
Press Ctrl+ and K to search
目录
在日常的Python开发中,特别是上位机开发和数据处理场景下,我们经常需要处理XML格式的配置文件、数据交换文件或API响应。很多开发者在面对XML处理时往往感到头疼,不知道该选择哪个库,更不知道如何高效地解析和生成XML文档。
本文将通过实战案例,带你彻底掌握Python内置的ElementTree模块,从基础的XML解析到复杂的文档操作,让你在XML处理方面游刃有余。无论你是初学者还是有一定经验的开发者,都能从中获得实用的编程技巧和最佳实践。
🎯 为什么选择ElementTree?
在Python的XML处理库中,ElementTree有着独特的优势:
✅ 内置优势
- 零依赖:Python标准库内置,无需额外安装
- 轻量级:内存占用少,处理速度快
- 简单易用:API设计直观,学习成本低
✅ 实战优势
- 完整功能:支持XML解析、生成、修改等全流程操作
- 良好兼容性:支持XML 1.0标准,兼容性强
- 错误处理:提供详细的异常信息,便于调试
🔥 核心概念快速上手
📊 Element对象理解
Pythonimport xml.etree.ElementTree as ET
# Element是ElementTree的核心概念
# 每个XML标签都对应一个Element对象
root = ET.Element("root")
print(f"标签名: {root.tag}")
print(f"属性: {root.attrib}")
print(f"文本内容: {root.text}")
🎨 树形结构操作
Python# 创建树形结构
root = ET.Element("config")
database = ET.SubElement(root, "database")
ET.SubElement(database, "host").text = "localhost"
ET.SubElement(database, "port").text = "3306"
# 遍历子元素
for child in root:
print(f"子元素: {child.tag}")
💡 实战案例一:解析配置文件
🎯 场景描述
假设我们有一个系统配置文件config.xml,需要读取数据库连接信息:
XML<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<database type="mysql">
<host>192.168.1.100</host>
<port>3306</port>
<username>admin</username>
<password>123456</password>
</database>
<logging level="INFO">
<file>app.log</file>
<max_size>10MB</max_size>
</logging>
</configuration>
🛠️ 解决方案
Pythonimport xml.etree.ElementTree as ET
class ConfigParser:
def __init__(self, config_file):
"""初始化配置解析器"""
self.tree = ET.parse(config_file)
self.root = self.tree.getroot()
def get_database_config(self):
"""获取数据库配置信息"""
db_element = self.root.find('database')
if db_element is None:
raise ValueError("数据库配置不存在")
config = {
'type': db_element.get('type', 'mysql'),
'host': db_element.find('host').text,
'port': int(db_element.find('port').text),
'username': db_element.find('username').text,
'password': db_element.find('password').text
}
return config
def get_logging_config(self):
"""获取日志配置信息"""
log_element = self.root.find('logging')
return {
'level': log_element.get('level', 'INFO'),
'file': log_element.find('file').text,
'max_size': log_element.find('max_size').text
}
# 使用示例
try:
parser = ConfigParser('config.xml')
db_config = parser.get_database_config()
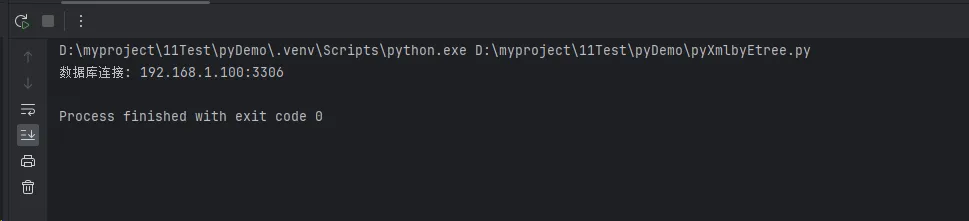
print(f"数据库连接: {db_config['host']}:{db_config['port']}")
except Exception as e:
print(f"配置解析错误: {e}")
🔧 进阶技巧:XPath式查找
Pythonimport xml.etree.ElementTree as ET
def find_nested_elements(root):
"""使用XPath式语法查找元素"""
# 查找所有数据库相关配置
elements = root.findall('.//database/*')
result = {}
for elem in elements:
result[elem.tag] = elem.text
return result
# 更灵活的查找方式
def get_config_value(path, default=None):
"""通过路径获取配置值"""
element = root.find(path)
return element.text if element is not None else default
# 使用示例
try:
tree = ET.parse("config.xml")
root = tree.getroot()
db_config = find_nested_elements(root)
print(f"数据库连接: {db_config['host']}:{db_config['port']}")
db_config_value = get_config_value("config.xml", "database")
print(f"数据库配置: {db_config_value}")
except Exception as e:
print(f"配置解析错误: {e}")

💡 实战案例二:生成XML报告
🎯 场景描述
在上位机开发中,我们经常需要生成XML格式的测试报告或数据导出文件。
🛠️ 解决方案
Pythonimport xml.etree.ElementTree as ET
from datetime import datetime
import os
class XMLReportGenerator:
def __init__(self):
"""初始化XML报告生成器"""
self.root = ET.Element("test_report")
self.root.set("generated_at", datetime.now().isoformat())
self.root.set("version", "1.0")
def add_test_suite(self, suite_name, description=""):
"""添加测试套件"""
suite = ET.SubElement(self.root, "test_suite")
suite.set("name", suite_name)
if description:
suite.set("description", description)
return suite
def add_test_case(self, suite, case_name, status, duration=0, error_msg=""):
"""添加测试用例"""
case = ET.SubElement(suite, "test_case")
case.set("name", case_name)
case.set("status", status)
case.set("duration", str(duration))
# 添加详细信息
if status == "PASS":
result = ET.SubElement(case, "result")
result.text = "测试通过"
elif status == "FAIL":
error = ET.SubElement(case, "error")
error.text = error_msg
return case
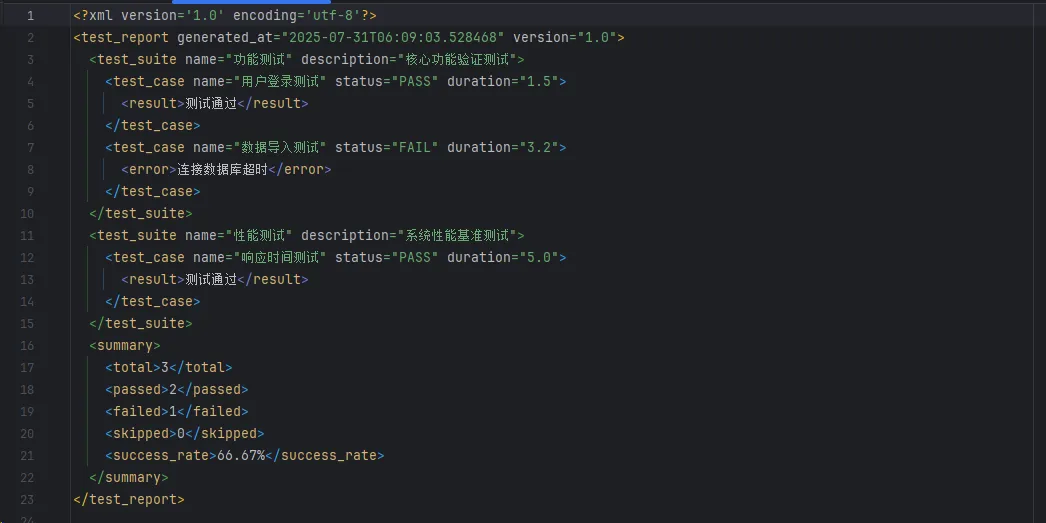
def add_summary(self, total_tests, passed, failed, skipped):
"""添加测试摘要"""
summary = ET.SubElement(self.root, "summary")
ET.SubElement(summary, "total").text = str(total_tests)
ET.SubElement(summary, "passed").text = str(passed)
ET.SubElement(summary, "failed").text = str(failed)
ET.SubElement(summary, "skipped").text = str(skipped)
# 计算成功率
success_rate = (passed / total_tests * 100) if total_tests > 0 else 0
ET.SubElement(summary, "success_rate").text = f"{success_rate:.2f}%"
def save_report(self, filename):
"""保存报告到文件"""
# 格式化XML输出
self._indent(self.root)
tree = ET.ElementTree(self.root)
tree.write(filename, encoding='utf-8', xml_declaration=True)
print(f"报告已保存到: {filename}")
def _indent(self, elem, level=0):
"""美化XML格式"""
i = "\n" + level * " "
if len(elem):
if not elem.text or not elem.text.strip():
elem.text = i + " "
if not elem.tail or not elem.tail.strip():
elem.tail = i
for elem in elem:
self._indent(elem, level + 1)
if not elem.tail or not elem.tail.strip():
elem.tail = i
else:
if level and (not elem.tail or not elem.tail.strip()):
elem.tail = i
# 使用示例
def generate_sample_report():
"""生成示例测试报告"""
generator = XMLReportGenerator()
# 添加功能测试套件
functional_suite = generator.add_test_suite(
"功能测试",
"核心功能验证测试"
)
generator.add_test_case(
functional_suite,
"用户登录测试",
"PASS",
duration=1.5
)
generator.add_test_case(
functional_suite,
"数据导入测试",
"FAIL",
duration=3.2,
error_msg="连接数据库超时"
)
# 添加性能测试套件
performance_suite = generator.add_test_suite(
"性能测试",
"系统性能基准测试"
)
generator.add_test_case(
performance_suite,
"响应时间测试",
"PASS",
duration=5.0
)
# 添加测试摘要
generator.add_summary(
total_tests=3,
passed=2,
failed=1,
skipped=0
)
# 保存报告
generator.save_report("test_report.xml")
# 执行生成
generate_sample_report()
💡 实战案例三:XML数据转换
🎯 场景描述
在数据集成项目中,经常需要将一种XML格式转换为另一种格式,或者将XML数据转换为其他格式。
🛠️ 解决方案
Pythonimport xml.etree.ElementTree as ET
import json
import csv
class XMLConverter:
def __init__(self, xml_file):
"""初始化XML转换器"""
self.tree = ET.parse(xml_file)
self.root = self.tree.getroot()
def xml_to_dict(self, element=None):
"""将XML转换为字典格式"""
if element is None:
element = self.root
result = {}
# 处理属性
if element.attrib:
result['@attributes'] = element.attrib
# 处理文本内容
if element.text and element.text.strip():
if len(element) == 0:
return element.text.strip()
result['#text'] = element.text.strip()
# 处理子元素
children = {}
for child in element:
child_data = self.xml_to_dict(child)
if child.tag in children:
# 如果标签已存在,转换为列表
if not isinstance(children[child.tag], list):
children[child.tag] = [children[child.tag]]
children[child.tag].append(child_data)
else:
children[child.tag] = child_data
result.update(children)
return result
def xml_to_json(self, output_file):
"""将XML转换为JSON格式"""
data = self.xml_to_dict()
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=2)
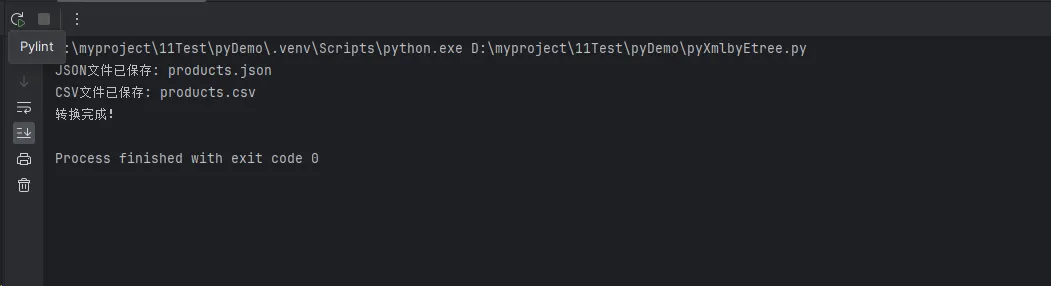
print(f"JSON文件已保存: {output_file}")
def xml_to_csv(self, output_file, xpath=".//*"):
"""将XML扁平化后转换为CSV格式"""
elements = self.root.findall(xpath)
if not elements:
print("没有找到匹配的元素")
return
# 收集所有可能的字段
fieldnames = set()
rows = []
for element in elements:
row = {'tag': element.tag}
# 添加属性
row.update(element.attrib)
# 添加文本内容
if element.text and element.text.strip():
row['text'] = element.text.strip()
# 添加子元素(仅文本内容)
for child in element:
if child.text and child.text.strip():
row[f"{child.tag}"] = child.text.strip()
rows.append(row)
fieldnames.update(row.keys())
# 写入CSV文件
with open(output_file, 'w', newline='', encoding='utf-8') as f:
writer = csv.DictWriter(f, fieldnames=list(fieldnames))
writer.writeheader()
writer.writerows(rows)
print(f"CSV文件已保存: {output_file}")
# 使用示例
def conversion_example():
"""数据转换示例"""
# 假设我们有一个产品信息XML文件
xml_content = '''<?xml version="1.0" encoding="UTF-8"?>
<products>
<product id="1" category="electronics">
<name>智能手机</name>
<price>2999</price>
<stock>50</stock>
</product>
<product id="2" category="electronics">
<name>平板电脑</name>
<price>1599</price>
<stock>30</stock>
</product>
</products>'''
# 保存示例XML文件
with open('products.xml', 'w', encoding='utf-8') as f:
f.write(xml_content)
# 执行转换
converter = XMLConverter('products.xml')
# 转换为JSON
converter.xml_to_json('products.json')
# 转换为CSV
converter.xml_to_csv('products.csv', './/product')
print("转换完成!")
conversion_example()
🔧 高级技巧与最佳实践
🚀 性能优化技巧
大文件处理:iterparse方法
Pythonimport xml.etree.ElementTree as ET
def process_large_xml(filename):
"""高效处理大型XML文件"""
context = ET.iterparse(filename, events=('start', 'end'))
context = iter(context)
event, root = next(context)
for event, elem in context:
if event == 'end' and elem.tag == 'record':
# 处理单个记录
process_record(elem)
# 清理内存,防止内存泄漏
elem.clear()
root.clear()
def process_record(record):
"""处理单个记录"""
print(f"处理记录: {record.get('id')}")
process_large_xml('user.xml')
命名空间处理
Pythonimport xml.etree.ElementTree as ET
def handle_namespaces():
"""处理带命名空间的XML"""
xml_with_ns = '''<?xml version="1.0"?>
<root xmlns:app="http://example.com/app">
<app:user id="1">
<app:name>张三</app:name>
</app:user>
</root>'''
root = ET.fromstring(xml_with_ns)
# 定义命名空间映射
namespaces = {'app': 'http://example.com/app'}
# 使用命名空间查找元素
user = root.find('app:user', namespaces)
if user is not None:
name = user.find('app:name', namespaces)
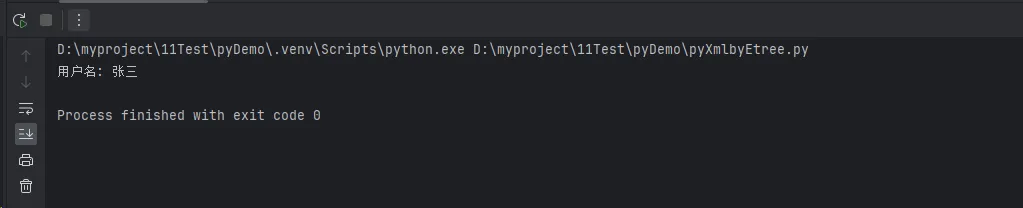
print(f"用户名: {name.text}")
handle_namespaces()
🛡️ 错误处理与验证
Pythonimport xml.etree.ElementTree as ET
def safe_xml_parse(xml_content):
"""安全的XML解析"""
try:
# 基本的XML格式验证
root = ET.fromstring(xml_content)
return root, None
except ET.ParseError as e:
return None, f"XML解析错误: {e}"
except Exception as e:
return None, f"未知错误: {e}"
def validate_xml_structure(root, required_elements):
"""验证XML结构"""
missing_elements = []
for element_path in required_elements:
if root.find(element_path) is None:
missing_elements.append(element_path)
if missing_elements:
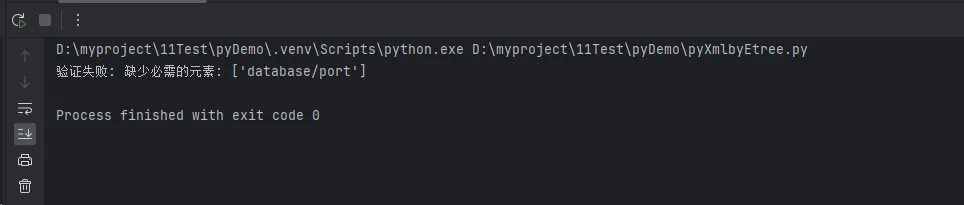
raise ValueError(f"缺少必需的元素: {missing_elements}")
return True
# 使用示例
xml_data = "<config><database><host>localhost</host></database></config>"
root, error = safe_xml_parse(xml_data)
if error:
print(error)
else:
try:
validate_xml_structure(root, ['database/host', 'database/port'])
print("XML结构验证通过")
except ValueError as e:
print(f"验证失败: {e}")
📝 代码组织最佳实践
Pythonimport xml.etree.ElementTree as ET
class XMLProcessor:
"""XML处理器基类"""
def __init__(self, encoding='utf-8'):
self.encoding = encoding
self.namespaces = {}
def register_namespace(self, prefix, uri):
"""注册命名空间"""
self.namespaces[prefix] = uri
ET.register_namespace(prefix, uri)
def create_element(self, tag, text=None, **attributes):
"""创建元素的便捷方法"""
elem = ET.Element(tag, **attributes)
if text:
elem.text = str(text)
return elem
def get_element(self, parent, tag, **attributes):
"""
从parent中查找符合tag及属性的第一个元素。
:param parent: 父元素,Element类型
:param tag: 标签名称,字符串
:param attributes: 标签属性键值对筛选,字典形式传入
:return: 第一个符合条件的Element对象,找不到返回None
"""
for elem in parent.iter(tag):
if all(elem.get(k) == v for k, v in attributes.items()):
return elem
return None
def pretty_print(self, element):
"""美化打印XML"""
from xml.dom import minidom
rough_string = ET.tostring(element, encoding='unicode')
reparsed = minidom.parseString(rough_string)
return reparsed.toprettyxml(indent=" ")
xmlprocessor = XMLProcessor()
# 创建根元素
root = xmlprocessor.create_element("root")
# 添加子元素
child1 = xmlprocessor.create_element("record", id="1")
child1.text = "张三"
root.append(child1)
child2 = xmlprocessor.create_element("record", id="2")
child2.text = "李四"
root.append(child2)
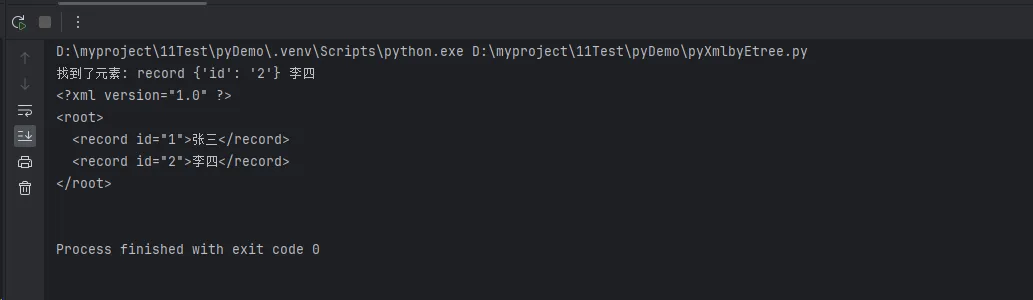
# 查找id="2"的record元素
found = xmlprocessor.get_element(root, "record", id="2")
if found is not None:
print("找到了元素:", found.tag, found.attrib, found.text)
else:
print("元素未找到")
# 打印整个xml
print(xmlprocessor.pretty_print(root))
🎯 总结与展望
通过本文的实战演练,我们深入掌握了Python ElementTree的核心功能和应用技巧。让我们回顾一下关键要点:
🔑 三个核心要点
- 灵活解析:掌握find、findall等方法,能够高效提取XML中的数据信息
- 动态生成:学会使用Element和SubElement创建复杂的XML文档结构
- 最佳实践:运用错误处理、性能优化和代码组织技巧,编写健壮的XML处理代码
🚀 实际应用价值
在上位机开发、数据集成、配置管理等场景下,ElementTree为我们提供了轻量级且功能完整的XML处理解决方案。无论是处理简单的配置文件,还是复杂的数据交换格式,都能够胜任。
掌握这些编程技巧,不仅能提升你的Python开发效率,更能让你在面对各种XML处理需求时游刃有余。继续实践这些代码示例,结合自己的项目需求,相信你会发现更多ElementTree的强大功能!
如果这篇文章对你有帮助,欢迎点赞分享!有任何问题也可以在评论区交流讨论。
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录