
Press Ctrl+ and K to search
目录
在Windows环境下进行Python开发时,我们经常需要与SqlServer数据库打交道。无论是企业级应用还是上位机开发,数据的插入和更新都是核心功能。然而,很多开发者在使用pyodbc时会遇到各种问题:连接不稳定、插入效率低下、批量操作报错等。
本文将从实战角度出发,详细解析如何使用pyodbc高效地完成SqlServer数据库的插入与更新操作。我们不仅会解决基础的CRUD问题,还会分享性能优化和错误处理的编程技巧,让你的数据操作更加稳定高效。
🔍 问题分析
常见痛点梳理
在实际Python开发项目中,使用pyodbc操作SqlServer时经常遇到以下问题:
- 连接配置复杂:驱动选择、连接字符串配置容易出错
- 性能瓶颈:逐条插入效率低,大批量数据处理缓慢
- 异常处理不当:数据库连接中断、SQL语法错误处理不完善
- 数据类型转换:Python与SqlServer数据类型映射问题
技术选型考量
为什么选择pyodbc?
- 微软官方推荐的Python数据库连接方案
- 支持所有主流SqlServer版本
- 在Windows环境下性能优异
- 与其他Python数据处理库兼容性好
💡 解决方案设计
🏗️ 整体架构思路
我们将构建一个实用性强的数据库操作类,包含以下核心功能:
- 智能连接管理
- 批量插入优化
- 事务控制
- 异常处理机制
📦 环境准备
首先确保安装必要的依赖:
Python# 安装pyodbc
pip install pyodbc
# 查看可用的SqlServer驱动
import pyodbc
print(pyodbc.drivers())
🚀 代码实战
🔗 数据库连接管理
构建一个稳定的连接管理器是关键第一步:
Pythonimport pyodbc
import logging
from contextlib import contextmanager
class SqlServerManager:
def __init__(self, server, database, username=None, password=None, trusted=True):
"""
初始化数据库连接参数
:param server: 服务器地址
:param database: 数据库名称
:param username: 用户名(Windows认证时可选)
:param password: 密码(Windows认证时可选)
:param trusted: 是否使用Windows认证
"""
self.server = server
self.database = database
self.username = username
self.password = password
self.trusted = trusted
# 配置日志
logging.basicConfig(level=logging.INFO)
self.logger = logging.getLogger(__name__)
def _get_connection_string(self):
driver = "ODBC Driver 18 for SQL Server"
if self.trusted:
conn_str = (
f"DRIVER={{{driver}}};"
f"SERVER={self.server};"
f"DATABASE={self.database};"
f"Trusted_Connection=yes;"
f"TrustServerCertificate=yes;"
f"Encrypt=no;"
)
else:
conn_str = (
f"DRIVER={{{driver}}};"
f"SERVER={self.server};"
f"DATABASE={self.database};"
f"UID={self.username};"
f"PWD={self.password};"
f"TrustServerCertificate=yes;"
f"Encrypt=no;"
)
return conn_str
@contextmanager
def get_connection(self):
"""获取数据库连接(上下文管理器)"""
conn = None
try:
conn_str = self._get_connection_string()
conn = pyodbc.connect(conn_str, timeout=30)
conn.autocommit = False # 关闭自动提交,便于事务控制
self.logger.info("数据库连接成功")
yield conn
except pyodbc.Error as e:
self.logger.error(f"数据库连接失败: {e}")
raise
finally:
if conn:
conn.close()
self.logger.info("数据库连接已关闭")
# 示例用法
if __name__ == "__main__":
server = "127.0.0.1"
database = "dbtest"
username = "sa" # 如果使用Windows认证,可以设置为None
password = "123" # 如果使用Windows认证,可以设置为None
sql_manager = SqlServerManager(server, database, username, password, trusted=False)
with sql_manager.get_connection() as conn:
cursor = conn.cursor()
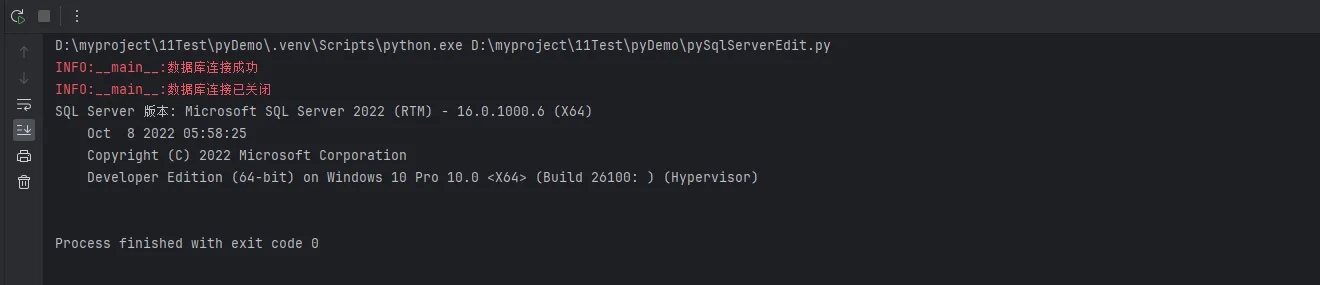
cursor.execute("SELECT @@VERSION")
row = cursor.fetchone()
print(f"SQL Server 版本: {row[0]}")
cursor.close()
📥 高效数据插入
实现单条和批量插入功能:
Pythonimport pyodbc
import logging
from contextlib import contextmanager
class SqlServerManager:
def __init__(self, server, database, username=None, password=None, trusted=True):
"""
初始化数据库连接参数
:param server: 服务器地址
:param database: 数据库名称
:param username: 用户名(Windows认证时可选)
:param password: 密码(Windows认证时可选)
:param trusted: 是否使用Windows认证
"""
self.server = server
self.database = database
self.username = username
self.password = password
self.trusted = trusted
# 配置日志
logging.basicConfig(level=logging.INFO)
self.logger = logging.getLogger(__name__)
def _get_connection_string(self):
driver = "ODBC Driver 18 for SQL Server"
if self.trusted:
conn_str = (
f"DRIVER={{{driver}}};"
f"SERVER={self.server};"
f"DATABASE={self.database};"
f"Trusted_Connection=yes;"
f"TrustServerCertificate=yes;"
f"Encrypt=no;"
)
else:
conn_str = (
f"DRIVER={{{driver}}};"
f"SERVER={self.server};"
f"DATABASE={self.database};"
f"UID={self.username};"
f"PWD={self.password};"
f"TrustServerCertificate=yes;"
f"Encrypt=no;"
)
return conn_str
@contextmanager
def get_connection(self):
"""获取数据库连接(上下文管理器)"""
conn = None
try:
conn_str = self._get_connection_string()
conn = pyodbc.connect(conn_str, timeout=30)
conn.autocommit = False # 关闭自动提交,便于事务控制
self.logger.info("数据库连接成功")
yield conn
except pyodbc.Error as e:
self.logger.error(f"数据库连接失败: {e}")
raise
finally:
if conn:
conn.close()
self.logger.info("数据库连接已关闭")
def insert_single_record(self, table_name, data_dict):
"""
插入单条记录
:param table_name: 表名
:param data_dict: 数据字典,键为列名,值为数据
:return: 是否插入成功
"""
try:
with self.get_connection() as conn:
cursor = conn.cursor()
# 构建SQL语句
columns = list(data_dict.keys())
placeholders = ['?' for _ in columns]
sql = f"""
INSERT INTO {table_name} ({', '.join(columns)})
VALUES ({', '.join(placeholders)})
"""
values = list(data_dict.values())
cursor.execute(sql, values)
conn.commit()
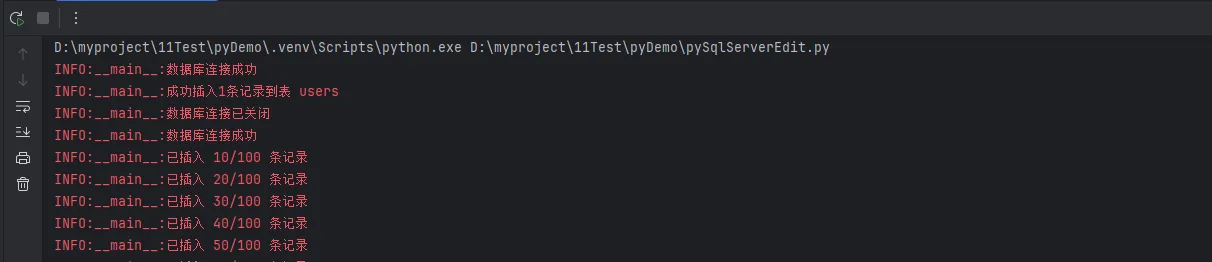
self.logger.info(f"成功插入1条记录到表 {table_name}")
return True
except Exception as e:
self.logger.error(f"插入记录失败: {e}")
return False
def batch_insert(self, table_name, data_list, batch_size=1000):
"""
批量插入记录(高性能版本)
:param table_name: 表名
:param data_list: 数据列表,每个元素为字典
:param batch_size: 批次大小
:return: 成功插入的记录数
"""
if not data_list:
return 0
try:
with self.get_connection() as conn:
cursor = conn.cursor()
# 获取列名(使用第一条记录的键)
columns = list(data_list[0].keys())
placeholders = ['?' for _ in columns]
sql = f"""
INSERT INTO {table_name} ({', '.join(columns)})
VALUES ({', '.join(placeholders)})
"""
total_inserted = 0
# 分批处理
for i in range(0, len(data_list), batch_size):
batch_data = data_list[i:i + batch_size]
# 准备批量数据
batch_values = []
for record in batch_data:
values = [record.get(col) for col in columns]
batch_values.append(values)
# 执行批量插入
cursor.executemany(sql, batch_values)
conn.commit()
total_inserted += len(batch_data)
self.logger.info(f"已插入 {total_inserted}/{len(data_list)} 条记录")
self.logger.info(f"批量插入完成,共插入 {total_inserted} 条记录")
return total_inserted
except Exception as e:
self.logger.error(f"批量插入失败: {e}")
if 'conn' in locals():
conn.rollback()
return 0
# Example usage
if __name__ == "__main__":
server = "127.0.0.1"
database = "dbtest"
username = "sa" # 如果使用Windows认证,可以设置为None
password = "123" # 如果使用Windows认证,可以设置为None
sql_manager = SqlServerManager(server, database, username, password, trusted=False)
data = {'id': 10001, 'name': '张三'}
sql_manager.insert_single_record('users', data)
# 批量插入
data_list = [{'id': 10002 + i, 'name': f'value{i}'} for i in range(100)]
sql_manager.batch_insert('users', data_list, batch_size=10)
🔄 数据更新操作
实现灵活的数据更新功能:
Pythondef update_record(self, table_name, update_data, condition_dict):
"""
更新记录
:param table_name: 表名
:param update_data: 要更新的数据字典
:param condition_dict: 更新条件字典
:return: 影响的记录数
"""
try:
with self.get_connection() as conn:
cursor = conn.cursor()
# 构建UPDATE语句
set_clauses = [f"{col} = ?" for col in update_data.keys()]
where_clauses = [f"{col} = ?" for col in condition_dict.keys()]
sql = f"""
UPDATE {table_name}
SET {', '.join(set_clauses)}
WHERE {' AND '.join(where_clauses)}
"""
# 准备参数值
values = list(update_data.values()) + list(condition_dict.values())
cursor.execute(sql, values)
affected_rows = cursor.rowcount
conn.commit()
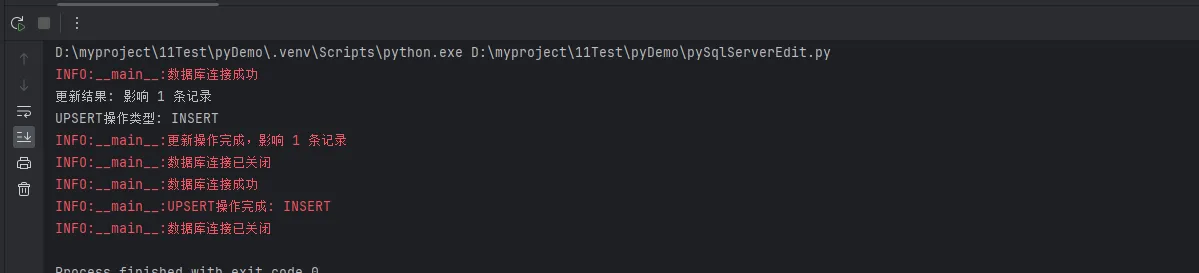
self.logger.info(f"更新操作完成,影响 {affected_rows} 条记录")
return affected_rows
except Exception as e:
self.logger.error(f"更新记录失败: {e}")
return 0
def upsert_record(self, table_name, data_dict, key_columns):
"""
插入或更新记录(如果存在则更新,否则插入)
:param table_name: 表名
:param data_dict: 数据字典
:param key_columns: 用于判断记录是否存在的关键列
:return: 操作类型('INSERT' 或 'UPDATE')
"""
try:
with self.get_connection() as conn:
cursor = conn.cursor()
# 检查记录是否存在
where_clauses = [f"{col} = ?" for col in key_columns]
check_sql = f"""
SELECT COUNT(*) FROM {table_name}
WHERE {' AND '.join(where_clauses)}
"""
key_values = [data_dict[col] for col in key_columns]
cursor.execute(check_sql, key_values)
exists = cursor.fetchone()[0] > 0
if exists:
# 记录存在,执行更新
update_data = {k: v for k, v in data_dict.items() if k not in key_columns}
condition_data = {k: data_dict[k] for k in key_columns}
set_clauses = [f"{col} = ?" for col in update_data.keys()]
where_clauses = [f"{col} = ?" for col in condition_data.keys()]
sql = f"""
UPDATE {table_name}
SET {', '.join(set_clauses)}
WHERE {' AND '.join(where_clauses)}
"""
values = list(update_data.values()) + list(condition_data.values())
cursor.execute(sql, values)
operation = 'UPDATE'
else:
# 记录不存在,执行插入
columns = list(data_dict.keys())
placeholders = ['?' for _ in columns]
sql = f"""
INSERT INTO {table_name} ({', '.join(columns)})
VALUES ({', '.join(placeholders)})
"""
values = list(data_dict.values())
cursor.execute(sql, values)
operation = 'INSERT'
conn.commit()
self.logger.info(f"UPSERT操作完成: {operation}")
return operation
except Exception as e:
self.logger.error(f"UPSERT操作失败: {e}")
return None
🔥 性能优化技巧
针对大数据量操作的优化方案:
Pythondef bulk_insert_optimized(self, table_name, data_list, batch_size=5000):
"""
优化版批量插入(使用参数化查询 + 事务控制)
:param table_name: 表名
:param data_list: 数据列表
:param batch_size: 批次大小(建议5000-10000)
:return: 插入结果统计
"""
if not data_list:
return {"success": 0, "failed": 0, "total": 0}
result = {"success": 0, "failed": 0, "total": len(data_list)}
try:
with self.get_connection() as conn:
cursor = conn.cursor()
# 设置连接参数优化性能
cursor.execute("SET NOCOUNT ON") # 减少网络流量
columns = list(data_list[0].keys())
placeholders = ['?' for _ in columns]
sql = f"""
INSERT INTO {table_name} ({', '.join(columns)})
VALUES ({', '.join(placeholders)})
"""
# 分批处理,每批使用一个事务
for i in range(0, len(data_list), batch_size):
batch_data = data_list[i:i + batch_size]
try:
# 开始事务
cursor.execute("BEGIN TRANSACTION")
# 准备批量数据
batch_values = []
for record in batch_data:
values = [record.get(col) for col in columns]
batch_values.append(values)
# 快速批量插入
cursor.fast_executemany = True # 启用快速模式
cursor.executemany(sql, batch_values)
# 提交事务
cursor.execute("COMMIT TRANSACTION")
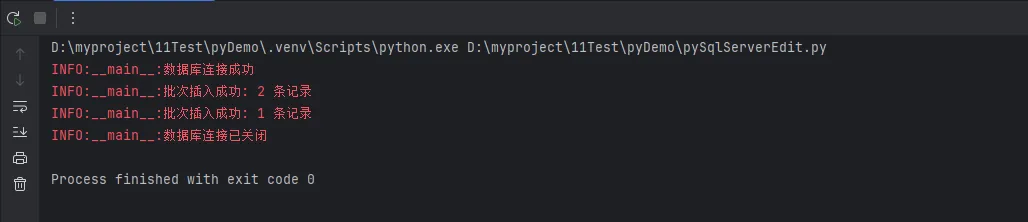
result["success"] += len(batch_data)
self.logger.info(f"批次插入成功: {len(batch_data)} 条记录")
except Exception as batch_error:
# 回滚当前批次
cursor.execute("ROLLBACK TRANSACTION")
result["failed"] += len(batch_data)
self.logger.error(f"批次插入失败: {batch_error}")
return result
except Exception as e:
self.logger.error(f"批量插入优化版失败: {e}")
return {"success": 0, "failed": len(data_list), "total": len(data_list)}
🎯 核心要点总结
通过本文的实战分享,我们掌握了Python pyodbc操作SqlServer的完整解决方案。三个关键要点需要重点记住:
- 连接管理是基础:使用上下文管理器确保连接的正确关闭,配置合适的超时时间和驱动版本,这是稳定性的保证。
- 批量操作是王道:单条插入适合小量数据,批量操作配合事务控制才能应对企业级应用的性能需求,建议批次大小控制在5000-10000条。
- 异常处理要完善:数据库操作充满不确定性,完善的日志记录和异常处理机制能让你的上位机开发项目更加健壮可靠。
这套解决方案已在多个生产环境中验证,无论你是Python开发新手还是有经验的工程师,都能直接应用到实际项目中。记住,好的数据库操作不仅仅是能跑起来,更要考虑性能、稳定性和可维护性。
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录