
目录
🤖 GPT是什么?揭开AI大模型的神秘面纱
你有没有想过,为什么ChatGPT能像人类一样自然地对话?为什么它能写诗、编程、甚至帮你分析复杂的商业问题? 很多人以为这只是简单的"关键词匹配"或"模板填充",但实际上,GPT背后的技术原理远比你想象的精妙。
今天,咱们就用最接地气的方式,把GPT这个看似高深的技术"掰开揉碎"讲清楚。读完这篇文章,你不仅能理解GPT的工作原理,还能向身边的朋友科普这项改变世界的技术。
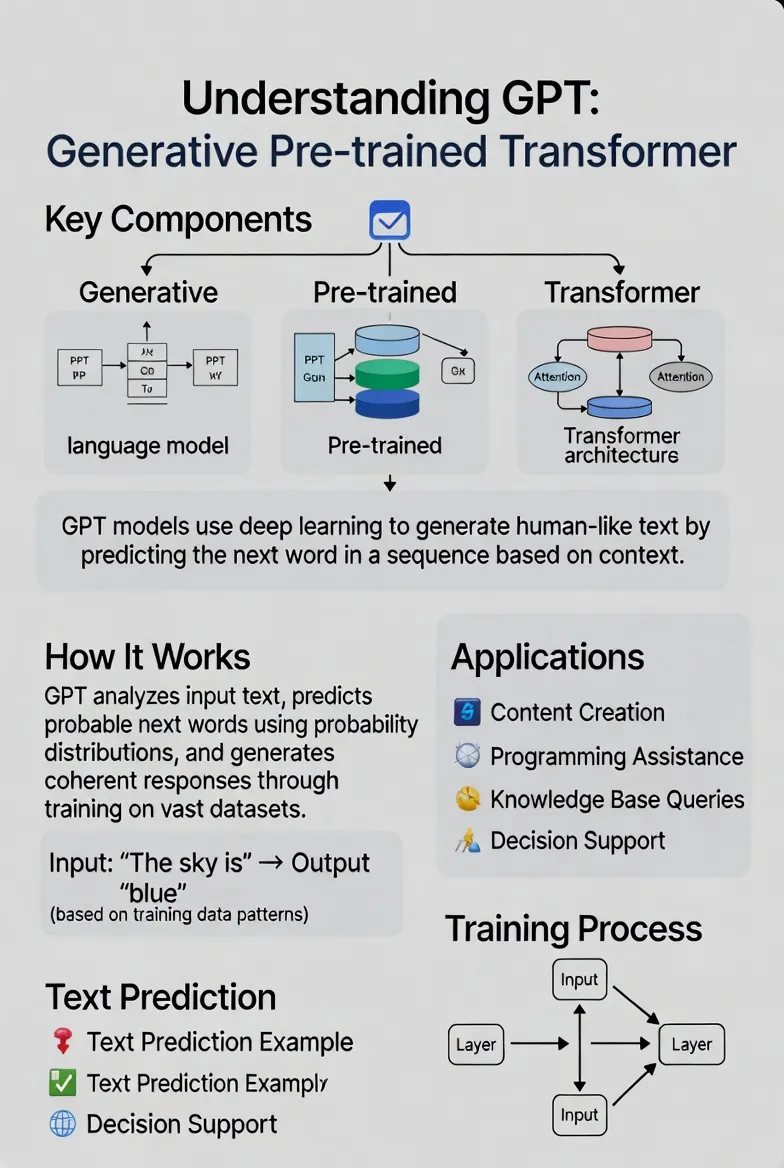
🔍 GPT三个字母背后的秘密
GPT这个名字可不是随便起的,它是三个英文单词的缩写,每个字母都藏着关键信息:
G = Generative(生成式)
这意味着模型具备"创造"能力——不是简单地检索现有内容,而是真正生成全新的文本。
P = Pre-trained(预训练)
在正式"上岗"之前,模型已经读过海量的书籍、网页、文章,掌握了语言的基本规律和常识。
T = Transformer(变换器)
这是一种革命性的神经网络架构,让机器能够理解复杂的上下文关系,就像人类阅读时能联系前后文一样。
听起来还是有点抽象?别急,咱们一个一个拆开来讲。
🎨 什么是"生成式"?用例子说透它
很多人误以为GPT只是在"复制粘贴"互联网上的内容。其实不然——它是通过预测概率来生成文本的。
原理很简单:猜下一个词
想象你在跟朋友聊天,对方说了半句话:"今天天气真…",你的大脑会自动预测下一个词可能是"好"、"热"、"冷"。GPT做的就是同样的事,只不过它是基于数学概率来预测。
🌰 例子一:日常对话生成
输入: "早上起床后,我先…"
GPT的思考过程:
- "刷牙"出现的概率:35%
- "洗脸"出现的概率:30%
- "喝水"出现的概率:20%
- "看手机"出现的概率:15%
最终GPT可能选择概率最高的"刷牙",生成:"早上起床后,我先刷牙,然后…"
🌰 例子二:创意写作
输入: "月光洒在湖面上,像…"
GPT的思考过程:
- "碎银"出现概率:25%
- "丝绸"出现概率:20%
- "镜子"出现概率:18%
- "钻石"出现概率:15%
它可能生成:"月光洒在湖面上,像碎银铺满水面,波光粼粼。"
🌰 例子三:技术问答
输入: "Python中列表和元组的区别是…"
GPT的思考过程: 基于训练数据中成千上万篇技术文档,它知道:
- 接下来应该出现"列表可变,元组不可变"的概率:45%
- 出现具体语法示例的概率:30%
- 出现性能对比的概率:25%
最终生成完整、准确的技术解答。
关键点在这儿:
GPT不是从数据库里"查找"答案,而是一个字一个字地预测出来的。每预测一个词,它都要综合考虑:
- 前面所有的文字内容
- 语法规则
- 常识逻辑
- 上下文语境
这就像一个高手下围棋——每一步都在计算无数种可能性,最终选出最合理的那一步。
📚 "预训练"到底训练了什么?
你可能会问:GPT怎么知道"刷牙"比"跳舞"更适合接在"早上起床后"之后呢?
答案就在"预训练"这个环节。
预训练=让AI读万卷书
在正式工作之前,GPT经历了一个疯狂的"学习期":
阶段一:海量阅读
- 维基百科的所有条目
- 几百万本电子书
- 数十亿个网页
- 无数的新闻文章、论坛讨论、技术文档
阶段二:自学规律
通过不断地"猜下一个词"并对比正确答案,GPT逐渐掌握了:
- 语法结构:"的"后面通常接名词
- 拼写规范:"receive"不是"recieve"
- 常识知识:太阳从东边升起,水的化学式是H₂O
- 语义关联:"医生"和"医院"关系密切,"猫"和"狗"都是宠物
这就好比一个孩子通过大量阅读,自然而然地学会了语言表达和知识积累,无需死记硬背每一条规则。
为什么要预训练?
试想一下,如果每次让GPT回答问题都要从零开始学习,那得等到猴年马月?
预训练就像给AI打了坚实的"地基"——有了这个基础,再针对特定任务(比如客服对话、代码生成)进行微调,效率就会大幅提升。
⚙️ Transformer:让AI拥有"上下文理解力"
前面说的"生成"和"预训练"都好理解,但为什么偏偏要用Transformer这种结构呢?
传统AI的致命缺陷
在Transformer出现之前,AI模型有个致命问题:健忘。
举个例子:
句子: "小明去银行取钱,他发现ATM机坏了,所以他只能去柜台,排队等了很久,最终他取到了现金。"
传统模型读到"他取到了现金"时,可能已经忘记了前面"ATM机坏了"和"去柜台"的信息,导致无法理解整个事件的因果关系。
Transformer的革命性突破:自注意力机制
Transformer引入了"自注意力"(Self-Attention)机制,让模型能够:
1. 同时关注所有词语
不再像人类阅读那样从左到右逐字处理,而是一次性把整个句子的所有词都"看"一遍。
2. 计算词与词之间的关系
在上面的例子中,模型会自动识别:
- "他"指的是"小明"
- "取到了现金"和"去柜台"有因果关系
- "ATM机坏了"是关键背景信息
3. 动态调整注意力权重
读到"现金"这个词时,模型会自动把更多"注意力"分配给"银行"、"ATM"、"柜台"这些相关词,而忽略无关的"排队等了很久"。
打个比方:
- 传统模型:像近视眼看书,每次只能看清楚眼前的一两个字,读到后面就忘了前面。
- Transformer:像鹰眼一样能俯瞰全局,瞬间把握整篇文章的脉络和重点。
正是因为有了Transformer,GPT才能:
- 理解长篇文章的逻辑
- 记住对话中的历史信息
- 处理复杂的多层嵌套句子
- 生成连贯、符合语境的长文本
💡 GPT的实际应用:它能为你做什么?
理解了原理,咱们再看看GPT在实际中能解决哪些问题:
1️⃣ 内容创作助手
- 写公众号文章大纲
- 生成营销文案
- 创作故事情节
2️⃣ 编程辅助工具
- 解释复杂代码逻辑
- 自动生成函数
- Debug调试建议
3️⃣ 知识问答专家
- 解答技术难题
- 解释专业概念
- 提供学习路径建议
4️⃣ 商业决策参谋
- 分析市场趋势
- 提供战略建议
- 生成数据报告
🚨 常见误区大揭秘
❌ 误区一:GPT只是在"搜索+复制"网上的内容
✅ 真相:GPT是通过概率计算原创生成文本,不是简单检索。
❌ 误区二:GPT知道所有事情
✅ 真相:GPT的知识有"截止日期",且可能产生"幻觉"(编造不存在的信息)。
❌ 误区三:GPT能完全替代人类工作
✅ 真相:GPT是辅助工具,创意、判断、情感这些人类独有的能力它还无法真正具备。
❌ 误区四:所有AI都是GPT
✅ 真相:GPT只是生成式AI的一种,还有图像生成(如Midjourney)、语音合成等其他类型。
🎯 三个金句总结
1. GPT的本质是"概率预测大师"——它通过计算可能性来生成每一个词。
2. 预训练让GPT拥有了"博览群书"的知识储备,Transformer让它具备了"前后贯通"的理解能力。
3. GPT不是魔法,而是数学、数据和算法的完美结合——理解原理,才能更好地驾驭它。
💬 写在最后
从"生成式"的概率预测,到"预训练"的知识积累,再到"Transformer"的上下文理解——GPT的每个组成部分都在为一个目标服务:让机器能够像人类一样自然、流畅地使用语言。
虽然GPT还不完美,会犯错、会胡编乱造,但它已经展示了AI技术的巨大潜力。未来,随着技术的进步,GPT类模型将会在更多领域发挥作用——而理解它的工作原理,就是我们拥抱AI时代的第一步。
你在工作或生活中使用过ChatGPT吗?它给你带来了哪些惊喜或困扰? 欢迎在评论区分享你的经验,也许你的故事能帮助更多人更好地理解和使用这项技术!
如果这篇文章让你对GPT有了全新的认识,别忘了点赞、转发给更多同行——让更多人一起解锁AI时代的新技能!🚀
延伸阅读推荐:
- 《Transformer模型详解:注意力机制的前世今生》
- 《GPT-3到GPT-4:大模型进化史》
- 《如何高效使用ChatGPT:Prompt工程实战指南》

本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!