在Python开发中,字符串格式化是最常用的操作之一。无论是Windows桌面应用开发、上位机数据处理,还是日志输出,我们都离不开字符串格式化。面对Python提供的三种主流格式化方式——f-strings、str.format()和百分号格式化(%),很多开发者会困惑:到底该用哪种?性能差距有多大?在实际项目中如何选择?
本文将从实战角度出发,通过详细的代码示例和性能测试,帮你彻底掌握Python字符串格式化的精髓,让你在面对不同场景时能够做出最优选择。
🔍 三种格式化方式深度解析
💫 f-strings:Python 3.6+的现代化选择
f-strings(格式化字符串字面量)是Python 3.6引入的最新格式化语法,以其简洁和高效著称。
基础语法:
Pythonname = "张三"
age = 25
score = 95.678
# 基本用法
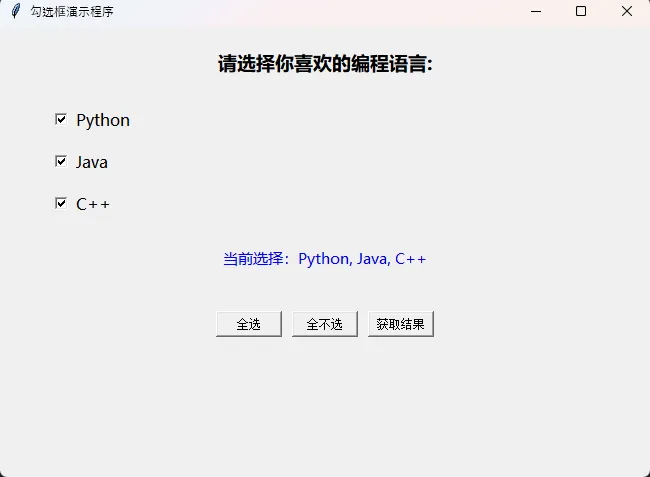
message = f"学员{name},年龄{age}岁,成绩{score}分"
print(message)
# 格式控制
formatted_score = f"成绩:{score:.2f}分" # 保留2位小数
print(formatted_score)
# 表达式计算
total_students = 100
pass_rate = f"及格率:{(score/100)*100:.1f}%"
print(pass_rate)
在Python GUI开发中,Tkinter作为Python标准库中最重要的图形界面工具包,几乎是每个Python开发者都会接触到的技术。然而,许多开发者在使用Tkinter时常常遇到一个尴尬的问题:界面丑陋、控件单调、用户体验差。
默认的Tkinter界面往往给人一种"上世纪90年代"的感觉,这让很多开发者望而却步,转向其他GUI框架。但实际上,通过掌握正确的控件属性配置和美化技巧,Tkinter完全可以创建出现代化、美观的专业级应用界面。
本文将从实战角度出发,详细介绍Tkinter常用控件的核心属性,并提供一系列经过验证的美化技巧,帮助你快速提升Python GUI应用的视觉效果和用户体验。
🔍 问题分析:为什么Tkinter界面总是很丑?
常见问题盘点
- 默认样式过时:灰色背景、单调边框、缺乏视觉层次
- 控件属性复杂:参数众多,不知如何合理配置
- 布局管理混乱:控件摆放不当,界面缺乏统一性
- 缺乏交互反馈:按钮、输入框等控件交互体验差
根本原因
Tkinter设计之初更注重功能性而非美观性,默认样式确实比较简陋。但通过深入了解控件属性和合理的配置策略,完全可以解决这些问题。
💡 解决方案:掌握核心控件属性体系
🎨 颜色属性系统
Tkinter中的颜色配置是美化的基础,主要包括以下属性:
Python# 基础颜色属性
bg='#f0f0f0' # 背景色 (background)
fg='#333333' # 前景色/文字颜色 (foreground)
activebackground='#e0e0e0' # 激活时背景色
activeforeground='#000000' # 激活时前景色
selectbackground='#0078d4' # 选中时背景色
selectforeground='white' # 选中时前景色
最佳实践:建立统一的色彩方案,避免使用过多颜色造成视觉混乱。
📏 尺寸与边距属性
Python# 尺寸控制
width=20 # 宽度(字符单位或像素)
height=2 # 高度(字符单位或像素)
# 内边距控制
padx=10 # 水平内边距
pady=5 # 垂直内边距
ipadx=5 # 内部水平填充
ipady=3 # 内部垂直填充
🖋️ 字体属性配置
Python# 字体设置
font=('微软雅黑', 12, 'normal') # (字体名称, 大小, 样式)
# 样式选项:'normal', 'bold', 'italic'
# 实用字体配置示例
FONT_TITLE = ('微软雅黑', 16, 'bold')
FONT_CONTENT = ('微软雅黑', 10, 'normal')
FONT_BUTTON = ('微软雅黑', 9, 'normal')
🖼️ 边框与外观属性
Pythonrelief='flat' # 边框样式:flat, raised, sunken, groove, ridge
borderwidth=1 # 边框宽度
highlightthickness=0 # 高亮边框厚度(去除焦点框)
🛠️ 代码实战:常用控件美化实例
🏷️ Label标签美化
Pythonimport tkinter as tk
from tkinter import ttk
# 创建主窗口
root = tk.Tk()
root.title("Tkinter控件美化示例")
root.geometry("600x400")
root.configure(bg='#f5f5f5')
# 标题标签 - 现代化设计
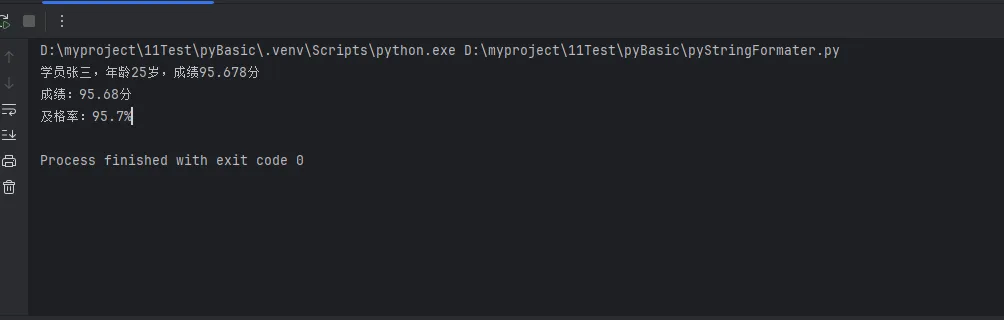
title_label = tk.Label(
root,
text="欢迎使用Python应用程序",
font=('微软雅黑', 20, 'bold'),
fg='#2c3e50',
bg='#f5f5f5',
pady=20
)
title_label.pack()
# 信息标签 - 卡片样式
info_frame = tk.Frame(root, bg='white', relief='solid', bd=1)
info_frame.pack(pady=10, padx=20, fill='x')
info_label = tk.Label(
info_frame,
text="这是一个美化后的信息提示框",
font=('微软雅黑', 12, 'normal'),
fg='#34495e',
bg='white',
pady=15,
padx=20
)
info_label.pack()
# 启动主循环
if __name__ == "__main__":
root.mainloop()
作为一名Python开发者,你是否曾经为编写繁琐的SQL语句而苦恼?是否在处理数据库连接、事务管理时感到头疼?SQLAlchemy作为Python生态中最强大的ORM框架,能够帮你彻底摆脱这些困扰。
本文将通过一个完整的用户管理系统实战案例,详细讲解如何在Windows环境下使用SQLAlchemy操作MySQL数据库。从环境搭建到高级应用,从基础CRUD到复杂查询,让你快速掌握SQLAlchemy的核心技能,提升Python开发效率。
无论你是初学者还是有经验的开发者,这篇文章都将为你的上位机开发和数据库操作提供实用的解决方案。
🔍 问题分析
在实际的Python开发中,我们经常遇到以下数据库操作难题:
传统方式的痛点:
- 手写SQL语句容易出错,维护困难
- 数据库连接管理复杂,容易出现连接泄露
- 不同数据库之间的SQL语法差异导致移植困难
- 数据类型转换和验证需要大量重复代码
SQLAlchemy的优势:
- 对象关系映射(ORM):将数据库表映射为Python类
- 数据库无关性:支持多种数据库,代码易于迁移
- 连接池管理:自动管理数据库连接,提高性能
- 强大的查询语法:提供直观的Python式查询方式
💡 解决方案
🛠️ 环境准备
首先,我们需要安装必要的依赖包:
Bashpip install sqlalchemy pip install pymysql pip install cryptography
🏗️ 项目结构搭建
创建一个清晰的项目结构:
Pythonsqlalchemy_demo/
├── config.py # 数据库配置
├── models.py # 数据模型定义
├── database.py # 数据库连接管理
├── operations.py # 数据库操作
└── main.py # 主程序入口
昨天有同事向我咨询了这个问题,我发现了一种新的方法来处理字符串的聚合与分割,你是否为了分割一个包含多个值的字符串字段而不得不编写复杂的循环代码?
作为数据库开发者,我们经常遇到这样的场景:
- 需要将员工的多个技能合并显示:
"Java,Python,SQL" - 要将订单的多个商品ID拆分成单独的记录进行处理
- 统计报表中需要动态拼接查询条件
如果你还在使用传统的游标循环或复杂的XML PATH方法,那你就OUT了!SQL Server为我们提供了两个强大的内置函数:STRING_AGG 和 STRING_SPLIT,它们能让这些操作变得异常简单和高效。
本文将通过实战案例,带你掌握这两个函数的精髓,让你的SQL代码更加优雅和高效!
🔥 STRING_AGG:多行变一行的艺术
💡 问题分析:传统聚合的痛点
在SQL Server 2017之前,我们要实现多行数据的字符串聚合,通常需要这样写:
SQL-- 老式写法:复杂且难理解
SELECT STUFF((
SELECT ',' + skill_name
FROM employee_skills e2
WHERE e2.employee_id = e1.employee_id
FOR XML PATH('')
), 1, 1, '') AS skills
FROM employees e1;
这种写法不仅代码冗长,性能也不够理想,这个写法在以前基本这第干了。
⚡ STRING_AGG:优雅的解决方案
基础语法:
SQLSTRING_AGG(expression, separator) [WITHIN GROUP (ORDER BY order_expression)]
🛠️ 实战案例1:员工技能聚合
SQL-- 创建测试数据
CREATE TABLE #employees (
employee_id INT,
employee_name NVARCHAR(50)
);
CREATE TABLE #employee_skills (
employee_id INT,
skill_name NVARCHAR(50),
skill_level INT
);
INSERT INTO #employees VALUES
(1, '张三'), (2, '李四'), (3, '王五');
INSERT INTO #employee_skills VALUES
(1, 'Java', 5), (1, 'Python', 4), (1, 'SQL', 5),
(2, 'C#', 4), (2, 'JavaScript', 3),
(3, 'Python', 5), (3, 'React', 4), (3, 'Node.js', 3);
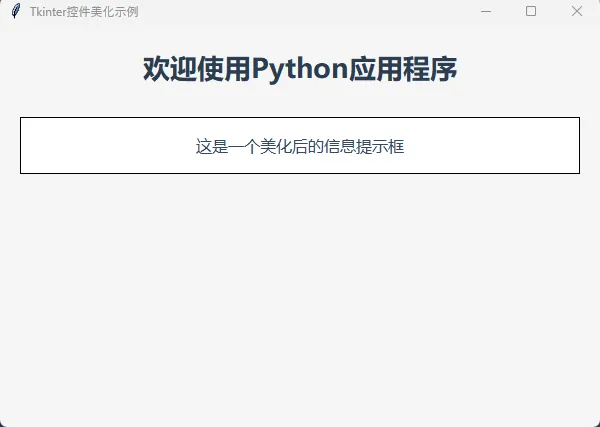
SQLSELECT
e.employee_name,
STRING_AGG(s.skill_name, ', ') AS skills,
STRING_AGG(s.skill_name, ', ') WITHIN GROUP (ORDER BY s.skill_level DESC) AS skills_by_level
FROM #employees e
LEFT JOIN #employee_skills s ON e.employee_id = s.employee_id
GROUP BY e.employee_id, e.employee_name;
在Python GUI开发中,用户交互是核心环节。你是否遇到过这样的困扰:需要让用户进行多项选择时不知道用什么组件?或者想实现单选功能却不知道如何让多个选项互斥?今天我们就来深入探讨Tkinter中两个重要的交互组件——Checkbutton(勾选框)和Radiobutton(单选框)。
本文将从实际应用场景出发,通过详细的代码示例和最佳实践,帮你完全掌握这两个组件的使用方法。无论你是Python初学者还是有一定经验的开发者,都能从中获得实用的开发技巧,让你的GUI应用更加专业和用户友好。
🔍 问题分析
应用场景对比
在实际项目开发中,我们经常需要处理两类选择问题:
多选场景(Checkbutton):
- 软件设置界面的功能开关
- 文件处理工具的选项配置
- 数据分析工具的筛选条件
单选场景(Radiobutton):
- 性别选择、级别选择
- 操作模式切换(如:手动/自动)
- 文件格式选择(如:CSV/Excel/JSON)
选择合适的组件不仅关乎用户体验,更影响程序的逻辑设计和数据处理方式。
💡 解决方案
🎯 核心设计思路
- 状态管理:使用
IntVar()或BooleanVar()管理组件状态 - 事件绑定:通过
command参数实现实时响应 - 数据收集:设计统一的数据获取和处理机制
🚀 代码实战
📋 Checkbutton(勾选框)实现
基础用法示例
Pythonimport tkinter as tk
from tkinter import ttk
class CheckboxDemo:
def __init__(self, root):
self.root = root
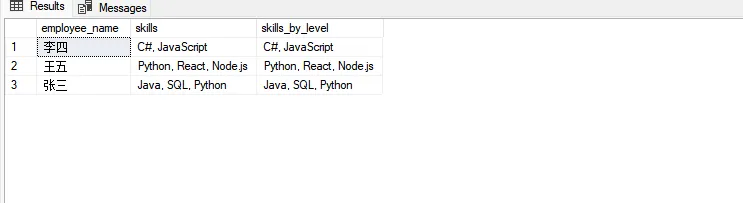
self.root.title("勾选框演示程序")
self.root.geometry("400x300")
# 创建变量存储勾选状态
self.var1 = tk.BooleanVar()
self.var2 = tk.BooleanVar()
self.var3 = tk.BooleanVar()
self.create_widgets()
def create_widgets(self):
# 主标题
title = tk.Label(self.root, text="请选择你喜欢的编程语言:",
font=("微软雅黑", 14, "bold"))
title.pack(pady=20)
# 创建勾选框
cb1 = tk.Checkbutton(self.root, text="Python",
variable=self.var1,
command=self.on_check_change,
font=("微软雅黑", 12))
cb1.pack(anchor='w', padx=50, pady=5)
cb2 = tk.Checkbutton(self.root, text="Java",
variable=self.var2,
command=self.on_check_change,
font=("微软雅黑", 12))
cb2.pack(anchor='w', padx=50, pady=5)
cb3 = tk.Checkbutton(self.root, text="C++",
variable=self.var3,
command=self.on_check_change,
font=("微软雅黑", 12))
cb3.pack(anchor='w', padx=50, pady=5)
# 结果显示区域
self.result_label = tk.Label(self.root, text="当前选择:无",
font=("微软雅黑", 11),
fg="blue")
self.result_label.pack(pady=20)
# 操作按钮
btn_frame = tk.Frame(self.root)
btn_frame.pack(pady=20)
tk.Button(btn_frame, text="全选",
command=self.select_all,
width=8).pack(side='left', padx=5)
tk.Button(btn_frame, text="全不选",
command=self.deselect_all,
width=8).pack(side='left', padx=5)
tk.Button(btn_frame, text="获取结果",
command=self.get_result,
width=8).pack(side='left', padx=5)
def on_check_change(self):
"""勾选状态变化时的回调函数"""
selected = []
if self.var1.get(): selected.append("Python")
if self.var2.get(): selected.append("Java")
if self.var3.get(): selected.append("C++")
if selected:
self.result_label.config(text=f"当前选择:{', '.join(selected)}")
else:
self.result_label.config(text="当前选择:无")
def select_all(self):
"""全选功能"""
self.var1.set(True)
self.var2.set(True)
self.var3.set(True)
self.on_check_change()
def deselect_all(self):
"""全不选功能"""
self.var1.set(False)
self.var2.set(False)
self.var3.set(False)
self.on_check_change()
def get_result(self):
"""获取最终结果"""
result = {
'Python': self.var1.get(),
'Java': self.var2.get(),
'C++': self.var3.get()
}
selected = [lang for lang, checked in result.items() if checked]
if selected:
tk.messagebox.showinfo("选择结果",
f"你选择了:{', '.join(selected)}")
else:
tk.messagebox.showwarning("提示", "请至少选择一项!")
if __name__ == "__main__":
root = tk.Tk()
app = CheckboxDemo(root)
root.mainloop()