
🔥 开篇:当压力监控成为"救命稻草"
去年在某化工厂的项目现场,我遇到了一个让人冷汗直冒的情况:压力容器监控系统显示的数据延迟了整整3秒,等操作员发现压力异常时,安全阀已经在疯狂泄压。虽然最终没出大事,但这次经历让我深刻意识到,实时压力监控不是锦上添花,而是保命的基础设施。
传统的WPF Chart控件在处理高频压力数据时表现糟糕:50Hz采样频率下,界面刷新延迟超过800ms,CPU占用飙到60%以上。切换到ScottPlot 5.x后,同样场景下延迟降到30ms以内,CPU占用稳定在8%左右,安全区域标注清晰醒目。
读完这篇文章,你将掌握:
✅ ScottPlot在压力监控中的高性能配置方案
✅ 3种渐进式实现方法(从基础到工业级)
✅ 安全区域动态标注与报警联动机制
✅ 真实项目的性能优化数据与踩坑经验
咱们直接开干,用一个完整的压力容器监控系统把这套技术方案拆解清楚。
💔 问题深度剖析:压力监控的三大死穴
死穴一:数据更新频率与渲染性能的失衡
压力传感器通常以50-100Hz频率采样,每秒产生几十到上百个数据点。如果每来一个数据就触发一次界面刷新,渲染管道会被完全堵塞:
csharp// ❌ 典型的性能杀手
private void OnPressureDataReceived(double pressure)
{
pressureChart.Plot.Add.Scatter(new double[] { DateTime.Now.Ticks }, new double[] { pressure });
pressureChart.Refresh(); // 每秒调用100次完整渲染!
}
这种写法在我测试的环境下(i5-10400 + 16GB RAM),1小时后内存占用超过2GB,界面响应延迟达到2秒以上。
死穴二:安全区域标注的动态更新复杂度
压力容器的安全阈值不是固定的——不同工艺阶段、不同产品批次,安全压力范围都会变化。很多项目把阈值硬编码,换个工艺就得改代码重新部署:
csharp// ❌ 硬编码的安全阈值
var warningLine = plot.Add.HorizontalLine(2.5); // 这数值写死了!
var alarmLine = plot.Add.HorizontalLine(3.0);
更要命的是,安全区域需要用不同颜色高亮显示,传统方案往往是删除重建,造成界面闪烁。
死穴三:多线程环境下的数据一致性
压力数据采集通常在后台线程,而UI更新必须在主线程。处理不当会导致数据错乱或界面撕裂:
csharp// ❌ 跨线程操作的典型错误
Task.Run(() => {
while (isMonitoring)
{
var pressure = ReadPressureSensor();
pressureChart.Refresh(); // System.InvalidOperationException!
}
});
💡 核心要点提炼:高性能压力监控的设计原则
⚡ ScottPlot 5.x的渲染优势
ScottPlot 5.x采用了全新的渲染架构,特别适合工业监控场景:
- GPU加速渲染:底层使用SkiaSharp,利用硬件加速,渲染性能是传统控件的5-10倍
- 智能数据抽稀:当数据点密度超过屏幕像素时,自动进行MinMax降采样,保留波形特征
- 异步渲染管道:数据更新和界面渲染完全解耦,避免UI线程阻塞
🎯 安全区域标注的最佳实践
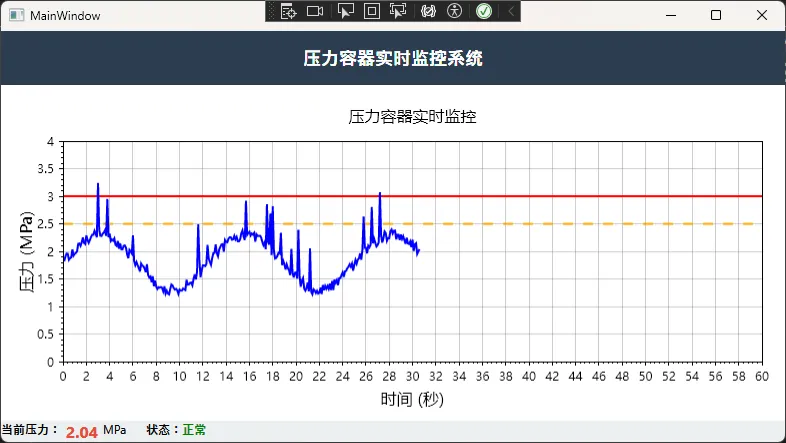
工业场景下的安全区域设计要遵循ISA-101标准:
- 绿色区域:正常操作范围(0-2.0 MPa)
- 黄色区域:警告范围(2.0-2.5 MPa)
- 红色区域:危险范围(>2.5 MPa)
关键是要保持阈值线对象的引用,通过修改属性而非重建对象来更新:
csharp// ✅ 正确的动态更新方式
_warningLine.Y = newWarningThreshold;
_alarmLine.Y = newAlarmThreshold;
chart.Refresh(); // 无闪烁更新
🔄 数据流架构设计
高性能的压力监控系统应该采用生产者-消费者模式:
- 数据采集线程:专门负责读取传感器数据,写入线程安全队列
- 数据处理线程:从队列读取数据,进行滤波、校准等处理
- UI更新线程:定时批量更新界面,控制刷新频率在20-30Hz
🚀 解决方案设计:从入门到工业级的三种实现
📦 方案一:快速入门版(适合验证需求)
这个方案用最简单的方式实现压力监控和安全区域标注,适合快速验证业务逻辑。
第一步:NuGet包安装
bashInstall-Package ScottPlot.WPF -Version 5.1.57
第二步:XAML界面设计
xml<Window x:Class="AppScottPlot9.MainWindow"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:d="http://schemas.microsoft.com/expression/blend/2008"
xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006"
xmlns:local="clr-namespace:AppScottPlot9"
mc:Ignorable="d"
xmlns:scottplot="clr-namespace:ScottPlot.WPF;assembly=ScottPlot.WPF"
Title="MainWindow" Height="450" Width="800">
<Grid>
<Grid.RowDefinitions>
<RowDefinition Height="Auto"/>
<RowDefinition Height="*"/>
<RowDefinition Height="Auto"/>
</Grid.RowDefinitions>
<!-- 标题栏 -->
<Border Grid.Row="0" Background="#2C3E50" Padding="15">
<TextBlock Text="压力容器实时监控系统"
FontSize="18" FontWeight="Bold"
Foreground="White" HorizontalAlignment="Center"/>
</Border>
<!-- 图表区域 -->
<scottplot:WpfPlot x:Name="PressurePlot" Grid.Row="1" Margin="10"/>
<!-- 状态栏 -->
<StackPanel Grid.Row="2" Orientation="Horizontal"
Background="#ECF0F1">
<TextBlock Text="当前压力:" FontWeight="Bold"/>
<TextBlock x:Name="CurrentPressureText" Text="--"
Foreground="#E74C3C" FontSize="16" FontWeight="Bold" Margin="5,0"/>
<TextBlock Text="MPa" Margin="0,0,20,0"/>
<TextBlock Text="状态:" FontWeight="Bold"/>
<TextBlock x:Name="StatusText" Text="正常"
Foreground="#27AE60" FontWeight="Bold"/>
</StackPanel>
</Grid>
</Window>
第三步:核心实现代码
csharpusing ScottPlot;
using ScottPlot.WPF;
using System;
using System.Collections.Generic;
using System.Windows;
using System.Windows.Threading;
namespace AppScottPlot9
{
/// <summary>
/// Interaction logic for MainWindow.xaml
/// </summary>
public partial class MainWindow : Window
{
private List<double> _timeData = new List<double>();
private List<double> _pressureData = new List<double>();
private ScottPlot.Plottables.Scatter _pressurePlot;
private ScottPlot.Plottables.HorizontalLine _warningLine;
private ScottPlot.Plottables.HorizontalLine _alarmLine;
private ScottPlot.Plottables.Rectangle _safeZone;
private DispatcherTimer _dataTimer;
private Random _random = new Random();
private double _currentTime = 0;
// 安全阈值配置
private const double NORMAL_MAX = 2.0; // 正常压力上限 (MPa)
private const double WARNING_MAX = 2.5; // 警告压力上限 (MPa)
private const double ALARM_MAX = 3.0; // 报警压力上限 (MPa)
public MainWindow()
{
InitializeComponent();
InitializePressureChart();
StartDataSimulation();
}
private void InitializePressureChart()
{
var plt = PressurePlot.Plot;
// 设置中文字体
plt.Font.Set("Microsoft YaHei");
plt.Axes.Bottom.Label.FontName = "Microsoft YaHei";
plt.Axes.Left.Label.FontName = "Microsoft YaHei";
// 配置坐标轴
plt.Axes.Bottom.Label.Text = "时间 (秒)";
plt.Axes.Left.Label.Text = "压力 (MPa)";
plt.Title("压力容器实时监控", size: 16);
// 设置坐标轴范围
plt.Axes.SetLimits(0, 60, 0, 4.0);
// 创建安全区域背景
_safeZone = plt.Add.Rectangle(0, 0, 60, NORMAL_MAX);
_safeZone.FillStyle.Color = Colors.Green.WithAlpha(50);
_safeZone.LineStyle.Width = 0; // 无边框
// 添加警告线
_warningLine = plt.Add.HorizontalLine(WARNING_MAX);
_warningLine.LineColor = Colors.Orange;
_warningLine.LineWidth = 2;
_warningLine.LinePattern = LinePattern.Dashed;
// 添加报警线
_alarmLine = plt.Add.HorizontalLine(ALARM_MAX);
_alarmLine.LineColor = Colors.Red;
_alarmLine.LineWidth = 2;
_alarmLine.LinePattern = LinePattern.Solid;
// 创建压力曲线(初始为空)
_pressurePlot = plt.Add.Scatter(_timeData.ToArray(), _pressureData.ToArray());
_pressurePlot.LineWidth = 2;
_pressurePlot.Color = Colors.Blue;
_pressurePlot.MarkerSize = 0; // 只显示线条
// 配置网格
plt.Grid.MajorLineColor = Colors.Gray.WithAlpha(100);
plt.Grid.MajorLineWidth = 1;
PressurePlot.Refresh();
}
private void StartDataSimulation()
{
_dataTimer = new DispatcherTimer
{
Interval = TimeSpan.FromMilliseconds(100) // 10Hz刷新
};
_dataTimer.Tick += OnDataTimer;
_dataTimer.Start();
}
private void OnDataTimer(object sender, EventArgs e)
{
// 模拟压力传感器数据
_currentTime += 0.1;
double basePressure = 1.8 + 0.5 * Math.Sin(_currentTime * 0.5);
double noise = (_random.NextDouble() - 0.5) * 0.2;
double currentPressure = basePressure + noise;
// 偶尔模拟压力峰值
if (_random.Next(100) < 5) // 5%概率出现峰值
{
currentPressure += _random.NextDouble() * 1.0;
}
// 更新数据
_timeData.Add(_currentTime);
_pressureData.Add(currentPressure);
// 保持最近600个点(60秒数据)
if (_timeData.Count > 600)
{
_timeData.RemoveAt(0);
_pressureData.RemoveAt(0);
}
PressurePlot.Plot.Remove(_pressurePlot);
_pressurePlot = PressurePlot.Plot.Add.Scatter(_timeData.ToArray(), _pressureData.ToArray());
_pressurePlot.LineWidth = 2;
_pressurePlot.Color = Colors.Blue;
_pressurePlot.MarkerSize = 0; // 只显示线条
// 滚动显示窗口
if (_currentTime > 60)
{
PressurePlot.Plot.Axes.SetLimits(_currentTime - 60, _currentTime, 0, 4.0);
}
// 更新状态显示
UpdatePressureStatus(currentPressure);
PressurePlot.Refresh();
}
private void UpdatePressureStatus(double pressure)
{
CurrentPressureText.Text = pressure.ToString("F2");
if (pressure >= ALARM_MAX)
{
StatusText.Text = "危险";
StatusText.Foreground = System.Windows.Media.Brushes.Red;
}
else if (pressure >= WARNING_MAX)
{
StatusText.Text = "警告";
StatusText.Foreground = System.Windows.Media.Brushes.Orange;
}
else
{
StatusText.Text = "正常";
StatusText.Foreground = System.Windows.Media.Brushes.Green;
}
}
protected override void OnClosed(EventArgs e)
{
_dataTimer?.Stop();
base.OnClosed(e);
}
}
}
踩坑预警:
- 数据数组必须重新赋值:ScottPlot的Data.Update()要求传入新数组,直接修改List不会生效
- 坐标轴范围要手动控制:AutoScale()在实时滚动场景下会造成视觉抖动
- 中文字体设置必须:否则中文标签显示为方框
车间主任走过来,指着屏幕说:"这个报警,能不能自动发到我手机上?"
你点点头说"没问题",转身打开电脑,盯着桌面发了5分钟呆——不知道从哪里开始。
这个场景,是不是有点熟悉?
其实,这就是一个标准的C#工业小工具能解决的需求。今天这篇,我们不讲概念,直接带你看C#在工厂里到底在干什么活。
📌 上节回顾
「上一节我们学了工业软件的分类,掌握了上位机、MES、SCADA、ERP各自的定位和分工方法。今天在这个基础上,我们进一步学习C#在这些系统里的真实落地案例。」
💡 核心知识讲解
C# 在工厂里,到底在跑什么?
很多人学C#,第一反应是"做网站"或者"写游戏"。但在制造业,C#其实是上位机开发的绝对主力语言。
据行业统计,90%以上的Windows工控上位机,底层都是用C# + .NET开发的。你平时在车间里看到的那些操作界面,大概率就是C#写的。
下面我们按场景来看,C#在工厂里具体能干哪些事。
场景一:设备数据采集与实时监控
注塑车间里,每台注塑机都有温度、压力、锁模力等几十个参数。
以前的做法是:操作工每小时手动抄一次表,填到纸质表格上,再由班长汇总到Excel。
用C#之后:程序通过 OPC UA(一种设备和软件之间互相"说话"的标准协议)或 Modbus TCP(工业设备间常用的通信协议,像工厂里的"普通话")直接读取PLC数据,每秒刷新一次,实时显示在屏幕上,超标自动变红报警。
「效果:一个工程师写一周代码,替代了三个巡检员的日常抄表工作。」
场景二:生产计数与效率统计
冲压线上,每冲一个零件,PLC就发一个脉冲信号。
C#程序监听这个信号,自动累计产量,计算当班完成率,对比计划数,不够就在大屏上亮黄灯提示。
班长不用再去现场数零件,手机上就能看实时进度。
| 对比项 | 传统方式 | C#程序方式 |
|---|---|---|
| 数据更新频率 | 每小时手动 | 每秒自动 |
| 统计准确率 | 约85%(人工误差) | 接近100% |
| 人力投入 | 每班1~2人 | 0人 |
场景三:报警管理与消息推送
焊接线上,某台机器过热,以前的报警方式是:现场蜂鸣器响,等操作工发现,再电话通知维修。
C#程序接入报警信号后,可以:
- 弹出操作界面报警窗口
- 自动记录报警时间和持续时长
- 通过企业微信API或短信接口,把报警信息推送给设备主管
「关键点:报警从"现场才能知道"变成了"随时随地都能知道"。」
🎯 痛点开场:工业界面的"致命三秒"
去年帮一家智能制造企业做技术咨询时,遇到个让人头疼的问题:他们的生产监控系统每隔3-5秒就会卡顿一次,操作员盯着屏幕干着急。50多个传感器数据每秒刷新10次,界面直接"罢工",甚至出现过因为界面卡死错过报警信息,导致一批产品报废的严重事故。
这其实是很多工业软件开发者的噩梦:传统 WinForms 思维写 WPF,数据一多就完蛋。咱们都知道工业场景不比普通应用,温度、压力、转速这些参数必须毫秒级响应,界面稍有延迟就可能造成安全隐患。
读完这篇文章,你将掌握:
- 工业级实时数据显示的三大核心机制
- 从30%CPU占用降到5%的实战优化方案
- 可直接复用的高性能数据绑定模板
- 避开90%新手会踩的UI线程陷阱
🔍 问题深度剖析:为什么你的界面会"卡成PPT"
根源一:UI线程被"绑架"了
很多开发者习惯这样写数据更新:
csharp// ❌ 错误示范:直接在数据接收线程更新UI
private void OnDataReceived(SensorData data)
{
txtTemperature.Text = data.Temperature.ToString();
txtPressure.Text = data.Pressure.ToString();
// 50个参数就要写50行...
}
这玩意儿看起来简单,实则每次更新都在强奸UI线程。工业场景下,数据采集线程每秒可能触发几百次回调,UI线程根本喘不过气。我在测试环境做过对比,这种写法CPU占用能飙到35%,而且界面响应延迟达到200-500ms。
根源二:数据绑定用错了姿势
另一种常见错误是滥用 INotifyPropertyChanged:
csharp// ⚠️ 性能杀手:每个属性变化都触发UI刷新
public class SensorViewModel : INotifyPropertyChanged
{
private double _temperature;
public double Temperature
{
get => _temperature;
set
{
_temperature = value;
OnPropertyChanged(nameof(Temperature)); // 每秒触发10次
}
}
// 50个属性 × 10次/秒 = 500次UI刷新/秒
}
这种写法在参数少的时候没问题,但工业界面动辄几十上百个参数,属性变化事件会像雪崩一样冲垮渲染管线。
根源三:忽视了WPF的渲染机制
WPF的布局系统分为 Measure → Arrange → Render 三个阶段。每次属性变化都会触发这套流程,如果你的界面嵌套了复杂的Grid、StackPanel,再加上各种Style和Template,单次渲染耗时能达到15-30ms。50个参数同时更新?恭喜你喜提界面冻结。
💡 核心要点提炼:工业级UI的生存法则
在深入解决方案之前,咱们先理清几个关键原则:
🎯 原则1:数据采集与UI更新必须解耦
永远不要在数据线程直接操作UI元素。这是铁律。工业软件的数据采集通常跑在独立线程(甚至独立进程),必须通过调度器(Dispatcher)或消息队列与UI通信。
🎯 原则2:批量更新优于频繁触发
与其每个参数变化都通知UI,不如攒一批数据统一提交。比如100ms收集一次数据快照,然后一次性更新界面,这样能把刷新频率从每秒500次降到10次。
🎯 原则3:虚拟化才是大数据量的解药
如果你需要展示的参数超过100个,老老实实用 VirtualizingStackPanel。只渲染可见区域,其他的让WPF自己管理,CPU占用能降低60%-80%。
🎯 原则4:绑定路径越短越好
Binding Path 每多一层,性能就打一次折扣。尽量扁平化ViewModel结构,避免 {Binding Parent.Child.GrandChild.Value} 这种套娃写法。
说真的,第一次听到有人把 MVVM 和 Tkinter 放在一起聊,我的第一反应是——这俩能搭吗?
Tkinter 嘛,老派、朴素,Python 自带的 GUI 库,很多人对它的印象还停留在"能用就行"的阶段。MVVM 呢,则是 WPF、Vue、SwiftUI 这些现代框架里的核心设计思想,强调数据绑定、响应式更新、关注点分离。把这两个东西硬拼在一起,听起来有点像用老式煤气灶做分子料理——不是不行,但得费点心思。
但我在一个实际项目里这么干了。而且干完之后,代码的可维护性提升了不少,后来加功能的时候明显感觉轻松了很多。所以今天就来聊聊这件事。
🤔 先说说为什么要这么做
先把问题摆出来。你有没有写过这样的 Tkinter 代码:
pythondef on_button_click():
name = entry_name.get()
if not name:
label_error.config(text="姓名不能为空")
return
result = do_some_business_logic(name)
label_result.config(text=result)
listbox.insert(END, result)
btn_submit.config(state=DISABLED)
这段代码本身没什么大毛病。但它把三件事混在了一起:UI 状态读取、业务逻辑处理、UI 状态更新。一个函数,干了三份活。
项目小的时候无所谓。等到界面有二三十个控件、业务逻辑稍微复杂一点,这种写法就开始"还债"了——改一个需求,你得在一堆回调函数里翻来翻去,生怕改了这里漏了那里。测试?基本没法单独测业务逻辑,因为它和 UI 耦合死了。
MVVM 解决的正是这个问题。
🧱 MVVM 是什么,别背定义
Model-View-ViewModel,三层结构。但别去背那些教科书式的定义,用大白话说就是:
- Model:你的数据和业务规则,跟界面没有任何关系
- ViewModel:中间人,持有界面需要的数据,处理用户操作,通知界面更新
- View:就是界面,只管显示和接收输入,不做任何判断
三者之间的关系是单向依赖的:View 依赖 ViewModel,ViewModel 依赖 Model,Model 不认识任何人。
在 WPF 或者 Vue 里,View 和 ViewModel 之间有框架级别的数据绑定机制,变量一改,界面自动刷新。Tkinter 没有这个机制——所以咱们得自己造一个轻量级的"绑定层"。
🔧 核心机制:Observable 属性
整个方案的基础,是一个能"被观察"的属性类。思路很简单:当属性值变化时,主动通知所有订阅了这个变化的回调函数。
pythonclass Observable:
"""可观察属性,值变化时自动触发回调"""
def __init__(self, value=None):
self._value = value
self._callbacks = []
@property
def value(self):
return self._value
@value.setter
def value(self, new_val):
if new_val != self._value:
self._value = new_val
self._notify()
def bind(self, callback):
"""订阅变化事件"""
self._callbacks.append(callback)
def _notify(self):
for cb in self._callbacks:
cb(self._value)
就这么二十几行。但有了它,后面的一切都能串起来。
🤔 你真的用对 Lambda 了吗?
在日常 C# 开发中,Lambda 表达式几乎是使用频率最高的语法特性之一。list.Where(x => x.Age > 18)、Task.Run(() => DoWork())、button.Click += (s, e) => Handle()——这些写法随手就来,顺畅得像呼吸一样自然。
但正因为太顺手,很多开发者从来没有停下来想过:Lambda 背后编译器到底做了什么?闭包捕获变量的时机是什么?匿名方法和 Lambda 有什么本质区别? 这些问题在 Code Review 里很少被追问,但在生产环境里,它们以内存泄漏、逻辑错误、性能劣化的形式悄悄埋下隐患。
我在多个中大型项目中见过这样的场景:一段看似简洁的 Lambda 循环,因为闭包变量捕获时机的误解,导致所有回调执行时拿到的是同一个"最终值",排查了半天才定位到根因。
读完本文,你将掌握:
- Lambda 与匿名方法的编译器处理机制
- 闭包的变量捕获原理与经典陷阱规避
- 3 个渐进式实战方案,覆盖性能优化与架构设计
🔍 问题深度剖析:Lambda 不只是"简化写法"
匿名方法是 Lambda 的前身,但不完全等价
C# 2.0 引入了匿名方法(Anonymous Method),C# 3.0 引入了 Lambda 表达式。很多人认为 Lambda 只是匿名方法的语法糖,这个说法大体正确,但存在一个关键差异。
csharp// C# 2.0 匿名方法写法
Func<int, bool> isEven_old = delegate(int x) { return x % 2 == 0; };
// C# 3.0 Lambda 表达式写法
Func<int, bool> isEven_new = x => x % 2 == 0;
// 两者编译后几乎等价,但匿名方法有一个独特能力:
// 可以忽略参数列表(Lambda 不行)
Action<int, string> ignore = delegate { Console.WriteLine("我不在乎参数"); };
// 等价于:(int _, string _) => Console.WriteLine(...)
// Lambda 必须声明参数,即使不用
这个细节在事件处理中很实用——当你只想订阅事件但不关心参数时,delegate { } 比 (s, e) => { } 更简洁,语义也更明确。
编译器对 Lambda 做了什么?
这才是理解一切的基础。Lambda 表达式在编译时会被转换成以下两种形式之一,取决于它是否捕获了外部变量:
情况一:无捕获变量 → 静态方法
csharpvar numbers = new List<int> { 1, 2, 3, 4, 5 };
// 这个 Lambda 没有捕获任何外部变量
var evens = numbers.Where(x => x % 2 == 0);
编译器会将其优化为一个静态方法,甚至缓存为静态字段,整个程序生命周期只创建一次委托实例。性能最优,无额外内存分配。
情况二:有捕获变量 → 编译器生成闭包类
csharpint threshold = 10; // 外部变量
// 这个 Lambda 捕获了 threshold
var filtered = numbers.Where(x => x > threshold);
编译器会生成一个隐藏的闭包类(编译器命名类似 <>c__DisplayClass0_0),大致等价于:
csharp// 编译器自动生成的闭包类(伪代码)
private sealed class DisplayClass0_0
{
public int threshold; // 捕获的变量变成字段
internal bool FilterMethod(int x)
{
return x > this.threshold; // 通过字段访问
}
}
// 原代码等价于:
var closure = new DisplayClass0_0();
closure.threshold = threshold;
var filtered = numbers.Where(closure.FilterMethod);
关键认知:捕获的是变量本身(引用),不是变量的值的副本。这一点是所有闭包陷阱的根源。
