
Press Ctrl+ and K to search
目录
Python集合(set):数据去重与高效集合运算的必备利器
在Python开发中,你是否遇到过这些场景:需要快速去除列表中的重复数据?想要找出两个数据集的交集或差集?需要判断某个元素是否存在于大量数据中?这些问题的最优解答案都指向同一个数据结构——集合(set)。
本文将深入剖析Python集合的核心特性,包括自动去重机制、四大集合运算(并集、交集、差集、对称差集)以及无序特性的本质。通过丰富的代码实战案例,帮助你掌握这个在数据处理、算法优化中不可或缺的数据结构,让你的Python开发效率提升一个档次。
🔍 集合的本质:无序且唯一的数据容器
什么是集合?
集合(set)是Python内置的一种无序、不重复的数据类型,底层基于哈希表实现。这意味着:
- 元素唯一性:自动过滤重复元素
- 无序性:不保证元素的存储顺序
- 高效查询:成员检测速度极快(O(1)时间复杂度)
python# 创建集合的三种方式
# 创建集合的三种方式
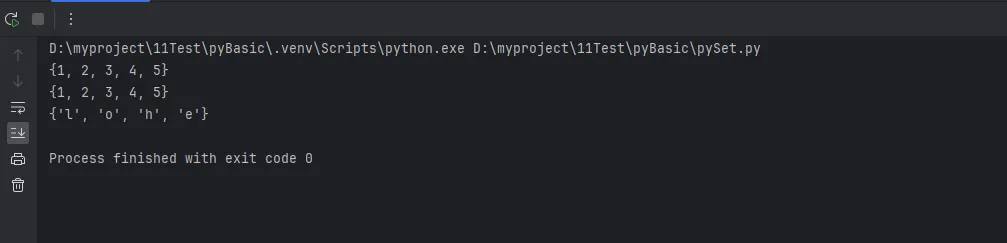
set1 = {1, 2, 3, 4, 5} # 使用花括号
set2 = set([1, 2, 2, 3, 4, 4, 5]) # 从列表创建(自动去重)
set3 = set("hello") # 从字符串创建
print(set1)
print(set2)
print(set3)
⚠️ 重要特性说明
python# 1. 集合元素必须是可哈希的(不可变类型)
valid_set = {1, 'python', (1, 2), 3.14} # ✅ 正确
# invalid_set = {[1, 2], {3, 4}} # ❌ 错误:列表和集合不可哈希
# 2. 空集合必须用set()创建
empty_set = set() # ✅ 正确
empty_dict = {} # ❌ 这是空字典,不是空集合
# 3. 无序性演示
numbers = {5, 1, 9, 3, 7}
print(numbers)
🎯 核心功能一:强大的去重能力
场景1:列表数据快速去重
在Windows应用开发中,处理用户日志、配置文件时经常需要去重:
python# 用户访问日志中的IP地址去重
ip_logs = [
'192.168.1.1', '192.168.1.2', '192.168.1.1',
'10.0.0.5', '192.168.1.2', '10.0.0.5'
]
# 方法1:转换为集合去重
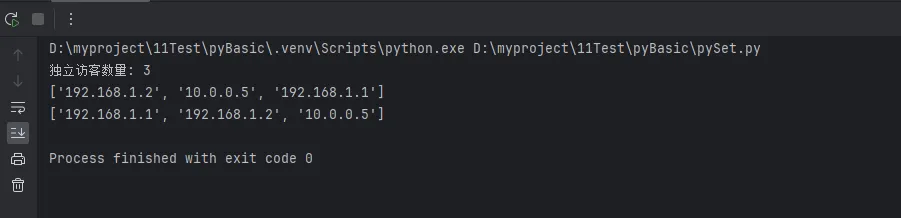
unique_ips = list(set(ip_logs))
print(f"独立访客数量: {len(unique_ips)}") # 3
print(unique_ips)
# 方法2:保留原始顺序的去重
unique_ips_ordered = list(dict.fromkeys(ip_logs))
print(unique_ips_ordered)
场景2:Excel数据处理中的去重
python# 模拟从Excel读取的产品ID列表
product_ids = [
'SKU001', 'SKU002', 'SKU001', 'SKU003',
'SKU002', 'SKU004', 'SKU001', 'SKU003'
]
# 统计去重前后的数据量
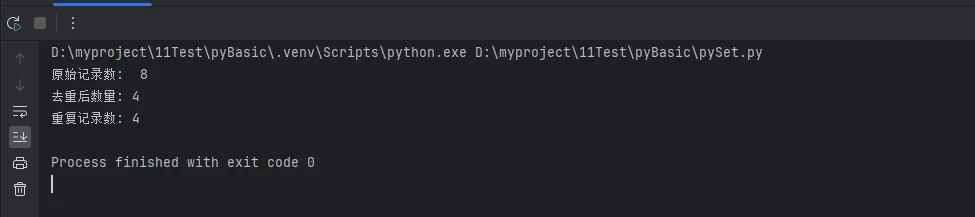
print(f"原始记录数: {len(product_ids)}")
unique_products = set(product_ids)
print(f"去重后数量: {len(unique_products)}")
print(f"重复记录数: {len(product_ids) - len(unique_products)}")
场景3:找出重复元素
pythondef find_duplicates(data_list):
"""找出列表中的重复元素"""
seen = set()
duplicates = set()
for item in data_list:
if item in seen:
duplicates. add(item)
else:
seen.add(item)
return duplicates
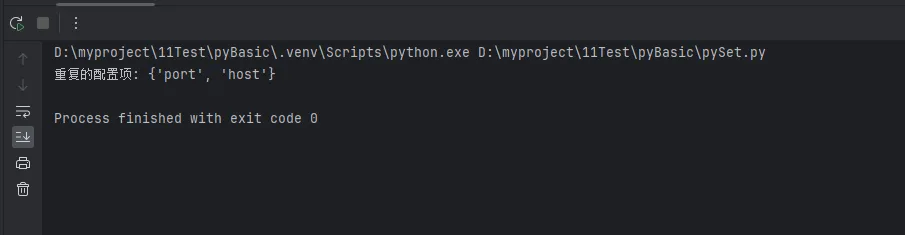
# 检测配置文件中的重复配置项
config_keys = ['host', 'port', 'user', 'host', 'timeout', 'port']
dup_keys = find_duplicates(config_keys)
print(f"重复的配置项: {dup_keys}")
⚙️ 核心功能二:四大集合运算实战
1️⃣ 并集(Union):合并数据集
应用场景:合并多个来源的数据、用户权限合并
python# 场景:两个部门的员工列表合并
dept_a = {'张三', '李四', '王五'}
dept_b = {'王五', '赵六', '孙七'}
# 方法1:使用 | 运算符
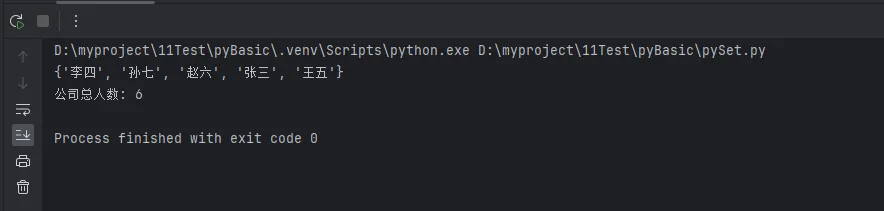
all_employees = dept_a | dept_b
print(all_employees)
# 方法2:使用 union() 方法
all_employees = dept_a.union(dept_b)
# 多个集合并集
dept_c = {'孙七', '周八'}
all_depts = dept_a | dept_b | dept_c
print(f"公司总人数: {len(all_depts)}")
2️⃣ 交集(Intersection):找出共同元素
应用场景:找出同时满足多个条件的数据、权限校验
python# 场景:找出同时拥有两种权限的用户
read_permission = {'user1', 'user2', 'user3', 'user4'}
write_permission = {'user2', 'user3', 'user5', 'user6'}
# 方法1:使用 & 运算符
admin_users = read_permission & write_permission
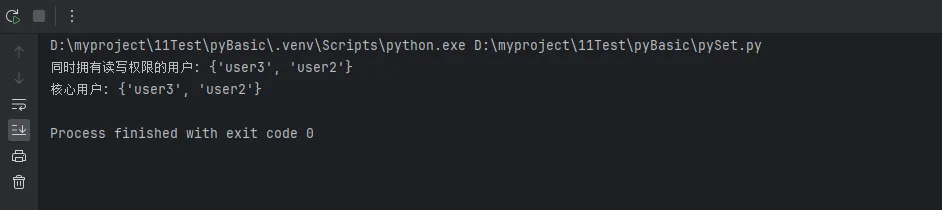
print(f"同时拥有读写权限的用户: {admin_users}")
# 方法2:使用 intersection() 方法
admin_users = read_permission. intersection(write_permission)
# 实战案例:多条件筛选
online_users = {'user1', 'user2', 'user3', 'user7'}
active_last_month = {'user2', 'user3', 'user4', 'user5'}
paid_users = {'user2', 'user3', 'user6'}
# 找出在线且活跃且付费的用户(核心用户)
core_users = online_users & active_last_month & paid_users
print(f"核心用户: {core_users}")
3️⃣ 差集(Difference):找出独有元素
应用场景:数据对比、增量更新、权限移除
python# 场景:找出需要新增的配置项
old_config = {'host', 'port', 'user', 'password'}
new_config = {'host', 'port', 'user', 'password', 'timeout', 'ssl'}
# 方法1:使用 - 运算符
added_items = new_config - old_config
removed_items = old_config - new_config
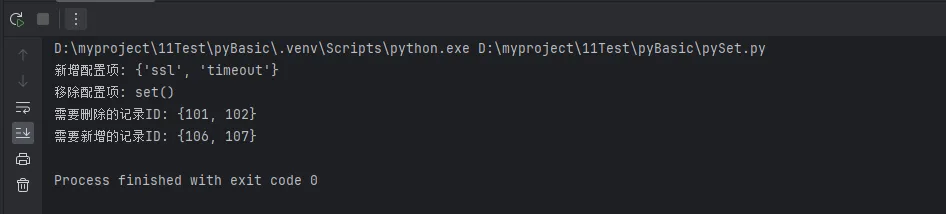
print(f"新增配置项: {added_items}")
print(f"移除配置项: {removed_items}")
# 方法2:使用 difference() 方法
added_items = new_config.difference(old_config)
# 实战:数据库同步场景
db_records = {101, 102, 103, 104, 105}
excel_records = {103, 104, 105, 106, 107}
# 找出需要删除的记录(数据库有但Excel没有)
to_delete = db_records - excel_records
print(f"需要删除的记录ID: {to_delete}") # {101, 102}
# 找出需要新增的记录(Excel有但数据库没有)
to_insert = excel_records - db_records
print(f"需要新增的记录ID: {to_insert}") # {106, 107}
4️⃣ 对称差集(Symmetric Difference):找出不共同的元素
应用场景:数据差异分析、异常检测
python# 场景:找出两个数据源的差异项
source_a = {'item1', 'item2', 'item3', 'item4'}
source_b = {'item3', 'item4', 'item5', 'item6'}
# 方法1:使用 ^ 运算符
diff_items = source_a ^ source_b
print(f"差异项: {diff_items}") # {'item1', 'item2', 'item5', 'item6'}
# 方法2:使用 symmetric_difference() 方法
diff_items = source_a. symmetric_difference(source_b)
# 等价于:(A - B) | (B - A)
diff_items_manual = (source_a - source_b) | (source_b - source_a)
print(diff_items == diff_items_manual) # True
# 实战:文件对比工具
file1_lines = set(['line1', 'line2', 'line3'])
file2_lines = set(['line2', 'line3', 'line4'])
different_lines = file1_lines ^ file2_lines
print(f"不同的行: {different_lines}") # {'line1', 'line4'}
🔧 集合运算对比表
| 运算 | 符号 | 方法 | 说明 | 示例结果 |
|---|---|---|---|---|
| 并集 | | | union() | A或B中的所有元素 | {1,2,3} | {3,4,5} → {1,2,3,4,5} |
| 交集 | & | intersection() | A和B共有的元素 | {1,2,3} & {3,4,5} → {3} |
| 差集 | - | difference() | A有但B没有的元素 | {1,2,3} - {3,4,5} → {1,2} |
| 对称差 | ^ | symmetric_difference() | A和B不共有的元素 | {1,2,3} ^ {3,4,5} → {1,2,4,5} |
🚀 集合的高级操作
添加与删除元素
python# 创建集合
tags = {'python', 'django', 'flask'}
# 1. add() - 添加单个元素
tags.add('fastapi')
print(tags) # {'python', 'django', 'flask', 'fastapi'}
# 添加已存在的元素(无效果)
tags.add('python')
print(tags) # 仍然是4个元素
# 2. update() - 批量添加(可接受任何可迭代对象)
tags.update(['redis', 'mysql'])
tags.update('go') # 会拆分为 'g' 和 'o'
print(tags) # {'python', 'django', 'flask', 'fastapi', 'redis', 'mysql', 'g', 'o'}
# 3. remove() - 删除元素(不存在会报错)
tags.remove('g')
# tags.remove('java') # ❌ KeyError: 'java'
# 4. discard() - 删除元素(不存在不报错)✅ 推荐
tags.discard('o')
tags.discard('java') # 不会报错
# 5. pop() - 随机删除并返回一个元素
removed_tag = tags.pop()
print(f"删除的标签: {removed_tag}")
# 6. clear() - 清空集合
tags.clear()
print(tags) # set()
集合判断方法
python# 子集与超集判断
basic_features = {'login', 'logout'}
premium_features = {'login', 'logout', 'export', 'api'}
# 1. issubset() - 判断是否为子集
print(basic_features.issubset(premium_features)) # True
print(basic_features <= premium_features) # True(等价写法)
# 2. issuperset() - 判断是否为超集
print(premium_features.issuperset(basic_features)) # True
print(premium_features >= basic_features) # True
# 3. isdisjoint() - 判断是否无交集
free_features = {'view', 'search'}
print(free_features.isdisjoint(premium_features)) # True(无共同元素)
# 实战:权限校验
def check_permission(user_permissions, required_permissions):
"""检查用户是否拥有所需的所有权限"""
return required_permissions.issubset(user_permissions)
user_perms = {'read', 'write', 'delete'}
required_perms = {'read', 'write'}
if check_permission(user_perms, required_perms):
print("权限验证通过!")
else:
print("权限不足!")
💡 无序特性的深入理解
为什么集合是无序的?
python# 演示:集合的无序性
numbers = {5, 2, 8, 1, 9, 3}
print(numbers) # 可能输出:{1, 2, 3, 5, 8, 9}(看起来有序,但不保证)
# 多次创建同样的集合,顺序可能不同
for _ in range(3):
s = set([5, 2, 8, 1, 9, 3])
print(list(s)) # 每次输出顺序可能不同
无序性的影响
python# ❌ 错误示例:尝试使用索引访问
fruits = {'apple', 'banana', 'orange'}
# print(fruits[0]) # TypeError: 'set' object is not subscriptable
# ✅ 正确做法:遍历集合
for fruit in fruits:
print(fruit)
# 如果需要有序,转换为列表并排序
sorted_fruits = sorted(fruits)
print(sorted_fruits) # ['apple', 'banana', 'orange']
🎮 实战案例:上位机数据采集场景
pythonclass DataCollector:
"""模拟上位机数据采集器"""
def __init__(self):
self.collected_sensors = set() # 已采集的传感器ID
self.error_sensors = set() # 故障传感器ID
def collect_data(self, sensor_id):
"""采集单个传感器数据"""
self.collected_sensors.add(sensor_id)
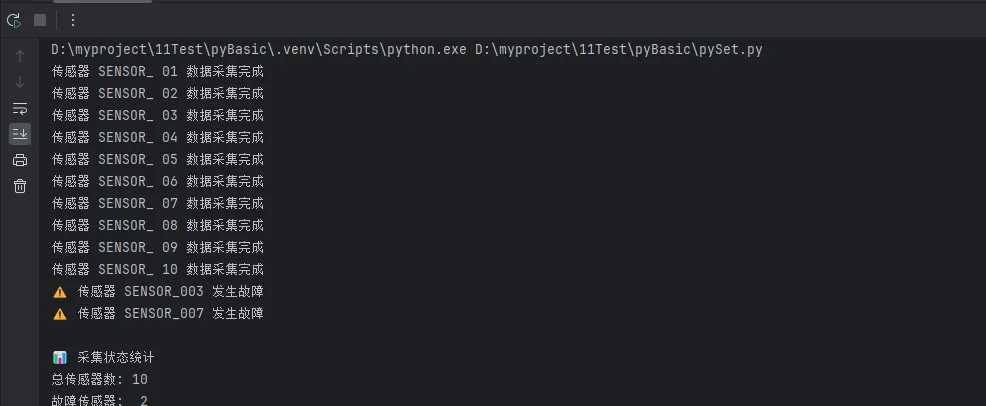
print(f"传感器 {sensor_id} 数据采集完成")
def report_error(self, sensor_id):
"""报告传感器故障"""
self.error_sensors.add(sensor_id)
print(f"⚠️ 传感器 {sensor_id} 发生故障")
def get_healthy_sensors(self):
"""获取正常工作的传感器"""
return self.collected_sensors - self.error_sensors
def get_status(self):
"""获取采集状态"""
total = len(self.collected_sensors)
errors = len(self.error_sensors)
healthy = len(self.get_healthy_sensors())
print(f"\n📊 采集状态统计")
print(f"总传感器数: {total}")
print(f"故障传感器: {errors}")
print(f"正常传感器: {healthy}")
print(f"正常率: {healthy/total*100:.1f}%")
# 使用示例
collector = DataCollector()
# 模拟数据采集
for sensor_id in range(1, 11):
collector.collect_data(f"SENSOR_{sensor_id: 03d}")
# 模拟故障上报
collector.report_error("SENSOR_003")
collector.report_error("SENSOR_007")
# 查看状态
collector.get_status()
输出结果:
⚡ 性能对比:集合 vs 列表
pythonimport time
# 准备测试数据
large_list = list(range(10000))
large_set = set(range(10000))
search_targets = [999, 5000, 9999]
# 列表查找性能测试
start = time.time()
for target in search_targets * 10000:
if target in large_list:
pass
list_time = time.time() - start
# 集合查找性能测试
start = time.time()
for target in search_targets * 10000:
if target in large_set:
pass
set_time = time.time() - start
print(f"列表查找耗时: {list_time:.4f}秒")
print(f"集合查找耗时: {set_time:.4f}秒")
print(f"集合速度提升: {list_time/set_time:.1f}倍")
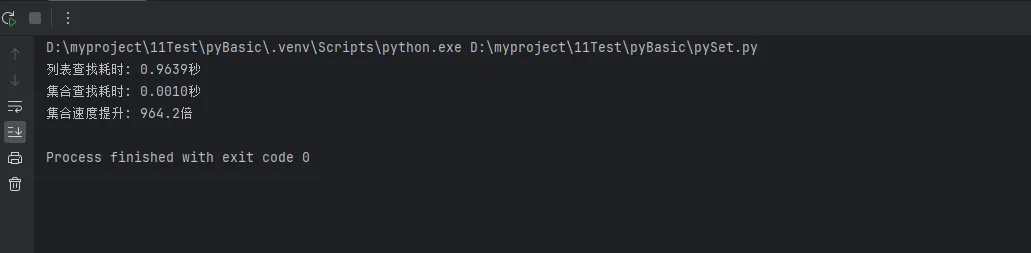
性能结论:
- 成员检测:集合 O(1) vs 列表 O(n) → 集合快100+倍
- 去重操作:
set(list)比循环判断快数十倍 - 集合运算:内置优化,远快于手动实现
🔥 最佳实践与注意事项
✅ 推荐做法
python# 1. 使用集合进行成员检测
allowed_users = {'admin', 'user1', 'user2'}
if current_user in allowed_users: # ✅ 快速
grant_access()
# 2. 快速去重
unique_items = list(set(items)) # ✅ 简洁高效
# 3. 使用集合运算简化逻辑
common_tags = set1 & set2 # ✅ 清晰易读
# 4. 批量添加使用update
tags.update(['tag1', 'tag2', 'tag3']) # ✅ 高效
❌ 避免做法
python# 1. 不要用集合存储可变对象
# bad_set = {[1, 2], {3, 4}} # ❌ TypeError
# 2. 不要依赖集合的顺序
# first_item = list(my_set)[0] # ❌ 不可预测
# 3. 不要频繁转换类型
for item in list(my_set): # ❌ 不必要的转换
process(item)
# 应该直接遍历
for item in my_set: # ✅ 正确
process(item)
🎯 选择指南
| 场景 | 推荐数据结构 | 原因 |
|---|---|---|
| 需要去重 | 集合(set) | 自动去重 |
| 需要保持顺序 | 列表(list) | 有序 |
| 频繁查找元素 | 集合(set) | O(1)查找 |
| 需要索引访问 | 列表(list) | 支持下标 |
| 集合运算 | 集合(set) | 内置运算符 |
| 允许重复 | 列表(list) | 可重复 |
🎓 总结与进阶
核心要点回顾
- 集合的本质:基于哈希表的无序不重复容器,提供O(1)时间复杂度的成员检测
- 四大集合运算:
- 并集(|):合并数据
- 交集(&):找共同元素
- 差集(-):找独有元素
- 对称差(^):找不共同元素
- 无序特性:不能依赖元素顺序,不支持索引访问,需要有序时转换为列表
实用技巧总结
- 数据去重首选
set(),比手动循环快数十倍 - 权限校验、标签匹配等场景优先使用集合运算
- 大数据量成员检测必用集合,性能提升百倍以上
- Windows应用开发中处理配置项、日志分析时灵活运用集合
延伸学习建议
- frozenset:不可变集合,可作为字典的键或集合的元素
- collections模块:Counter(计数器)、defaultdict等高级容器
- 算法应用:利用集合优化搜索算法、图论问题
掌握Python集合操作,不仅能让你的代码更简洁高效,更能在数据处理、上位机开发、算法优化等实际项目中游刃有余。从今天开始,把集合加入你的Python开发工具箱,让代码性能再上一个台阶!
💬 你在项目中是如何使用集合的?欢迎在评论区分享你的经验!
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录