目录
🎯 你是不是也遇到过这种情况?
项目上线前两天,客户突然说:"我们的设备数据格式是自定义的二进制协议,你们软件能导入吗?顺便,配置参数还得从 Excel 里读。"
沉默三秒。然后你打开 IDE,开始写一堆 if-else。
说实话,这种场景在工控、自动化、数据采集类项目里太常见了。数据来源五花八门——标准 Excel 表格、CSV 文件、设备厂商自己定义的二进制帧、甚至是某种奇葩的文本协议。每次来一种新格式,就得改一次代码。改着改着,导入模块就成了"屎山"的核心产区。
这篇文章,咱们就用 Tkinter 把这个问题系统地解决掉。不是那种"能跑就行"的玩法,而是搭一套可扩展的多类型数据导入框架,让后续新增格式只需要加一个解析器类,其他地方一行不改。
读完你会拿到:一个完整的 Tkinter 导入界面、Excel 解析器、自定义二进制协议解析器,以及一套插件化的扩展思路。
🔍 问题根源:为什么导入逻辑总是越写越乱?
大多数人的第一反应是"加个文件选择对话框,判断扩展名,分支处理"。这没错,但问题在于——格式判断和 UI 逻辑全搅在一起了。
我在一个工厂设备管理项目里见过这样的代码:一个 import_data() 函数,700 行,里面同时处理文件对话框、进度条更新、Excel 解析、二进制拆包、数据库写入。改任何一个地方都战战兢兢,生怕动了哪根筋。
根本原因有三个:
- 职责不分离:UI 层直接调解析逻辑,耦合死死的
- 没有统一接口:每种格式的解析函数签名不一样,调用方式也不一样
- 错误处理分散:各种
try-except散落在各处,出了问题不知道从哪查起
解法也很清晰:定义统一的解析器接口,UI 层只管调度,具体格式交给各自的解析器。这就是策略模式(Strategy Pattern)的经典应用场景。
🏗️ 整体架构设计
先把框架捋清楚,再写代码。
pyDataImport (Tkinter 主界面) │ ├── FileSelector (文件选择组件) ├── FormatSelector (格式选择下拉框) ├── PreviewTable (数据预览表格) ├── ProgressBar (导入进度) │ └── ParserManager (解析器管理器) ├── ExcelParser (Excel 解析器) ├── CSVParser (CSV 解析器) └── BinaryProtocolParser (自定义二进制协议解析器)
ParserManager 负责注册和分发,UI 层只和 ParserManager 打交道。每个 Parser 实现同一个基类接口。新增格式?写个新 Parser,注册进去,完事。
🔧 基础环境准备
Windows 下开发,先确认依赖:
bashpip install openpyxl pandas
openpyxl 处理 .xlsx,pandas 可选——有些场景直接用 openpyxl 更轻量,不想引入 pandas 的话完全可以纯手写解析。struct 和 tkinter 是标准库,不用装。
📐 第一步:定义解析器基类
这是整个框架的"契约",所有解析器必须遵守。
python# base_parser.py
from abc import ABC, abstractmethod
from dataclasses import dataclass, field
from typing import List, Dict, Any, Optional
@dataclass
class ParseResult:
"""解析结果的统一容器"""
success: bool
headers: List[str] = field(default_factory=list)
rows: List[List[Any]] = field(default_factory=list)
error_msg: Optional[str] = None
row_count: int = 0
def __post_init__(self):
self.row_count = len(self.rows)
class BaseParser(ABC):
"""所有解析器的抽象基类"""
# 子类声明自己支持的文件扩展名
SUPPORTED_EXTENSIONS: List[str] = []
PARSER_NAME: str = "未命名解析器"
@abstractmethod
def parse(self, file_path: str, **kwargs) -> ParseResult:
"""
解析文件,返回统一的 ParseResult
:param file_path: 文件路径
:param kwargs: 解析器特定参数(如协议版本、sheet名等)
"""
pass
@abstractmethod
def validate_file(self, file_path: str) -> bool:
"""预检文件是否符合该解析器的要求"""
pass
def get_config_schema(self) -> Dict[str, Any]:
"""
返回该解析器的配置项定义,用于动态生成配置 UI
默认空配置,子类按需覆盖
"""
return {}
注意 get_config_schema() 这个方法——它是为了支持不同解析器有不同配置项(比如 Excel 需要选 sheet,二进制协议需要填帧头),让 UI 能动态生成对应的配置面板,而不是硬编码。
📊 第二步:Excel 解析器
Excel 是最常见的,先搞定它。要处理的细节其实不少:多 sheet、首行是否为表头、空行跳过、数据类型推断。
python# excel_parser.py
import openpyxl
from pathlib import Path
from .base_parser import BaseParser, ParseResult
class ExcelParser(BaseParser):
SUPPORTED_EXTENSIONS = ['.xlsx', '.xls', '.xlsm']
PARSER_NAME = "Excel 文件解析器"
def validate_file(self, file_path: str) -> bool:
p = Path(file_path)
return p.exists() and p.suffix.lower() in self.SUPPORTED_EXTENSIONS
def get_config_schema(self):
return {
'sheet_name': {
'type': 'select',
'label': '工作表',
'default': 0, # 默认第一个sheet
'dynamic': True # 标记为动态选项,需要打开文件后才能获取
},
'has_header': {
'type': 'checkbox',
'label': '首行为表头',
'default': True
},
'skip_empty_rows': {
'type': 'checkbox',
'label': '跳过空行',
'default': True
},
'max_rows': {
'type': 'number',
'label': '最大导入行数(0=不限制)',
'default': 0
}
}
def get_sheet_names(self, file_path: str):
"""获取所有sheet名,供UI动态填充下拉框"""
try:
wb = openpyxl.load_workbook(file_path, read_only=True, data_only=True)
names = wb.sheetnames
wb.close()
return names
except Exception as e:
return []
def parse(self, file_path: str, **kwargs) -> ParseResult:
if not self.validate_file(file_path):
return ParseResult(success=False, error_msg=f"文件不存在或格式不支持: {file_path}")
sheet_name = kwargs.get('sheet_name', 0)
has_header = kwargs.get('has_header', True)
skip_empty = kwargs.get('skip_empty_rows', True)
max_rows = kwargs.get('max_rows', 0)
try:
wb = openpyxl.load_workbook(file_path, read_only=True, data_only=True)
# 支持按名称或索引选sheet
if isinstance(sheet_name, int):
ws = wb.worksheets[sheet_name]
else:
ws = wb[sheet_name]
all_rows = list(ws.iter_rows(values_only=True))
wb.close()
if not all_rows:
return ParseResult(success=True, headers=[], rows=[])
# 处理表头
headers = []
data_start = 0
if has_header:
headers = [str(cell) if cell is not None else f"列{i+1}"
for i, cell in enumerate(all_rows[0])]
data_start = 1
else:
# 没有表头就自动生成列名
col_count = len(all_rows[0]) if all_rows else 0
headers = [f"列{i+1}" for i in range(col_count)]
# 提取数据行
rows = []
for raw_row in all_rows[data_start:]:
# 跳过全空行
if skip_empty and all(cell is None for cell in raw_row):
continue
# 统一 None 为空字符串,保留其他类型
processed = ['' if cell is None else cell for cell in raw_row]
rows.append(processed)
if max_rows > 0 and len(rows) >= max_rows:
break
return ParseResult(success=True, headers=headers, rows=rows)
except Exception as e:
return ParseResult(success=False, error_msg=f"Excel 解析失败: {str(e)}")
data_only=True 这个参数值得特别说一下——它让 openpyxl 读取单元格的缓存计算值而不是公式本身。如果你不加这个,带公式的单元格读出来是 =SUM(A1
None。遇到这种情况,要么用 pandas + xlrd 的计算引擎,要么提示用户先在 Excel 里保存一次。
🔌 第三步:设备自定义二进制协议解析器
这才是硬骨头。不同厂商的协议格式千奇百怪,但大多数工业设备协议都有共同的结构:帧头 + 长度字段 + 数据区 + 校验位。
咱们设计一个基于"协议描述字典"的解析器——把协议格式描述成一个配置,解析器根据配置动态拆包。这样换协议的时候,只改配置,不改代码。
python"""二进制协议解析器"""
import struct
from pathlib import Path
from typing import List, Dict, Any
from parsers.base_parser import BaseParser, ParseResult
# 协议定义
EXAMPLE_PROTOCOL = {
'name': '温度采集仪协议 v2.1',
'frame_header': b'\xAA\xBB', # 帧头标识
'header_size': 2,
'length_field': { # 长度字段描述
'offset': 0, # 长度字段紧接着帧头,offset应为0
'size': 2, # 占2个字节
'byte_order': 'big', # 大端序
'includes_header': False # 长度值不包含帧头
},
'checksum': {
'type': 'sum8', # 校验类型
'size': 1
},
'data_fields': [ # 数据区字段定义
{'name': '设备ID', 'format': 'H', 'unit': ''},
{'name': '时间戳', 'format': 'I', 'unit': 's'},
{'name': '温度', 'format': 'h', 'unit': '°C', 'scale': 0.1},
{'name': '湿度', 'format': 'H', 'unit': '%', 'scale': 0.1},
{'name': '状态码', 'format': 'B', 'unit': ''},
]
}
FORMAT_SIZE = {
'b': 1, 'B': 1,
'h': 2, 'H': 2,
'i': 4, 'I': 4,
'l': 4, 'L': 4,
'q': 8, 'Q': 8,
'f': 4, 'd': 8,
}
class BinaryProtocolParser(BaseParser):
SUPPORTED_EXTENSIONS = ['.bin', '.dat', '.raw', '.log']
PARSER_NAME = "自定义二进制协议解析器"
def __init__(self, protocol: Dict = None):
self.protocol = protocol or EXAMPLE_PROTOCOL
def validate_file(self, file_path: str) -> bool:
p = Path(file_path)
return p.exists() and p.is_file()
def _calc_checksum(self, data: bytes, method: str) -> int:
"""计算校验值"""
if method == 'sum8':
return sum(data) & 0xFF
elif method == 'xor':
result = 0
for b in data:
result ^= b
return result
elif method == 'crc16':
crc = 0xFFFF
for b in data:
crc ^= b
for _ in range(8):
if crc & 0x0001:
crc = (crc >> 1) ^ 0xA001
else:
crc >>= 1
return crc
return 0
def _parse_single_frame(self, frame_data: bytes) -> Dict[str, Any]:
"""解析单帧数据"""
proto = self.protocol
result = {}
# 帧头后是长度字段,然后是数据区
offset = proto['header_size'] + proto['length_field']['size']
byte_order_char = '>' if proto['length_field']['byte_order'] == 'big' else '<'
for field_def in proto['data_fields']:
fmt = byte_order_char + field_def['format']
size = FORMAT_SIZE.get(field_def['format'].lower(), 1)
if offset + size > len(frame_data) - proto['checksum'].get('size', 0):
break
value = struct.unpack_from(fmt, frame_data, offset)[0]
offset += size
if 'scale' in field_def:
value = round(value * field_def['scale'], 4)
result[field_def['name']] = value
return result
def _find_frames(self, raw_data: bytes) -> List[bytes]:
"""在原始字节流中搜索有效帧"""
frames = []
header = self.protocol['frame_header']
lf_config = self.protocol['length_field']
checksum_config = self.protocol.get('checksum', {})
cs_size = checksum_config.get('size', 0)
pos = 0
while pos < len(raw_data) - len(header):
# 搜索帧头
idx = raw_data.find(header, pos)
if idx == -1:
break
# ✓ 长度字段位置计算
# 长度字段紧接着帧头,offset是相对于长度字段字段开始位置
len_field_start = idx + self.protocol['header_size']
len_offset = len_field_start + lf_config['offset']
len_size = lf_config['size']
if len_offset + len_size > len(raw_data):
pos = idx + 1
continue
byte_order = '>' if lf_config['byte_order'] == 'big' else '<'
fmt_map = {1: 'B', 2: 'H', 4: 'I'}
len_fmt = byte_order + fmt_map.get(len_size, 'H')
try:
data_length = struct.unpack_from(len_fmt, raw_data, len_offset)[0]
except struct.error:
pos = idx + 1
continue
# 帧 = 帧头 + 长度字段 + 数据区 + 校验
frame_total = self.protocol['header_size'] + len_size + data_length + cs_size
if idx + frame_total > len(raw_data):
pos = idx + 1
continue
frame_bytes = raw_data[idx: idx + frame_total]
# 校验检查
if cs_size > 0 and checksum_config:
calc_cs = self._calc_checksum(
frame_bytes[:-cs_size],
checksum_config['type']
) recv_cs = frame_bytes[-cs_size]
if calc_cs != recv_cs:
pos = idx + 1
continue
frames.append(frame_bytes)
pos = idx + frame_total
return frames
def parse(self, file_path: str, **kwargs) -> ParseResult:
if not self.validate_file(file_path):
return ParseResult(success=False, error_msg=f"文件不存在: {file_path}")
try:
with open(file_path, 'rb') as f:
raw_data = f.read()
frames = self._find_frames(raw_data)
if not frames:
return ParseResult(
success=False,
error_msg=f"未找到有效数据帧 (文件大小: {len(raw_data)} 字节)"
)
headers = [f['name'] for f in self.protocol['data_fields']]
rows = []
for frame in frames:
parsed = self._parse_single_frame(frame)
row = [parsed.get(h, '') for h in headers]
rows.append(row)
return ParseResult(success=True, headers=headers, rows=rows)
except Exception as e:
import traceback
return ParseResult(success=False, error_msg=f"解析异常: {str(e)}\n{traceback.format_exc()}")
这里有个设计决策值得说说:_find_frames() 采用的是滑动窗口搜索而不是假设帧是紧密排列的。为什么?因为实际采集的文件里,经常会有噪声数据、不完整帧、或者多个设备的数据混在一起。滑动搜索更健壮,代价是稍微慢一点——对于几十 MB 以内的文件完全没问题。
🎛️ 第四步:解析器管理器
python# parser_manager.py
from typing import Dict, Type, Optional, List
from .base_parser import BaseParser, ParseResult
from .excel_parser import ExcelParser
from .binary_protocol_parser import BinaryProtocolParser
import os
class ParserManager:
def __init__(self):
self._parsers: Dict[str, BaseParser] = {}
# 注册内置解析器
self.register(ExcelParser())
self.register(BinaryProtocolParser())
def register(self, parser: BaseParser):
"""注册解析器,以解析器名称为键"""
self._parsers[parser.PARSER_NAME] = parser
def get_parser_names(self) -> List[str]:
return list(self._parsers.keys())
def get_parser(self, name: str) -> Optional[BaseParser]:
return self._parsers.get(name)
def auto_detect_parser(self, file_path: str) -> Optional[BaseParser]:
"""根据文件扩展名自动匹配解析器"""
ext = os.path.splitext(file_path)[1].lower()
for parser in self._parsers.values():
if ext in parser.SUPPORTED_EXTENSIONS:
return parser
return None
def parse(self, parser_name: str, file_path: str, **kwargs) -> ParseResult:
parser = self.get_parser(parser_name)
if not parser:
return ParseResult(success=False, error_msg=f"未找到解析器: {parser_name}")
return parser.parse(file_path, **kwargs)
🖥️ 第五步:Tkinter 主界面
现在把上面这些东西组装起来,做一个完整的导入界面。
pythonimport tkinter as tk
from tkinter import ttk, filedialog, messagebox
import threading
from parsers.parser_manager import ParserManager
from parsers.excel_parser import ExcelParser
class DataImportApp:
def __init__(self, root: tk.Tk):
self.root = root
self.root.title("多类型数据导入工具")
self.root.geometry("900x650")
self.root.resizable(True, True)
self.manager = ParserManager()
self.current_file = tk.StringVar()
self.selected_parser = tk.StringVar()
self.parse_result = None
self._build_ui()
def _build_ui(self):
# ── 顶部:文件选择区 ────────────────────────────── top_frame = ttk.LabelFrame(self.root, text="文件选择", padding=8)
top_frame.pack(fill='x', padx=10, pady=(10, 5))
ttk.Entry(top_frame, textvariable=self.current_file,
width=60, state='readonly').grid(row=0, column=0, padx=(0, 8), sticky='ew')
ttk.Button(top_frame, text="浏览...",
command=self._browse_file).grid(row=0, column=1)
top_frame.columnconfigure(0, weight=1)
# ── 中部:解析器选择 + 配置区 ────────────────────── mid_frame = ttk.LabelFrame(self.root, text="解析配置", padding=8)
mid_frame.pack(fill='x', padx=10, pady=5)
ttk.Label(mid_frame, text="解析器:").grid(row=0, column=0, sticky='w')
parser_names = self.manager.get_parser_names()
self.parser_combo = ttk.Combobox(
mid_frame, textvariable=self.selected_parser,
values=parser_names, state='readonly', width=25
)
self.parser_combo.grid(row=0, column=1, padx=(0, 20), sticky='w')
if parser_names:
self.parser_combo.current(0)
self.parser_combo.bind('<<ComboboxSelected>>', self._on_parser_changed)
# Excel 专属配置(动态显示/隐藏)
self.excel_config_frame = ttk.Frame(mid_frame)
self.excel_config_frame.grid(row=0, column=2, sticky='w')
ttk.Label(self.excel_config_frame, text="Sheet:").pack(side='left')
self.sheet_var = tk.StringVar(value="第一个Sheet")
self.sheet_combo = ttk.Combobox(
self.excel_config_frame, textvariable=self.sheet_var,
width=15, state='readonly'
)
self.sheet_combo.pack(side='left', padx=(0, 10))
self.has_header_var = tk.BooleanVar(value=True)
ttk.Checkbutton(
self.excel_config_frame, text="首行为表头",
variable=self.has_header_var
).pack(side='left')
# ── 操作按钮 ────────────────────────────────────── btn_frame = ttk.Frame(self.root)
btn_frame.pack(fill='x', padx=10, pady=5)
self.import_btn = ttk.Button(
btn_frame, text="▶ 开始解析",
command=self._start_parse, style='Accent.TButton'
)
self.import_btn.pack(side='left', padx=(0, 10))
ttk.Button(btn_frame, text="清空",
command=self._clear).pack(side='left')
self.status_label = ttk.Label(btn_frame, text="等待导入...", foreground='gray')
self.status_label.pack(side='left', padx=20)
# ── 进度条 ────────────────────────────────────────
self.progress = ttk.Progressbar(self.root, mode='indeterminate')
self.progress.pack(fill='x', padx=10, pady=(0, 5))
# ── 数据预览表格 ──────────────────────────────────
preview_frame = ttk.LabelFrame(self.root, text="数据预览(最多显示500行)", padding=5)
preview_frame.pack(fill='both', expand=True, padx=10, pady=(0, 10))
self.tree = ttk.Treeview(preview_frame, show='headings', selectmode='browse')
vsb = ttk.Scrollbar(preview_frame, orient='vertical', command=self.tree.yview)
hsb = ttk.Scrollbar(preview_frame, orient='horizontal', command=self.tree.xview)
self.tree.configure(yscrollcommand=vsb.set, xscrollcommand=hsb.set)
self.tree.grid(row=0, column=0, sticky='nsew')
vsb.grid(row=0, column=1, sticky='ns')
hsb.grid(row=1, column=0, sticky='ew')
preview_frame.rowconfigure(0, weight=1)
preview_frame.columnconfigure(0, weight=1)
def _browse_file(self):
filetypes = [
("Excel 文件", "*.xlsx *.xls *.xlsm"),
("二进制数据", "*.bin *.dat *.raw *.log"),
("所有文件", "*.*")
] path = filedialog.askopenfilename(filetypes=filetypes)
if not path:
return
self.current_file.set(path)
# 自动匹配解析器
auto_parser = self.manager.auto_detect_parser(path)
if auto_parser:
self.selected_parser.set(auto_parser.PARSER_NAME)
self._on_parser_changed(None)
# 如果是 Excel,动态加载 sheet 列表
if isinstance(auto_parser, ExcelParser):
sheet_names = auto_parser.get_sheet_names(path)
if sheet_names:
self.sheet_combo['values'] = sheet_names
self.sheet_combo.current(0)
def _on_parser_changed(self, event):
"""切换解析器时,动态显示/隐藏对应配置项"""
parser_name = self.selected_parser.get()
if "Excel" in parser_name:
self.excel_config_frame.grid()
else:
self.excel_config_frame.grid_remove()
def _start_parse(self):
file_path = self.current_file.get()
if not file_path:
messagebox.showwarning("提示", "请先选择文件")
return
parser_name = self.selected_parser.get()
if not parser_name:
messagebox.showwarning("提示", "请选择解析器")
return
# 在后台线程里跑解析,防止 UI 卡死
self.import_btn.config(state='disabled')
self.progress.start(10)
self.status_label.config(text="解析中...", foreground='blue')
kwargs = {}
if "Excel" in parser_name:
sheet_values = self.sheet_combo['values']
current_sheet = self.sheet_var.get()
# 找到sheet的索引
if sheet_values and current_sheet in sheet_values:
kwargs['sheet_name'] = list(sheet_values).index(current_sheet)
else:
kwargs['sheet_name'] = 0
kwargs['has_header'] = self.has_header_var.get()
thread = threading.Thread(
target=self._do_parse,
args=(parser_name, file_path),
kwargs=kwargs,
daemon=True
)
thread.start()
def _do_parse(self, parser_name, file_path, **kwargs):
"""后台线程执行解析"""
result = self.manager.parse(parser_name, file_path, **kwargs)
# 解析完成后回到主线程更新UI
self.root.after(0, self._on_parse_done, result)
def _on_parse_done(self, result):
self.progress.stop()
self.import_btn.config(state='normal')
if not result.success:
self.status_label.config(
text=f"解析失败:{result.error_msg}", foreground='red'
)
messagebox.showerror("解析失败", result.error_msg)
return
self.parse_result = result
self._refresh_table(result)
self.status_label.config(
text=f"解析完成,共 {result.row_count} 行数据",
foreground='green'
)
def _refresh_table(self, result):
"""刷新预览表格"""
# 清空旧数据
self.tree.delete(*self.tree.get_children())
self.tree['columns'] = result.headers
for col in result.headers:
self.tree.heading(col, text=col)
self.tree.column(col, width=100, minwidth=60, anchor='center')
# 最多预览 500 行,太多了界面会卡
preview_rows = result.rows[:500]
for row in preview_rows:
self.tree.insert('', 'end', values=[str(v) for v in row])
def _clear(self):
self.current_file.set('')
self.tree.delete(*self.tree.get_children())
self.tree['columns'] = []
self.parse_result = None
self.status_label.config(text="等待导入...", foreground='gray')
if __name__ == '__main__':
root = tk.Tk()
app = DataImportApp(root)
root.mainloop()
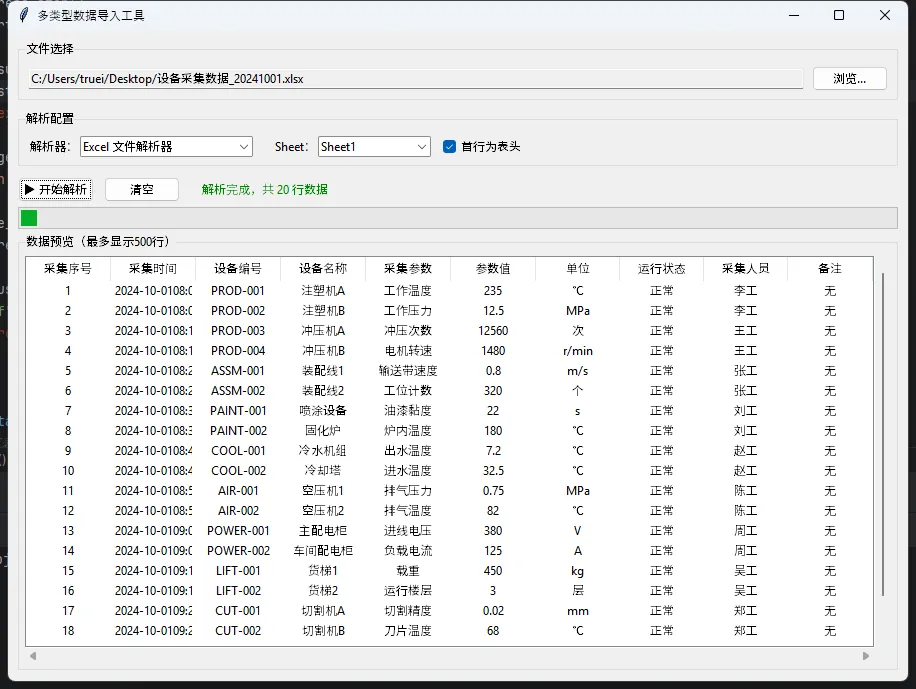
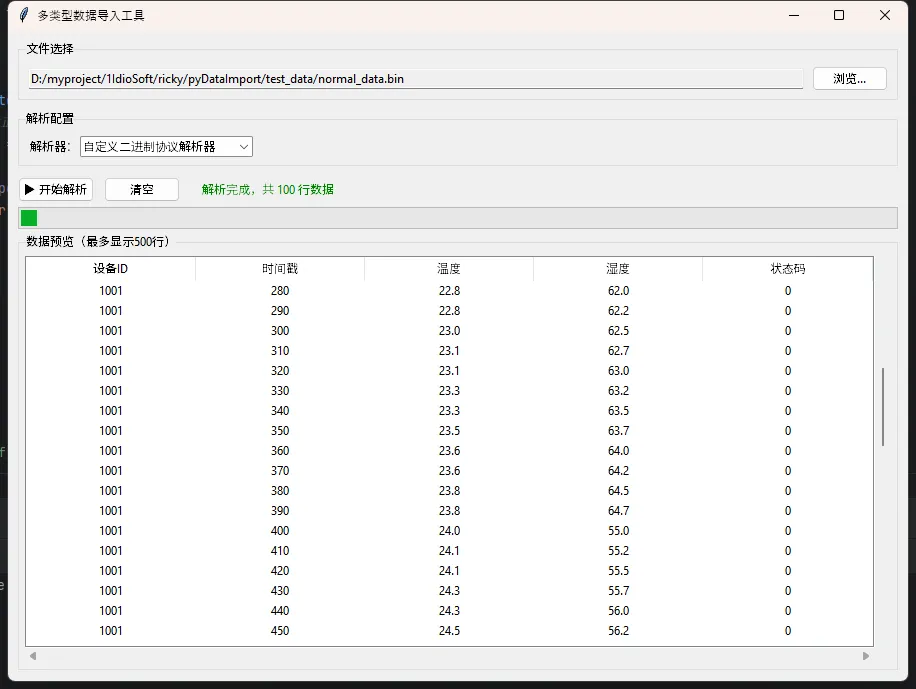
🗂️ 完整项目结构
跑起来之前,先把目录结构建好:
data_importer/ ├── main_app.py # 入口 ├── parsers/ │ ├── __init__.py │ ├── base_parser.py # 抽象基类 │ ├── excel_parser.py # Excel 解析器 │ ├── binary_protocol_parser.py # 二进制协议解析器 │ └── parser_manager.py # 解析器管理器 └── protocols/ └── temperature_sensor.json # 协议配置(可选,按需扩展)
parsers/__init__.py 里把常用的导出一下:
pythonfrom .parser_manager import ParserManager
from .excel_parser import ExcelParser
from .binary_protocol_parser import BinaryProtocolParser, EXAMPLE_PROTOCOL
⚠️ 几个必须说的踩坑点
坑一:openpyxl 读大文件内存爆炸。 read_only=True 是关键,但即便如此,几十万行的 Excel 也会比较慢。如果业务上真的需要处理超大文件,考虑改用 pandas + chunksize 分块读取,然后分批塞进 Treeview。
坑二:Tkinter 不是线程安全的。 这一点没得商量——所有 UI 操作必须在主线程里做。上面代码里用 root.after(0, callback) 把解析结果"投递"回主线程,这是标准做法。千万别在子线程里直接操作 widget,迟早崩。
坑三:二进制文件编码陷阱。 打开二进制文件一定要用 'rb' 模式,不能带任何编码参数。有同学习惯性地写 open(path, 'r', encoding='utf-8'),遇到二进制文件直接抛 UnicodeDecodeError,找半天找不到原因。
坑四:struct 解包的字节序。 工业设备大多用大端序(>),PC 端程序默认小端(<)。协议文档里如果没有明确说明,先试大端,不对再换。用 Wireshark 抓包对照是最稳的验证方式。
🚀 扩展:新增一个 CSV 解析器只需这几行
这才是插件化架构的价值所在。新来一种格式,写个类,注册进去,其他地方零改动:
python# parsers/csv_parser.py
import csv
from .base_parser import BaseParser, ParseResult
class CSVParser(BaseParser):
SUPPORTED_EXTENSIONS = ['.csv', '.tsv', '.txt']
PARSER_NAME = "CSV/TSV 文件解析器"
def validate_file(self, file_path):
from pathlib import Path
return Path(file_path).exists()
def parse(self, file_path, **kwargs):
encoding = kwargs.get('encoding', 'utf-8-sig') # 处理 BOM
delimiter = kwargs.get('delimiter', ',')
has_header = kwargs.get('has_header', True)
try:
with open(file_path, 'r', encoding=encoding, newline='') as f:
reader = csv.reader(f, delimiter=delimiter)
all_rows = list(reader)
if not all_rows:
return ParseResult(success=True, headers=[], rows=[])
headers = all_rows[0] if has_header else [f"列{i+1}" for i in range(len(all_rows[0]))]
data_rows = all_rows[1:] if has_header else all_rows
return ParseResult(success=True, headers=headers, rows=data_rows)
except Exception as e:
return ParseResult(success=False, error_msg=str(e))
然后在 ParserManager.__init__ 里加一行:
pythonfrom .csv_parser import CSVParser
self.register(CSVParser())
完事。UI 自动多出一个选项,自动检测 .csv 文件,配置面板按需扩展。
💡 三句话带走的核心思路
统一接口是根基。
BaseParser定义契约,所有解析器遵守同一个parse()签名,调用方永远不用关心底层实现。
后台线程是底线。 文件 IO 和解析逻辑全部扔到子线程,
root.after()投递结果,Tkinter UI 永远不卡。
协议描述数据化。 把二进制协议的字段定义写成字典或 JSON,解析器变成一个通用引擎——换协议只换配置,代码稳如老狗。
这套框架在实际项目里跑过温度采集仪、PLC 数据记录仪、以及某厂商私有格式的配置导出文件,稳定性还不错。如果你的设备协议比较复杂(比如变长字段、嵌套结构),可以在 data_fields 里加入 conditional 和 repeat 描述符,把解析器做成一个小型的 DSL 引擎——那就是另一篇文章的话题了。
欢迎在评论区分享你遇到过的奇葩数据格式,或者聊聊你们项目里的协议解析方案。
#Python #Tkinter #数据导入 #工控开发 #二进制协议
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!