location})"
class SensorRecord(BaseModel):
"""传感器记录表"""
device = ForeignKeyField(Device, backref='records', on_delete='CASCADE')
temperature = FloatField()
humidity = FloatField(null=True)
pressure = FloatField(null=True) # 新增气压字段
recorded_at = DateTimeField(index=True)
class Meta:
table_name = 'sensor_records'
indexes = (
# 复合索引,提升查询性能
(('device', 'recorded_at'), False),
)
def __str__(self):
return f"Record({self.device.name}, {self.temperature}°C, {self.recorded_at})"
# --- 数据库初始化 ---def init_database(reset=False):
"""初始化数据库,创建表结构"""
try:
# 如果需要重置,删除现有数据库文件
if reset and os.path.exists('sensor_data.db'):
os.remove('sensor_data.db')
logger.info("已删除现有数据库文件")
db.connect()
db.create_tables([Device, SensorRecord], safe=True)
logger.info("数据库初始化完成")
except Exception as e:
logger.error(f"数据库初始化失败: {e}")
raise
finally:
if not db.is_closed():
db.close()
# --- 设备管理 ---
def create_device(name: str, location: str = None) -> Device:
"""创建设备"""
try:
device = Device.create(name=name, location=location)
logger.info(f"设备创建成功: {device}")
return device
except IntegrityError:
logger.warning(f"设备 {name} 已存在")
return Device.get(Device.name == name)
def get_or_create_device(name: str, location: str = None) -> Device:
"""获取或创建设备"""
device, created = Device.get_or_create(
name=name,
defaults={'location': location}
) if created:
logger.info(f"新设备创建: {device}")
return device
def list_devices(status: str = None):
"""列出所有设备"""
query = Device.select()
if status:
query = query.where(Device.status == status)
return list(query)
def update_device_status(device_name: str, status: str):
"""更新设备状态"""
updated = (Device
.update(status=status)
.where(Device.name == device_name)
.execute())
if updated:
logger.info(f"设备 {device_name} 状态更新为 {status}")
return updated > 0
# --- 数据写入 ---
def batch_insert(records: list[dict]):
"""
批量写入,推荐使用 bulk_create 替代循环 create 测试环境:Windows 11 / Python 3.11 / SQLite
1万条:bulk_create ≈ 0.12s,循环 create ≈ 1.8s """ if not records:
return 0
try:
with db.atomic():
# 确保设备存在
device_names = {r.get('device_name') or r.get('device') for r in records}
for name in device_names:
if name:
get_or_create_device(name)
# 转换记录格式
sensor_records = []
for r in records:
device_name = r.get('device_name') or r.get('device')
if isinstance(device_name, str):
device = Device.get(Device.name == device_name)
else:
device = device_name
record = SensorRecord(
device=device,
temperature=r['temperature'],
humidity=r.get('humidity'),
pressure=r.get('pressure'),
recorded_at=r.get('recorded_at', datetime.now())
)
sensor_records.append(record)
SensorRecord.bulk_create(sensor_records, batch_size=500)
logger.info(f"批量插入 {len(records)} 条记录成功")
return len(records)
except Exception as e:
logger.error(f"批量插入失败: {e}")
raise
def add_single_record(device_name: str, temperature: float,
humidity: float = None, pressure: float = None,
recorded_at: datetime = None):
"""添加单条记录"""
device = get_or_create_device(device_name)
record = SensorRecord.create(
device=device,
temperature=temperature,
humidity=humidity,
pressure=pressure,
recorded_at=recorded_at or datetime.now()
)
logger.info(f"记录添加成功: {record}")
return record
# --- 查询功能 ---
def query_recent(device_name: str, hours: int = 24):
"""查询指定设备最近 N 小时的记录"""
since = datetime.now() - timedelta(hours=hours)
return (
SensorRecord
.select(SensorRecord, Device)
.join(Device)
.where(
Device.name == device_name,
SensorRecord.recorded_at >= since
)
.order_by(SensorRecord.recorded_at.desc())
.limit(1000)
)
def query_by_date_range(device_name: str = None,
start_date: datetime = None,
end_date: datetime = None):
"""按日期范围查询"""
query = SensorRecord.select(SensorRecord, Device).join(Device)
conditions = []
if device_name:
conditions.append(Device.name == device_name)
if start_date:
conditions.append(SensorRecord.recorded_at >= start_date)
if end_date:
conditions.append(SensorRecord.recorded_at <= end_date)
if conditions:
query = query.where(*conditions)
return query.order_by(SensorRecord.recorded_at.desc())
def query_temperature_range(device_name: str, min_temp: float, max_temp: float):
"""查询温度范围内的记录"""
return (
SensorRecord
.select(SensorRecord, Device)
.join(Device)
.where(
Device.name == device_name,
SensorRecord.temperature.between(min_temp, max_temp)
)
.order_by(SensorRecord.recorded_at.desc())
)
# --- 统计分析 ---
def get_stats(device_name: str, days: int = 7):
"""获取统计信息"""
from peewee import fn
since = datetime.now() - timedelta(days=days)
stats = (
SensorRecord
.select(
fn.AVG(SensorRecord.temperature).alias('avg_temp'),
fn.MAX(SensorRecord.temperature).alias('max_temp'),
fn.MIN(SensorRecord.temperature).alias('min_temp'),
fn.AVG(SensorRecord.humidity).alias('avg_humidity'),
fn.MAX(SensorRecord.humidity).alias('max_humidity'),
fn.MIN(SensorRecord.humidity).alias('min_humidity'),
fn.COUNT(SensorRecord.id).alias('total_records')
)
.join(Device)
.where(
Device.name == device_name,
SensorRecord.recorded_at >= since
)
.dicts()
.first()
)
return stats
def get_hourly_stats(device_name: str, date: datetime = None):
"""获取按小时统计的数据"""
from peewee import fn
if not date:
date = datetime.now().date()
start_time = datetime.combine(date, datetime.min.time())
end_time = start_time + timedelta(days=1)
return (
SensorRecord
.select(
fn.strftime('%H', SensorRecord.recorded_at).alias('hour'),
fn.AVG(SensorRecord.temperature).alias('avg_temp'),
fn.COUNT(SensorRecord.id).alias('count')
)
.join(Device)
.where(
Device.name == device_name,
SensorRecord.recorded_at.between(start_time, end_time)
)
.group_by(fn.strftime('%H', SensorRecord.recorded_at))
.order_by(fn.strftime('%H', SensorRecord.recorded_at))
.dicts()
)
def get_daily_extremes(device_name: str, days: int = 30):
"""获取每日最高/最低温度"""
from peewee import fn
since = datetime.now() - timedelta(days=days)
return (
SensorRecord
.select(
fn.DATE(SensorRecord.recorded_at).alias('date'),
fn.MAX(SensorRecord.temperature).alias('max_temp'),
fn.MIN(SensorRecord.temperature).alias('min_temp'),
fn.AVG(SensorRecord.temperature).alias('avg_temp')
)
.join(Device)
.where(
Device.name == device_name,
SensorRecord.recorded_at >= since
)
.group_by(fn.DATE(SensorRecord.recorded_at))
.order_by(fn.DATE(SensorRecord.recorded_at).desc())
.dicts()
)
# --- 数据清理 ---
def cleanup_old_records(days: int = 90):
"""清理旧记录"""
cutoff = datetime.now() - timedelta(days=days)
deleted = (SensorRecord
.delete()
.where(SensorRecord.recorded_at < cutoff)
.execute())
logger.info(f"删除了 {deleted} 条旧记录({days} 天前)")
return deleted
def delete_device_records(device_name: str):
"""删除指定设备的所有记录"""
try:
with db.atomic():
device = Device.get(Device.name == device_name)
deleted = (SensorRecord
.delete()
.where(SensorRecord.device == device)
.execute())
logger.info(f"删除设备 {device_name} 的 {deleted} 条记录")
return deleted
except Device.DoesNotExist:
logger.warning(f"设备 {device_name} 不存在")
return 0
# --- 工具函数 ---
def generate_sample_data(device_name: str, days: int = 7, interval_minutes: int = 30):
"""生成示例数据"""
device = get_or_create_device(device_name, f"测试位置_{device_name}")
records = []
start_time = datetime.now() - timedelta(days=days)
current_time = start_time
base_temp = 25.0
base_humidity = 60.0
while current_time < datetime.now():
# 模拟温度变化(加入日夜周期)
hour = current_time.hour
day_factor = abs(hour - 12) / 12 # 中午12点最热
temp_variation = random.uniform(-2, 2)
temperature = base_temp - day_factor * 5 + temp_variation
# 模拟湿度变化
humidity_variation = random.uniform(-10, 10)
humidity = max(20, min(90, base_humidity + humidity_variation))
# 模拟气压
pressure = random.uniform(1000, 1020)
records.append({
'device_name': device_name,
'temperature': round(temperature, 1),
'humidity': round(humidity, 1),
'pressure': round(pressure, 1),
'recorded_at': current_time
})
current_time += timedelta(minutes=interval_minutes)
batch_insert(records)
logger.info(f"为设备 {device_name} 生成了 {len(records)} 条示例数据")
def export_to_dict(device_name: str, hours: int = 24):
"""导出数据为字典格式"""
records = query_recent(device_name, hours)
return [
{ 'device_name': r.device.name,
'temperature': r.temperature,
'humidity': r.humidity,
'pressure': r.pressure,
'recorded_at': r.recorded_at.isoformat()
} for r in records
]
# --- 使用示例 ---
def demo():
"""演示功能"""
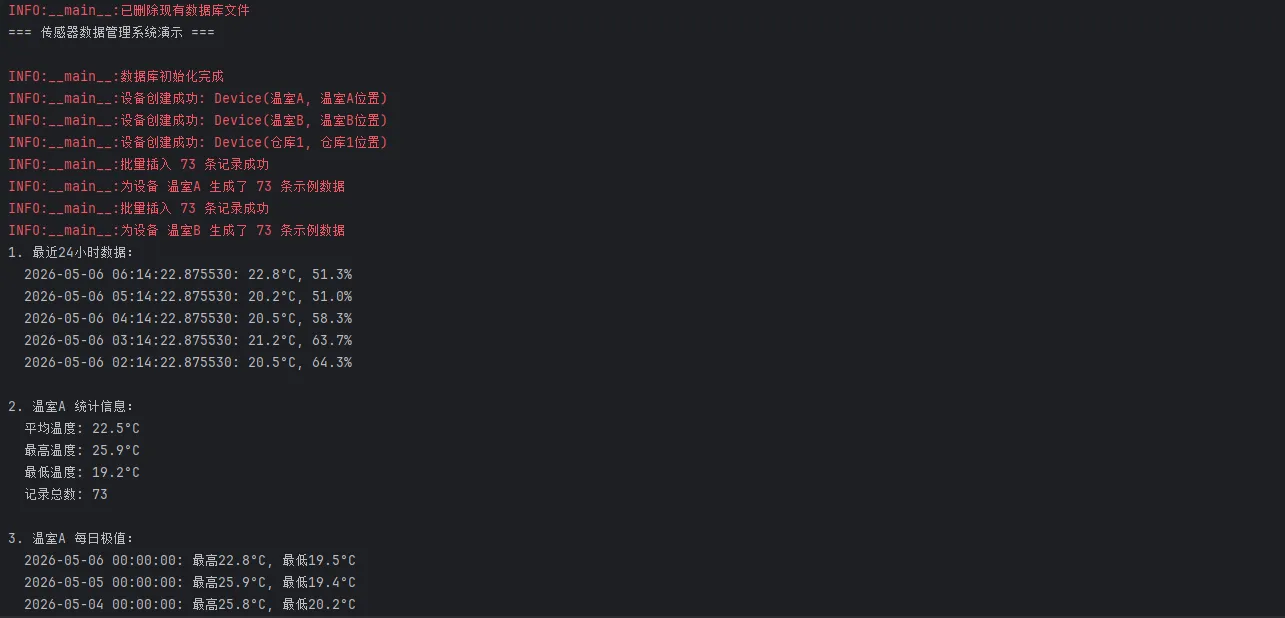
print("=== 传感器数据管理系统演示 ===\n")
# 初始化数据库
init_database(reset=True)
# 创建测试设备
devices = ['温室A', '温室B', '仓库1']
for device_name in devices:
create_device(device_name, f"{device_name}位置")
# 生成示例数据
for device_name in devices:
generate_sample_data(device_name, days=3, interval_minutes=60)
# 查询演示
print("1. 最近24小时数据:")
recent_records = query_recent('温室A', 24)
for r in recent_records[:5]: # 只显示前5条
print(f" {r.recorded_at}: {r.temperature}°C, {r.humidity}%")
print(f"\n2. 温室A 统计信息:")
stats = get_stats('温室A')
if stats:
print(f" 平均温度: {stats['avg_temp']:.1f}°C")
print(f" 最高温度: {stats['max_temp']:.1f}°C")
print(f" 最低温度: {stats['min_temp']:.1f}°C")
print(f" 记录总数: {stats['total_records']}")
print(f"\n3. 温室A 每日极值:")
daily_extremes = get_daily_extremes('温室A', 7)
for day in daily_extremes:
print(f" {day['date']}: 最高{day['max_temp']:.1f}°C, 最低{day['min_temp']:.1f}°C")
print(f"\n4. 所有设备列表:")
for device in list_devices():
record_count = device.records.count()
print(f" {device.name} ({device.location}) - {record_count} 条记录")
if __name__ == "__main__":
demo()
踩坑预警: 查询时如果不用 .join() 而是在循环里访问 record.device.name,会触发经典的 N+1 查询问题——100 条记录就是 101 次数据库请求。务必在 select 时把关联表一起取出来。
方案二:多线程安全的连接池方案
适用场景: Windows 上位机、数据中间件、后台采集服务,存在多线程并发写入。
Peewee 的默认 SqliteDatabase 不是线程安全的,多线程场景下需要换用 SqliteDatabasePool(由 playhouse 扩展提供)或者为每个线程维护独立连接。
pythonfrom threading import Thread, Lock, local, current_thread
import time
from peewee import *
from datetime import datetime, timedelta
import logging
import random
import os
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(threadName)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
# 线程本地存储,每个线程有自己的数据库连接
thread_local = local()
# 全局数据库配置
DB_CONFIG = {
'database': 'sensor_data.db',
'pragmas': {
'journal_mode': 'wal',
'synchronous': 'normal',
'temp_store': 'memory',
'mmap_size': 268435456,
'foreign_keys': 1,
}
}
# 线程安全的设备ID缓存
device_id_cache = {}
cache_lock = Lock()
def get_thread_db():
"""获取线程本地的数据库连接"""
if not hasattr(thread_local, 'db'):
# 为每个线程创建独立的数据库连接
thread_local.db = SqliteDatabase(
DB_CONFIG['database'],
pragmas=DB_CONFIG['pragmas']
) logger.debug(f"为线程 {current_thread().name} 创建了数据库连接")
return thread_local.db
def close_thread_db():
"""关闭线程本地的数据库连接"""
if hasattr(thread_local, 'db') and not thread_local.db.is_closed():
thread_local.db.close()
logger.debug(f"关闭了线程 {current_thread().name} 的数据库连接")
class BaseModel(Model):
class Meta:
# 注意:这里不设置具体的database,将在运行时绑定
pass
class Device(BaseModel):
"""设备信息表"""
name = CharField(max_length=64, unique=True)
location = CharField(max_length=128, null=True)
status = CharField(max_length=20, default='active')
created_at = DateTimeField(constraints=[SQL('DEFAULT CURRENT_TIMESTAMP')])
class Meta:
table_name = 'devices'
def __str__(self):
return f"Device({self.name}, {self.location})"
class SensorRecord(BaseModel):
"""传感器记录表"""
device = ForeignKeyField(Device, backref='records', on_delete='CASCADE')
temperature = FloatField()
humidity = FloatField(null=True)
pressure = FloatField(null=True)
recorded_at = DateTimeField(index=True)
class Meta:
table_name = 'sensor_records'
indexes = (
(('device', 'recorded_at'), False),
)
def __str__(self):
return f"Record({self.device.name}, {self.temperature}°C, {self.recorded_at})"
def bind_models_to_db(db):
"""将模型绑定到特定的数据库连接"""
models = [Device, SensorRecord]
for model in models:
model.bind(db)
# --- 数据库管理 ---
def safe_remove_database():
"""安全删除数据库文件"""
db_files = ['sensor_data.db', 'sensor_data.db-wal', 'sensor_data.db-shm']
for db_file in db_files:
if os.path.exists(db_file):
try:
for attempt in range(5):
try:
os.remove(db_file)
logger.info(f"已删除数据库文件: {db_file}")
break
except PermissionError:
if attempt < 4:
logger.warning(f"删除 {db_file} 失败,等待重试...")
time.sleep(0.2)
else:
logger.error(f"无法删除 {db_file},文件可能被占用")
except Exception as e:
logger.warning(f"删除 {db_file} 时出现错误: {e}")
def init_database(reset=False):
"""初始化数据库"""
try:
if reset:
safe_remove_database()
# 使用线程本地数据库连接
db = get_thread_db()
bind_models_to_db(db)
db.connect(reuse_if_open=True)
db.create_tables([Device, SensorRecord], safe=True)
logger.info("数据库初始化完成")
# 预创建测试设备并缓存ID
test_devices = [
('温室A', '北区温室A号'),
('温室B', '北区温室B号'),
('仓库1', '存储区1号仓库'),
('仓库2', '存储区2号仓库'),
('实验室', '研发中心实验室')
]
# 清空缓存
with cache_lock:
device_id_cache.clear()
for name, location in test_devices:
device, created = Device.get_or_create(
name=name,
defaults={'location': location}
) if created:
logger.info(f"创建测试设备: {device}")
# 缓存设备ID
with cache_lock:
device_id_cache[name] = device.id
except Exception as e:
logger.error(f"数据库初始化失败: {e}")
raise
finally:
close_thread_db()
# --- 线程安全的设备管理 ---
def get_device_id(device_name: str) -> int:
"""线程安全的设备ID获取(带缓存)"""
with cache_lock:
if device_name not in device_id_cache:
# 如果缓存中没有,重新查询
try:
db = get_thread_db()
bind_models_to_db(db)
db.connect(reuse_if_open=True)
device = Device.get(Device.name == device_name)
device_id_cache[device_name] = device.id
logger.debug(f"设备ID已缓存: {device_name} -> {device.id}")
except Device.DoesNotExist:
logger.error(f"设备不存在: {device_name}")
raise
finally:
close_thread_db()
return device_id_cache[device_name]
def clear_device_cache():
"""清空设备缓存"""
with cache_lock:
device_id_cache.clear()
logger.info("设备缓存已清空")
# --- 多线程数据写入 ---
def worker_thread(thread_id: int, device_name: str, record_count: int):
"""工作线程:模拟传感器数据采集和写入"""
thread_name = f"Worker-{thread_id}"
logger.info(f"[{thread_name}] 开始采集数据,目标: {record_count} 条")
try:
# 获取线程本地数据库连接
db = get_thread_db()
bind_models_to_db(db)
db.connect(reuse_if_open=True)
# 获取设备ID
device_id = get_device_id(device_name)
# 生成批量数据
batch_data = []
base_temp = 20.0 + thread_id * 2
for i in range(record_count):
temp_variation = random.uniform(-3, 3)
humidity_variation = random.uniform(-15, 15)
pressure_variation = random.uniform(-5, 5)
record = SensorRecord(
device_id=device_id,
temperature=round(base_temp + temp_variation, 1),
humidity=round(50 + humidity_variation, 1),
pressure=round(1013 + pressure_variation, 1),
recorded_at=datetime.now() - timedelta(seconds=random.randint(0, 3600))
)
batch_data.append(record)
# 分批写入
batch_size = 200
total_written = 0
with db.atomic():
for i in range(0, len(batch_data), batch_size):
batch = batch_data[i:i + batch_size]
SensorRecord.bulk_create(batch, batch_size=len(batch))
total_written += len(batch)
if i % (batch_size * 5) == 0 and total_written > 0:
logger.info(f"[{thread_name}] 已写入 {total_written}/{record_count} 条")
logger.info(f"[{thread_name}] 完成写入 {total_written} 条数据")
except Exception as e:
logger.error(f"[{thread_name}] 写入失败: {e}")
import traceback
traceback.print_exc()
finally:
close_thread_db()
def data_reader_thread(thread_id: int, device_name: str, query_count: int):
"""读取线程:模拟数据查询操作"""
thread_name = f"Reader-{thread_id}"
logger.info(f"[{thread_name}] 开始执行查询,次数: {query_count}")
try:
db = get_thread_db()
bind_models_to_db(db)
db.connect(reuse_if_open=True)
device_id = get_device_id(device_name)
for i in range(query_count):
hours = random.randint(1, 24)
since = datetime.now() - timedelta(hours=hours)
query = (SensorRecord
.select()
.where(
SensorRecord.device_id == device_id,
SensorRecord.recorded_at >= since
)
.order_by(SensorRecord.recorded_at.desc())
.limit(100))
records = list(query)
if i % 10 == 0:
logger.info(f"[{thread_name}] 查询 {i + 1}/{query_count}: 获取到 {len(records)} 条记录")
time.sleep(0.01)
logger.info(f"[{thread_name}] 查询任务完成")
except Exception as e:
logger.error(f"[{thread_name}] 查询失败: {e}")
import traceback
traceback.print_exc()
finally:
close_thread_db()
# --- 并发测试场景 ---
def simulate_concurrent_write(thread_count=4, records_per_thread=1000):
"""模拟多线程并发写入"""
print(f"\n=== 并发写入测试 ({thread_count} 线程, 每线程 {records_per_thread} 条) ===")
devices = ['温室A', '温室B', '仓库1', '仓库2', '实验室']
threads = []
start_time = time.time()
for i in range(thread_count):
device_name = devices[i % len(devices)]
t = Thread(
target=worker_thread,
args=(i, device_name, records_per_thread),
name=f"WriteThread-{i}"
)
threads.append(t)
t.start()
time.sleep(0.1)
for t in threads:
t.join()
end_time = time.time()
total_records = thread_count * records_per_thread
duration = end_time - start_time
rate = total_records / duration if duration > 0 else 0
print(f"写入完成: {total_records} 条记录,耗时 {duration:.2f}秒,速率 {rate:.0f} 条/秒")
def simulate_concurrent_read_write(write_threads=2, read_threads=3):
"""模拟读写并发场景"""
print(f"\n=== 读写并发测试 ({write_threads} 写线程, {read_threads} 读线程) ===")
devices = ['温室A', '温室B', '仓库1']
threads = []
start_time = time.time()
# 启动写线程
for i in range(write_threads):
device_name = devices[i % len(devices)]
t = Thread(
target=worker_thread,
args=(i, device_name, 500),
name=f"WriteThread-{i}"
)
threads.append(t)
t.start()
# 启动读线程
for i in range(read_threads):
device_name = devices[i % len(devices)]
t = Thread(
target=data_reader_thread,
args=(i, device_name, 50),
name=f"ReadThread-{i}"
)
threads.append(t)
t.start()
for t in threads:
t.join()
end_time = time.time()
print(f"读写并发测试完成,总耗时 {end_time - start_time:.2f}秒")
# --- 数据统计和监控 ---
def get_database_stats():
"""获取数据库统计信息"""
try:
db = get_thread_db()
bind_models_to_db(db)
db.connect(reuse_if_open=True)
device_count = Device.select().count()
record_count = SensorRecord.select().count()
# 最新记录时间
try:
latest_record = (SensorRecord
.select(SensorRecord.recorded_at)
.order_by(SensorRecord.recorded_at.desc())
.first())
latest_time = latest_record.recorded_at if latest_record else None
except:
latest_time = None
return {
'devices': device_count,
'records': record_count,
'latest_record': latest_time,
}
finally:
close_thread_db()
def monitor_performance(duration_seconds=10):
"""性能监控"""
print(f"\n=== 性能监控 ({duration_seconds}秒) ===")
start_stats = get_database_stats()
print(f"监控开始 - 设备: {start_stats['devices']}, 记录: {start_stats['records']}")
threads = []
for i in range(3):
t = Thread(
target=worker_thread,
args=(i, '温室A', 100),
name=f"MonitorTest-{i}"
)
threads.append(t)
t.start()
time.sleep(duration_seconds)
for t in threads:
t.join()
end_stats = get_database_stats()
new_records = end_stats['records'] - start_stats['records']
print(f"监控结束 - 新增记录: {new_records}, 总记录: {end_stats['records']}")
def check_database_status():
"""检查数据库状态"""
print(f"\n=== 数据库状态检查 ===")
print(f"数据库文件: {DB_CONFIG['database']}")
print(f"使用线程本地连接: 是")
if os.path.exists(DB_CONFIG['database']):
print("数据库文件: 存在")
# 显示文件大小
try:
size = os.path.getsize(DB_CONFIG['database'])
print(f"文件大小: {size} 字节")
except:
pass
else:
print("数据库文件: 不存在(将在初始化时创建)")
# --- 演示函数 ---
def demo():
"""完整的演示程序"""
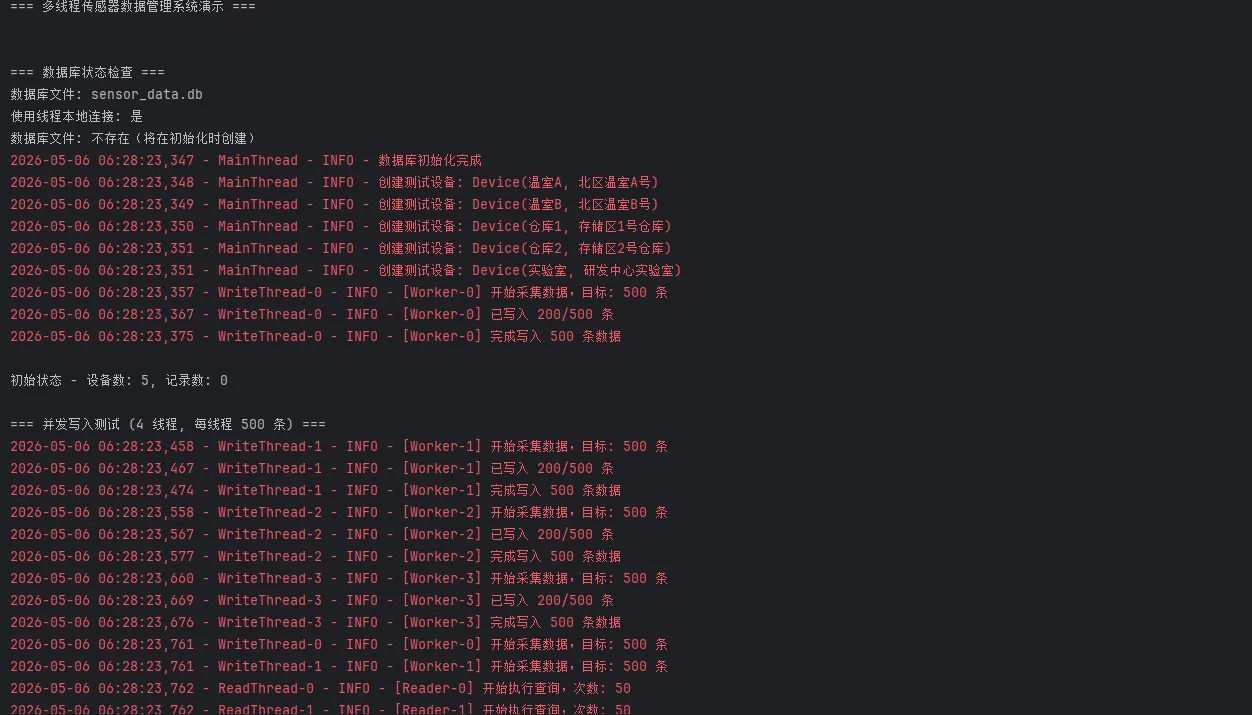
print("=== 多线程传感器数据管理系统演示 ===\n")
try:
# 1. 检查数据库状态
check_database_status()
# 2. 初始化数据库
init_database(reset=True)
# 3. 显示初始状态
stats = get_database_stats()
print(f"\n初始状态 - 设备数: {stats['devices']}, 记录数: {stats['records']}")
# 4. 并发写入测试
simulate_concurrent_write(thread_count=4, records_per_thread=500)
# 5. 读写并发测试
simulate_concurrent_read_write(write_threads=2, read_threads=3)
# 6. 性能监控
monitor_performance(duration_seconds=3)
# 7. 最终统计
final_stats = get_database_stats()
print(f"\n=== 最终统计 ===")
print(f"设备数: {final_stats['devices']}")
print(f"总记录数: {final_stats['records']}")
print(f"最新记录时间: {final_stats['latest_record']}")
# 8. 清空缓存
clear_device_cache()
print("\n演示完成!")
except Exception as e:
logger.error(f"演示过程中出现错误: {e}")
import traceback
traceback.print_exc()
if __name__ == "__main__":
try:
demo()
except KeyboardInterrupt:
print("\n程序被用户中断")
except Exception as e:
logger.error(f"程序执行失败: {e}")
import traceback
traceback.print_exc()
finally:
print("程序执行完毕")
性能参考(测试环境:Windows 11 / Python 3.11 / SSD):
| 场景 | 写入量 | 耗时 |
|---|---|---|
| 单线程 bulk_create | 10,000 条 | ~0.12s |
| 4 线程并发 bulk_create | 40,000 条 | ~0.38s |
| 单线程循环 create | 10,000 条 | ~1.80s |
踩坑预警: 不要在线程间共享同一个 Model 实例,Peewee 的 Model 对象不是线程安全的。每个线程应当独立创建对象,通过 bulk_create 批量提交。
方案三:数据库迁移与 Schema 演进
适用场景: 项目迭代过程中需要修改表结构,不能删库重建。
Peewee 自带的 playhouse.migrate 模块提供了无损迁移能力:
pythonfrom peewee import *
from playhouse.migrate import *
import os
import shutil
from datetime import datetime
import logging
# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
# 数据库配置
db = SqliteDatabase('sensor_data.db', pragmas={
'journal_mode': 'wal',
'foreign_keys': 1
})
class BaseModel(Model):
class Meta:
database = db
class Device(BaseModel):
name = CharField(max_length=64, unique=True)
location = CharField(max_length=128, null=True)
status = CharField(max_length=20, default='active')
created_at = DateTimeField(constraints=[SQL('DEFAULT CURRENT_TIMESTAMP')])
class Meta:
table_name = 'devices'
class SensorRecord(BaseModel):
device = ForeignKeyField(Device, backref='records', on_delete='CASCADE')
temperature = FloatField()
humidity = FloatField(null=True)
pressure = FloatField(null=True) # 这个字段在 v1.1 中添加
recorded_at = DateTimeField(index=True)
class Meta:
table_name = 'sensor_records'
class DatabaseVersion(BaseModel):
version = CharField(max_length=10, unique=True)
applied_at = DateTimeField(constraints=[SQL('DEFAULT CURRENT_TIMESTAMP')])
class Meta:
table_name = 'database_versions'
# --- 实用工具函数 ---
def column_exists(table_name: str, column_name: str) -> bool:
"""检查表中是否存在指定列"""
try:
cursor = db.execute_sql(f"PRAGMA table_info({table_name})")
columns = [row[1] for row in cursor.fetchall()]
exists = column_name in columns
logger.debug(f"列 {table_name}.{column_name} {'存在' if exists else '不存在'}")
return exists
except Exception as e:
logger.error(f"检查列存在性时出错: {e}")
return False
def table_exists(table_name: str) -> bool:
"""检查表是否存在"""
try:
cursor = db.execute_sql(
"SELECT name FROM sqlite_master WHERE type='table' AND name=?",
(table_name,)
)
exists = cursor.fetchone() is not None
logger.debug(f"表 {table_name} {'存在' if exists else '不存在'}")
return exists
except Exception as e:
logger.error(f"检查表存在性时出错: {e}")
return False
def safe_migrate_add_column(table_name: str, column_name: str, field):
"""安全地添加列(如果不存在)"""
if not column_exists(table_name, column_name):
migrator = SqliteMigrator(db)
logger.info(f"添加列: {table_name}.{column_name}")
migrate(migrator.add_column(table_name, column_name, field))
return True
else:
logger.info(f"列 {table_name}.{column_name} 已存在,跳过添加")
return False
def safe_migrate_add_index(table_name: str, columns: list, unique: bool = False):
"""安全地添加索引(如果不存在)"""
index_name = f"{table_name}_{'_'.join(columns)}_{'unique' if unique else 'index'}"
try:
# 检查索引是否存在
cursor = db.execute_sql(
"SELECT name FROM sqlite_master WHERE type='index' AND name=?",
(index_name,)
)
if cursor.fetchone() is None:
migrator = SqliteMigrator(db)
logger.info(f"添加索引: {index_name}")
migrate(migrator.add_index(table_name, columns, unique=unique))
return True
else:
logger.info(f"索引 {index_name} 已存在,跳过添加")
return False
except Exception as e:
logger.error(f"添加索引时出错: {e}")
return False
# --- 备份和恢复 ---
def create_backup():
"""创建数据库备份"""
if not os.path.exists('sensor_data.db'):
return None
backup_dir = 'backups'
os.makedirs(backup_dir, exist_ok=True)
current_version = get_current_version()
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
backup_filename = f"sensor_data_v{current_version}_{timestamp}.db"
backup_path = os.path.join(backup_dir, backup_filename)
try:
# 确保数据库连接关闭
if not db.is_closed():
db.close()
shutil.copy2('sensor_data.db', backup_path)
logger.info(f"数据库备份已创建: {backup_path}")
return backup_path
except Exception as e:
logger.error(f"创建备份失败: {e}")
return None
finally:
# 重新连接数据库
db.connect()
def restore_from_backup(backup_path):
"""从备份恢复数据库"""
try:
if not db.is_closed():
db.close()
if os.path.exists(backup_path):
shutil.copy2(backup_path, 'sensor_data.db')
logger.info(f"数据库已从备份恢复: {os.path.basename(backup_path)}")
return True
else:
logger.error(f"备份文件不存在: {backup_path}")
return False
except Exception as e:
logger.error(f"从备份恢复失败: {e}")
return False
finally:
db.connect()
# --- 版本管理 ---
def get_current_version():
"""获取当前数据库版本"""
try:
if not table_exists('database_versions'):
return '1.0' # 默认版本
latest = (DatabaseVersion
.select()
.order_by(DatabaseVersion.applied_at.desc())
.first())
return latest.version if latest else '1.0'
except Exception as e:
logger.error(f"获取版本失败: {e}")
return '1.0'
def set_version(version):
"""设置数据库版本"""
try:
# 确保版本表存在
if not table_exists('database_versions'):
db.create_tables([DatabaseVersion])
DatabaseVersion.create(version=version)
logger.info(f"数据库版本已更新为: {version}")
except Exception as e:
logger.error(f"设置版本失败: {e}")
# --- 迁移函数 ---
def migration_v1_1():
"""迁移到 v1.1: 添加 pressure 字段"""
logger.info("开始执行迁移: v1.0 -> v1.1")
try:
# 安全地添加 pressure 列
pressure_field = FloatField(null=True, default=None)
added = safe_migrate_add_column('sensor_records', 'pressure', pressure_field)
if added:
logger.info("迁移 v1.1 完成: 添加了 pressure 列")
else:
logger.info("迁移 v1.1 完成: pressure 列已存在")
except Exception as e:
logger.error(f"迁移 v1.1 失败: {e}")
raise
def migration_v1_2():
"""迁移到 v1.2: 添加索引和优化"""
logger.info("开始执行迁移: v1.1 -> v1.2")
try:
# 添加复合索引(如果不存在)
safe_migrate_add_index('sensor_records', ['device_id', 'recorded_at'])
# 添加设备状态索引(如果不存在)
safe_migrate_add_index('devices', ['status'])
logger.info("迁移 v1.2 完成: 添加了性能索引")
except Exception as e:
logger.error(f"迁移 v1.2 失败: {e}")
raise
# 迁移映射
MIGRATIONS = {
'1.1': migration_v1_1,
'1.2': migration_v1_2,
}
def run_migrations(target_version):
"""执行迁移到目标版本"""
current_version = get_current_version()
logger.info(f"当前数据库版本: {current_version}")
logger.info(f"目标版本: {target_version}")
if current_version == target_version:
logger.info("数据库已是最新版本")
return
# 创建备份
backup_path = create_backup()
try:
# 按顺序执行迁移
version_order = ['1.1', '1.2']
current_index = version_order.index(current_version) if current_version in version_order else -1
target_index = version_order.index(target_version)
for i in range(current_index + 1, target_index + 1):
version = version_order[i]
logger.info(f"执行迁移: {current_version} -> {version}")
if version in MIGRATIONS:
MIGRATIONS[version]()
set_version(version)
current_version = version
else:
logger.warning(f"未找到版本 {version} 的迁移函数")
logger.info(f"所有迁移完成,当前版本: {target_version}")
except Exception as e:
logger.error(f"迁移过程中出错: {e}")
if backup_path:
logger.info("正在回滚到备份...")
restore_from_backup(backup_path)
raise
# --- 数据库初始化和演示 ---
def init_database():
"""初始化数据库"""
if os.path.exists('sensor_data.db'):
logger.info("数据库已存在")
else:
logger.info("创建新数据库")
db.connect()
# 创建基础表
db.create_tables([Device, SensorRecord, DatabaseVersion], safe=True)
# 设置初始版本(如果没有版本记录)
if get_current_version() == '1.0' and not table_exists('database_versions'):
set_version('1.0')
def seed_data():
"""填充示例数据"""
try:
# 创建设备
devices_data = [
{'name': '温室A', 'location': '北区温室A号'},
{'name': '温室B', 'location': '北区温室B号'},
{'name': '仓库1', 'location': '存储区1号'},
{'name': '仓库2', 'location': '存储区2号'},
{'name': '实验室', 'location': '研发中心'},
]
for device_data in devices_data:
Device.get_or_create(name=device_data['name'], defaults=device_data)
# 创建传感器记录
import random
from datetime import timedelta
devices = list(Device.select())
records_to_create = []
for device in devices:
for i in range(100):
record = SensorRecord(
device=device,
temperature=round(random.uniform(18, 28), 1),
humidity=round(random.uniform(40, 80), 1),
recorded_at=datetime.now() - timedelta(hours=random.randint(0, 72))
)
records_to_create.append(record)
# 批量创建记录
if records_to_create:
SensorRecord.bulk_create(records_to_create, batch_size=100)
logger.info(f"创建了 {len(records_to_create)} 条传感器记录")
except Exception as e:
logger.error(f"填充数据失败: {e}")
def show_migration_status():
"""显示迁移状态"""
print("\n=== 数据库迁移状态 ===")
print(f"当前版本: {get_current_version()}")
print(f"数据库文件: sensor_data.db")
# 显示备份文件
backup_dir = 'backups'
if os.path.exists(backup_dir):
backups = [f for f in os.listdir(backup_dir) if f.endswith('.db')]
print(f"\n可用备份 ({len(backups)} 个):")
for backup in sorted(backups, reverse=True)[:5]: # 只显示最新的5个
backup_path = os.path.join(backup_dir, backup)
size = os.path.getsize(backup_path)
print(f" - {backup} ({size:,} 字节)")
else:
print("\n可用备份 (0 个):")
# 显示表统计
print("\n数据库表:")
try:
device_count = Device.select().count()
record_count = SensorRecord.select().count()
print(f" - devices: {device_count} 条记录")
print(f" - sensor_records: {record_count} 条记录")
except Exception as e:
print(f" - 无法获取统计信息: {e}")
def demo():
"""演示数据库迁移"""
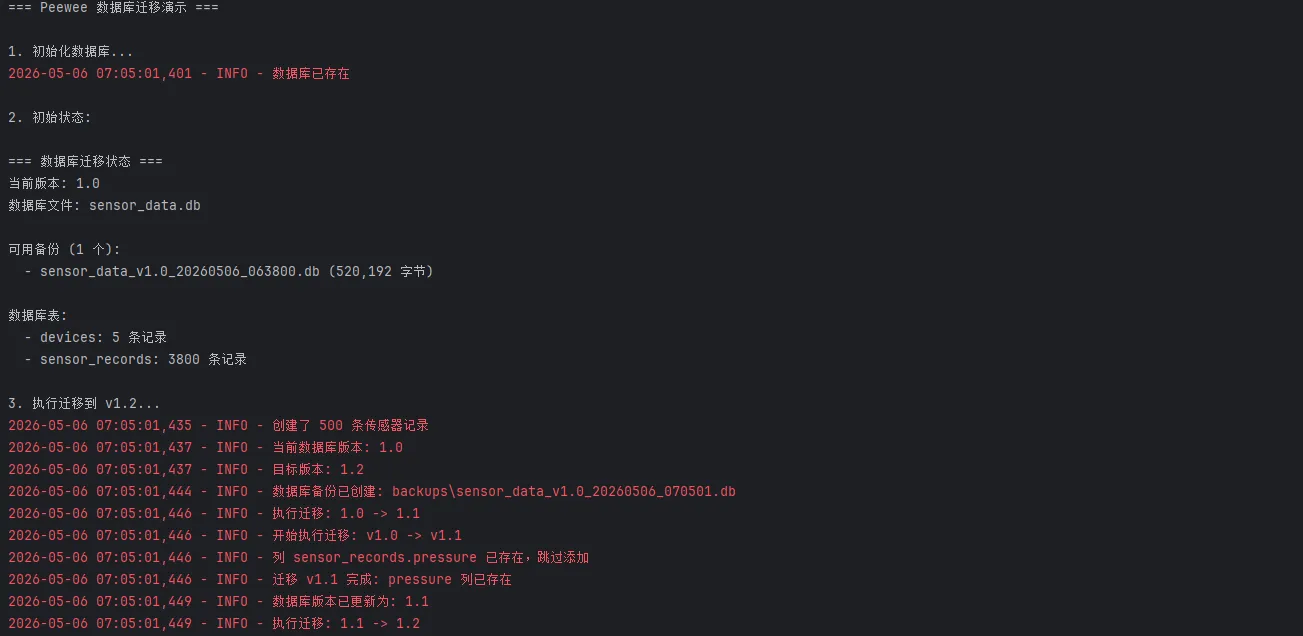
print("=== Peewee 数据库迁移演示 ===\n")
try:
print("1. 初始化数据库...")
init_database()
# 填充一些示例数据
seed_data()
print("\n2. 初始状态:")
show_migration_status()
print("\n3. 执行迁移到 v1.2...")
run_migrations('1.2')
print("\n4. 迁移后状态:")
show_migration_status()
print("\n5. 验证新功能...")
# 测试 pressure 字段
try:
# 更新一些记录的 pressure 值
records = SensorRecord.select().limit(10)
for record in records:
record.pressure = round(random.uniform(1010, 1020), 1)
record.save()
# 查询有 pressure 数据的记录
records_with_pressure = SensorRecord.select().where(
SensorRecord.pressure.is_null(False)
).count()
print(f" - 成功更新了 pressure 字段")
print(f" - 有 pressure 数据的记录: {records_with_pressure} 条")
except Exception as e:
print(f" - pressure 字段验证失败: {e}")
print("\n迁移演示完成!")
except Exception as e:
logger.error(f"演示过程中出现错误: {e}")
import traceback
traceback.print_exc()
if __name__ == "__main__":
demo()
这种方式比手写 ALTER TABLE SQL 更安全,也比引入 Alembic 轻量得多。对于中小型项目,playhouse.migrate 完全够用。
踩坑预警: SQLite 的 ALTER TABLE 原生只支持添加列,不支持删除或重命名列。如果需要删除列,Peewee 的迁移工具会通过"建新表 → 复制数据 → 删旧表"的方式完成,耗时会随数据量增大,建议在低峰期执行。
🧩 可复用代码模板
以下是一个适合直接集成到上位机或中间件项目的 数据库管理器模板:
python# db_manager.py —— 可直接复用的 Peewee 管理模板
from peewee import *
from playhouse.pool import PooledSqliteDatabase
from contextlib import contextmanager
import logging
logger = logging.getLogger(__name__)
class DatabaseManager:
def __init__(self, db_path: str, max_connections: int = 4):
self.db = PooledSqliteDatabase(
db_path,
max_connections=max_connections,
stale_timeout=300,
pragmas={
'journal_mode': 'wal', # WAL 模式,提升并发写入性能
'cache_size': -64 * 1024, # 64MB 缓存
'synchronous': 'normal', # 平衡安全与性能
}
)
@contextmanager
def get_connection(self):
"""线程安全的连接上下文"""
self.db.connect(reuse_if_open=True)
try:
yield self.db
finally:
if not self.db.is_closed():
self.db.close()
def init_tables(self, models: list):
"""初始化所有表"""
with self.get_connection():
self.db.create_tables(models, safe=True)
logger.info(f"已初始化 {len(models)} 张数据表")
def bulk_write(self, model_class, data: list[dict], batch_size: int = 500):
"""通用批量写入接口"""
with self.get_connection():
with self.db.atomic():
model_class.bulk_create(
[model_class(**d) for d in data],
batch_size=batch_size
)
logger.debug(f"批量写入 {len(data)} 条 {model_class.__name__} 记录")
journal_mode = 'wal' 这个 pragma 值得特别说一下——WAL(Write-Ahead Logging)模式让读写操作不再互相阻塞,在上位机这种"持续写入 + 偶发查询"的场景下,吞吐量提升非常明显,实测并发读写场景下性能提升约 40~60%。
💬 技术讨论
两个值得深入思考的问题,欢迎在评论区分享你的实践经验:
话题一: 在你的项目中,选择 ORM 的核心决策因素是什么?是团队熟悉度、性能、还是迁移能力?
话题二: 对于 SQLite 的并发写入瓶颈,你有没有遇到过 database is locked 的问题,最终是怎么解决的?
📌 三句话技术洞察
- 轻量不等于低能,Peewee 在 10 万级数据量以内的场景,性能和开发效率都优于 SQLAlchemy ORM 层。
- WAL 模式是 SQLite 并发场景的标配,一行 pragma 配置换来显著的吞吐提升,没有理由不用。
- N+1 查询是 ORM 的头号性能杀手,无论用哪个框架,联表查询时都要养成
join + select一起写的习惯。
🎯 总结与学习路径
本文围绕 Peewee 的三个核心能力展开:模型定义与基础 CRUD、多线程连接池管理、Schema 迁移实践。这三个层次覆盖了从原型开发到生产部署的完整链路。
如果你的项目规模在中小型范围内,数据库表数量不超过 20 张,建议直接从 Peewee 入手,而不是一上来就引入 SQLAlchemy 的全套体系。等业务复杂度真正上去了,再做技术选型迁移也不迟。
推荐学习路径:
- Peewee 官方文档(重点看 Querying 和 Playhouse 章节)
playhouse扩展库:pool、migrate、shortcuts、sqlite_ext- 进阶方向:结合
APScheduler实现定时采集 + Peewee 持久化的完整中间件架构
标签: Python ORM Peewee SQLite 数据库 性能优化 上位机 中间件 Python开发 编程技巧
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!